6) 정보 추출
6-1) 텍스트 분석
- 단어의 품사가 중요하다.
1) 문장의 주제를 알아낼 수 있다.(명사)
2) 문서를 분류할 수 있다.(명사)
3) 감정분석을 알아낼 수 있다.(형용사)
6-1-1) 형태소/단어 분리 라이브러리 실행

시작하기전에 먼저 konlpy와 Twitter의 설치가 완료되어있어야한다.
konlpy: 한글 형태소/단어 분리를 위한 라이브러리
Twitter: 형태소/단어 분리에 도움을 주는 라이브러리
설치가 완료되었으면 import를 통해서 실행해주고 형태소/단어 분리를 할 객체를 변수에 지정해준다.
6-1-2) 형태소/단어 분리하기
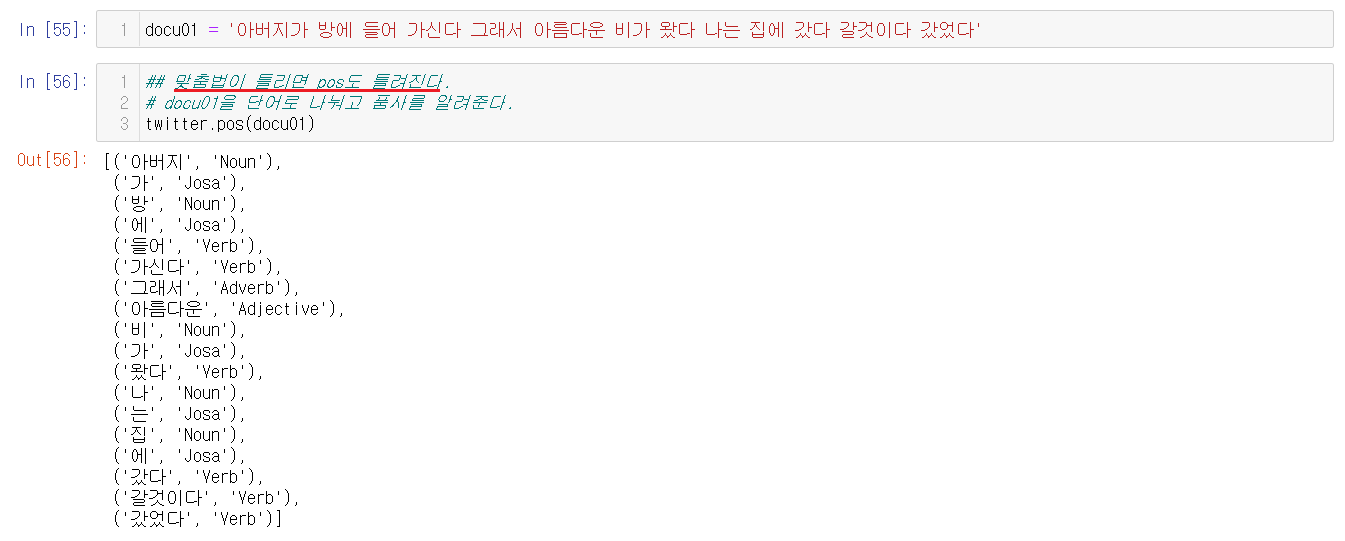
분리해볼 문장을 생성하고 pos()를 이용해서 형태소와 단어들을 분리할 수 있다. 분리할 문장의 맞춤법이 틀려지면 pos도 틀려지니 맞춤법에 유의해야한다.
6-1-3) 동사, 형용사 원형 만들기

분리한 동사와 형용사를 확인해보면,
갔다, 갈것이다, 갔었다 => 시제는 다르지만 같은 의미로 원형은 동일하다.
stem = True를 사용하면, 동사와 형용사들을 원형으로 변경할 수 있다.
갔다 -> 가다
갔었다 -> 가다
갈것이다 -> 갈아버린다는 의미로 생각해서 갈다로 변경되었다.
아름다운 -> 아름답다
이런식으로 변경되었다.
6-1-4) 단어와 품사를 구분하기
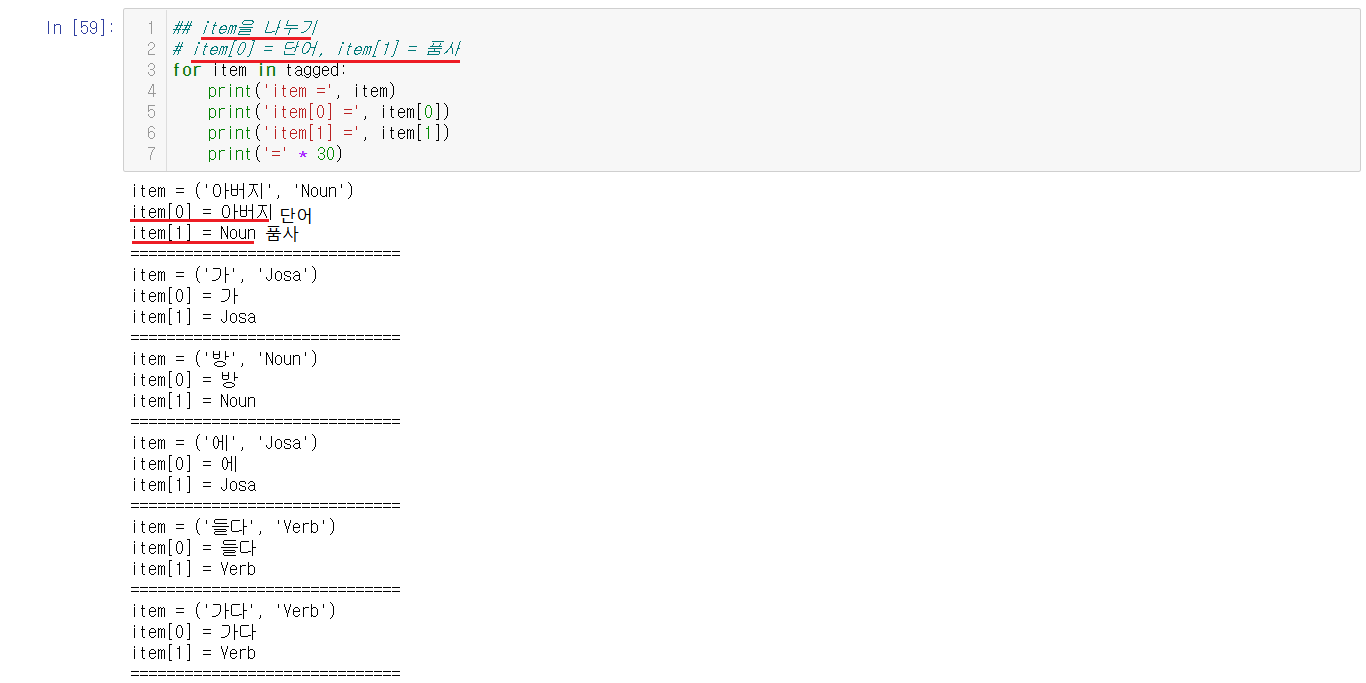
for문으로 돌려서 item으로 tagged를 하나씩 넣어주는데 아이템을 확인해보면 item[0] = 단어, item[1] = 품사인것을 확인할 수 있다.
6-1-5) 조건문으로 지정해서 출력하기
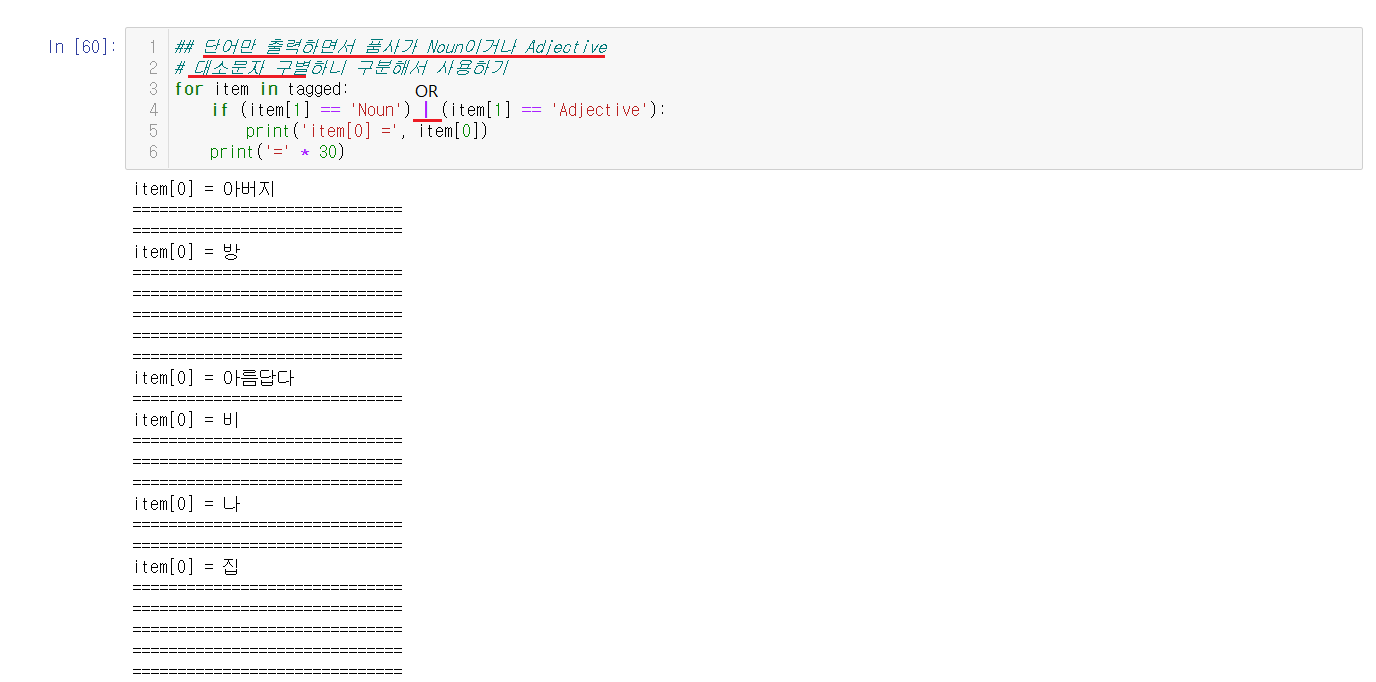
item안이 어떻게 구성되어있는지를 확인했으니, 조건문을 사용해서 원하는 데이터만을 출력할 수 있게되었다.
단어만 출력하며서, 품사가 Noun이거나 Adjective인 경우를 출력
if (item[1] == 'Noun') | (item[1] == 'Adjective'):
if조건문을 사용해서 지정해줄 수 있다.( | 의 의미는 OR이며, 조건 앞뒤로 괄호를 해주어야한다.)
※ 대소문자 구별하니 대소문자 구분에 유의한다.
6-2) 데이터 시각화하기
6-2-1) 한글 설정
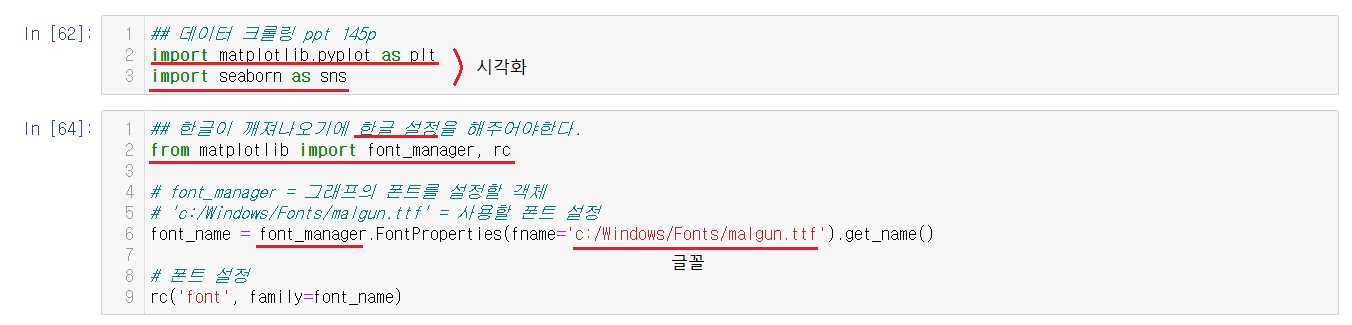
그냥 실행하면 한글이 깨지기에 먼저 한글 설정을 진행해주어야한다. 시각화 그래프에 사용할 폰트를 설정해주면 된다.
6-2-2) 랜덤

시각화하기전에 랜덤으로 숫자를 만드는 법에 대해서 알아보자면, 먼저 import random을 해주고 random.sample(랜덤하게 할 수, 선택할 수) 이런식으로 랜덤으로 돌리고 원하는만큼의 숫자를 뽑을 수 있다. 랜덤이기에 실행할 때마다 계속 변경되니 주의해야한다.
6-2-3) 랜덤 숫자를 DataFrame으로 변경하기
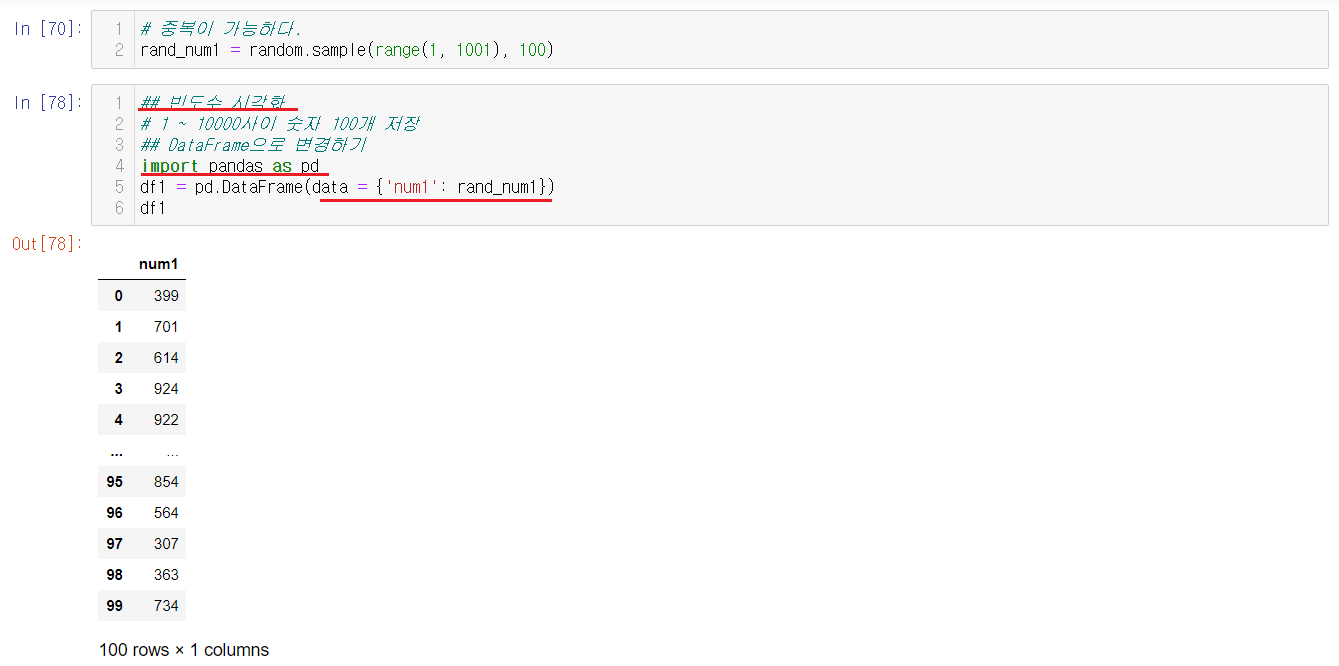
랜덤으로 1부터 1000까지의 숫자들을 랜덤으로 돌려서 100가지의 숫자들을 생성했다. 이 숫자들을 시각화하면서 시각화에대해서 알아볼 예정이다. 먼저 시각화하기전에 이 돌린 숫자들을 DataFrame안에 넣어준다.
6-2-4) 빈도수 확인
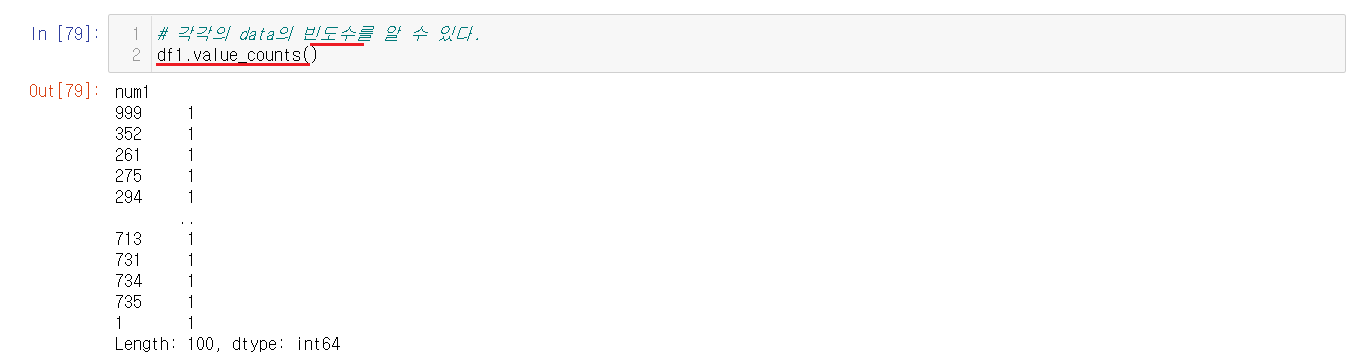
value_counts()를 통해서 숫자들의 값의 빈도수를 확인할 수 있다. 옆에 1의 숫자들은 숫자들이 등장한 값이라고 생각하면된다.
6-2-5) factorplot으로 빈도수 그래프 표현하기
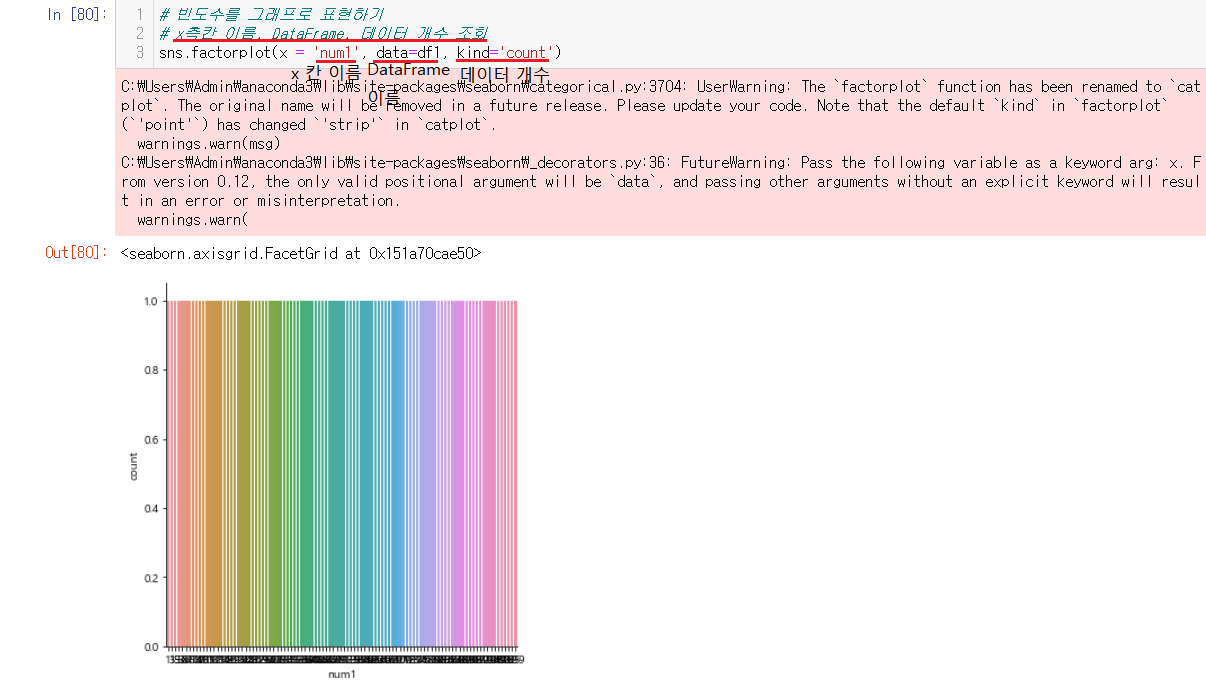
x측칸 이름, DataFrame, 데이터 개수 조회순으로 적어서 진행해주면 된다. 빈도수에 대한 그래프들이 나오는데 일정한 이유는 숫자들이 다 한번씩 나와서 일정하게 보이는 것이다. 하지만 너무 작어서 밑에 숫자들이 무엇을 나타내는지에 대해서 보기가 어렵다.
6-2-6) factorplot 그래프 사이즈 키우기
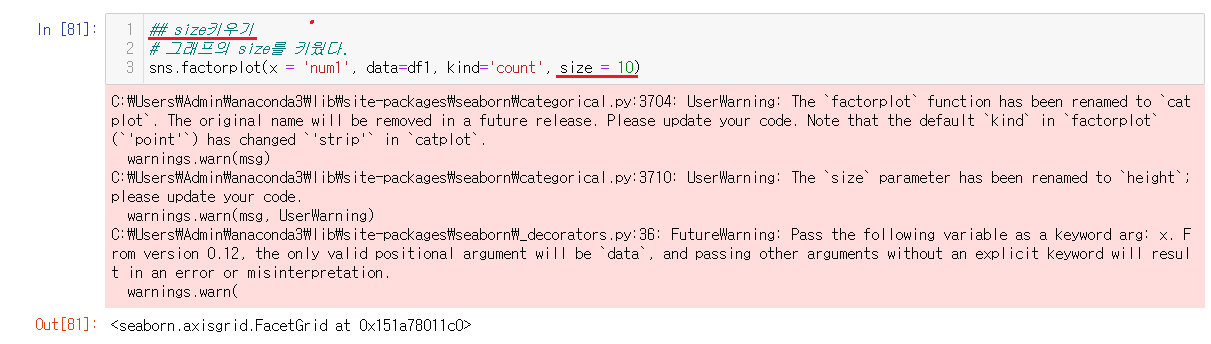
size = 사이즈지정
이런식으로 사이즈를 조정할 수 있다.
사이즈가 예전보다는 커진것을 확인할 수 있다. 사이즈를 조금 더 크게보고 싶다면 더블클릭으로 확인할 수 있다.
6-2-7) histplot 사용해보기
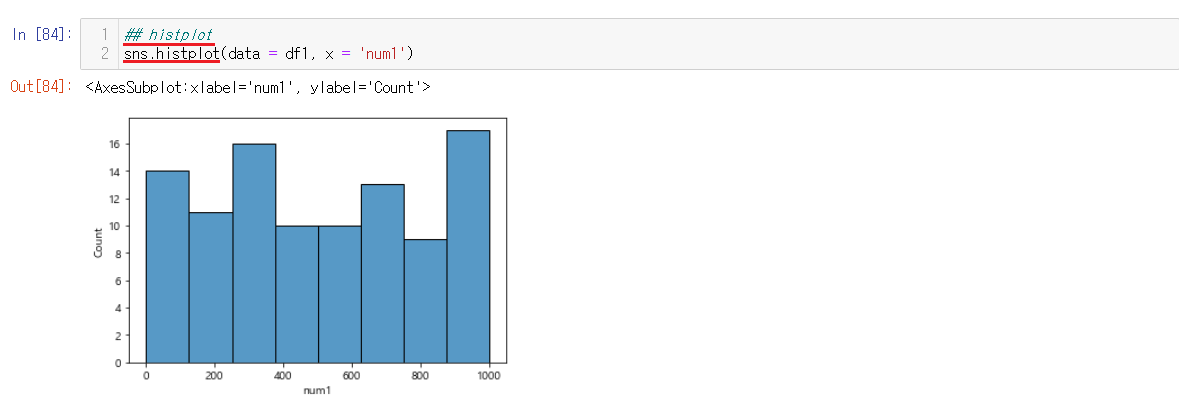
hitsplot으로 변경해서도 사용할 수 있다.
6-2-8) 범위 설정하기
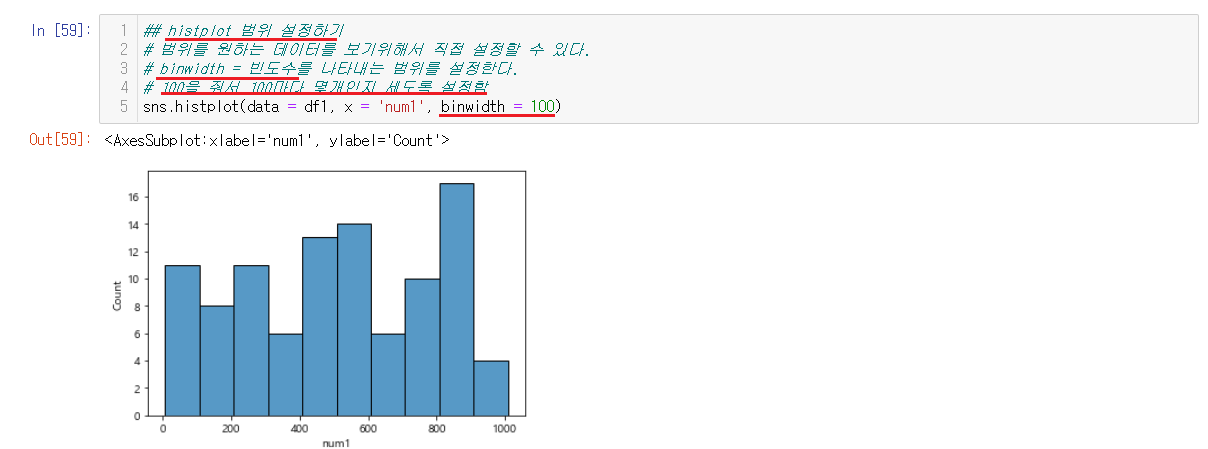
binwidth = 빈도수를 통해서 범위를 설정할 수 있다. 현재는 100으로 설정해서 100마다 몇개인지를 세도록 설정되어서 그래프고 100단위로 이루어져있다.
6-2-9) 그래프 테마리스트 확인

pit.style.available을 실행시키면 사용가능한 그래프 테마리스트를 확인할 수 있다. 그래프 테마리스트에는 그래프의 배경과 폰트 설정이 테마안에 들어있다.
6-2-10) 그래프 테마 적용하기
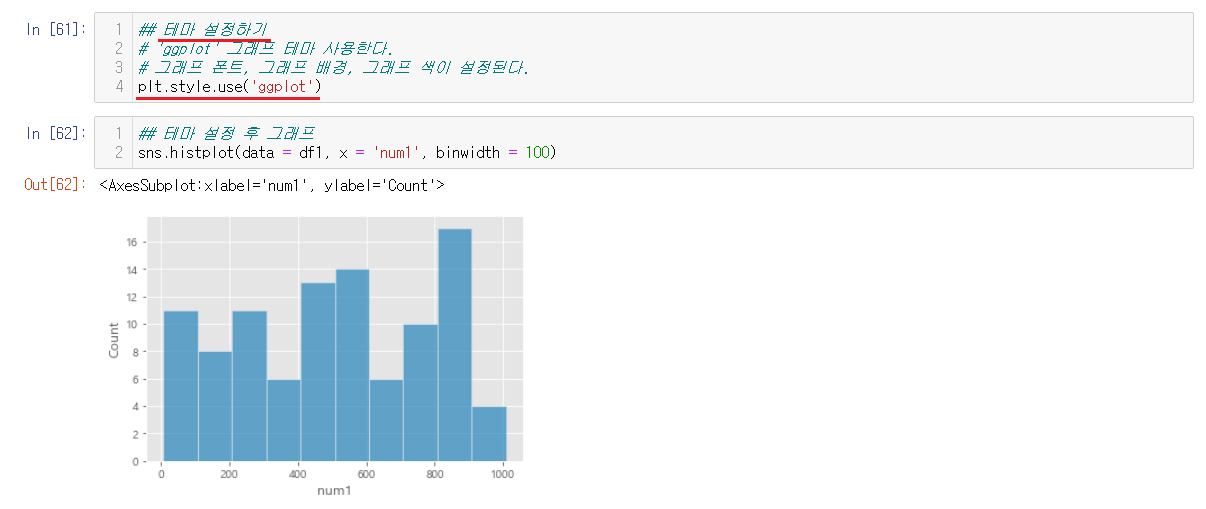
위에 가능했던 테마들중에 ggplot으로 테마를 적용해주었다. 그래프의 폰트, 그래프 배경, 그래프 색이 테마대로 설정되었다.
6-2-11) x축 이름 변경하기
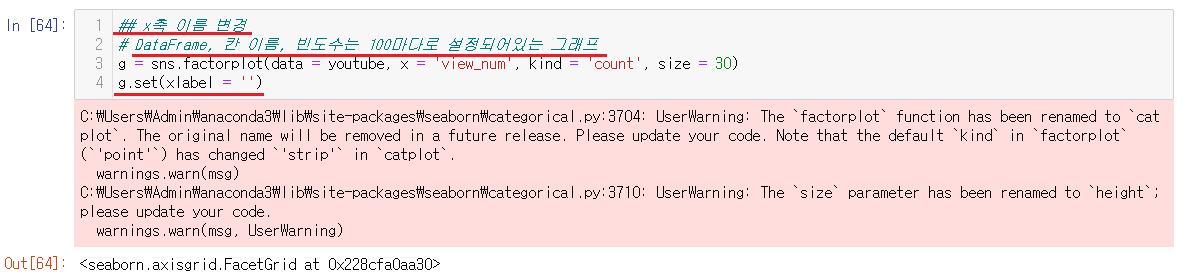
.get(xlabel = '변경할 이름') 으로 변경하는데 값을 넣지않을거라면 ''로 아무것도 넣지 않으면 값이 없어진다. 현재는 값을 없애는 걸로 진행했다.
밑에 x축의 값이 아무것도 나오지않았음을 확인할 수 있다.
6-2-12) x축, y축 이름 변경하기

set(xlabel, ylabel)를 통해서 변경이 가능하다. 현재는 x축을 '조회수', y축을 '개수'로 변경했다.
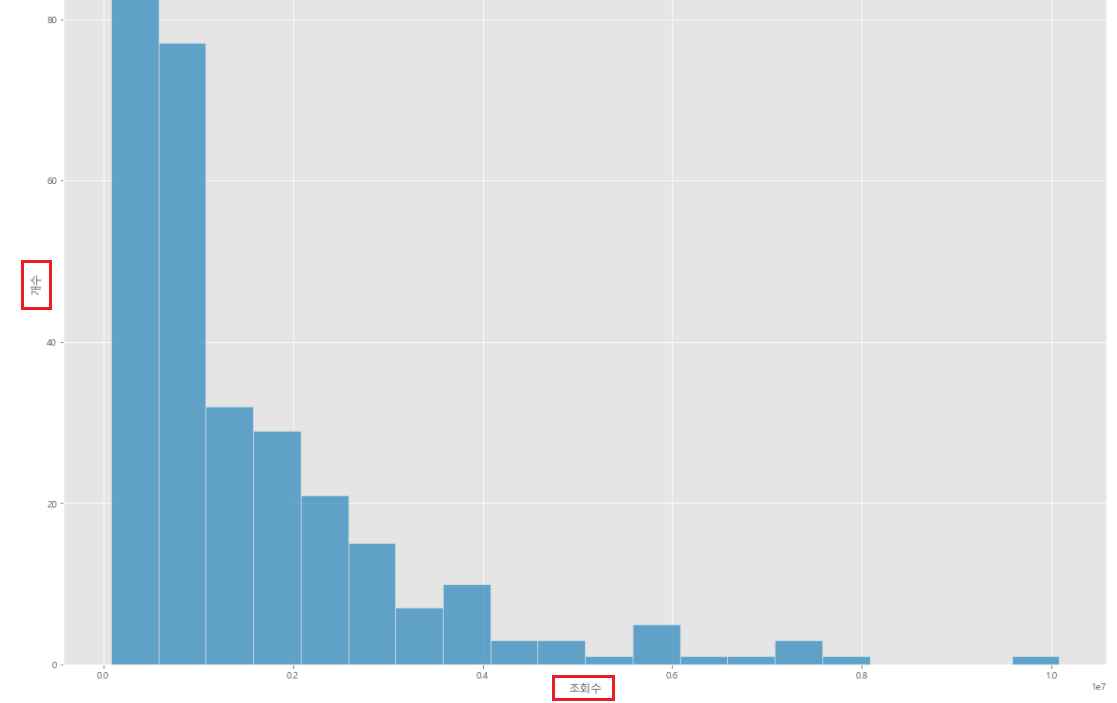
변경됨을 확인할 수 있다.
6-3) 조회수 시각화
6-3-1) 새로운 칸을 추가하기
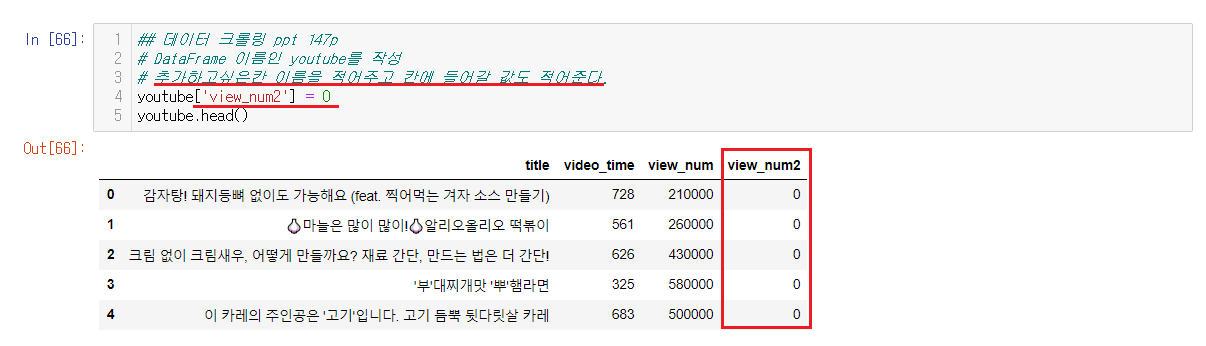
DataFrame['칸 이름'] = 칸의 값
을 사용해서 생성할 수 있다. 현재 우리는 조회수를 나누어서 조회수를 예측할 것이기에 나눈 값을 넣을 칸을 생성한다.
6-3-2) 조회수 출력하기
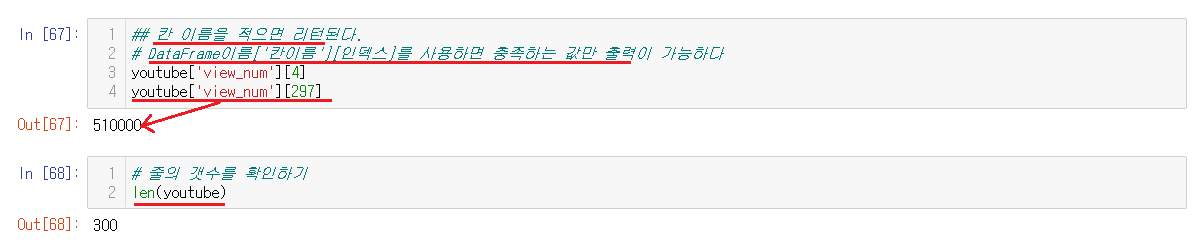
DataFrame이름['칸이름'][인덱스]를 통해서 우리가 사용하고자하는 조회수만이 출력이 가능하다. 안의 들어있는 조회수의 값과 나눌 값들을 for문으로 돌려주어야하기에 len으로 갯수를 확인해준다. 총 299개의 동영상이였고 len으로 따지면 300개니 모두 들어있다는 것을 알 수 있다.
6-3-3) 모든 조회수 출력하기
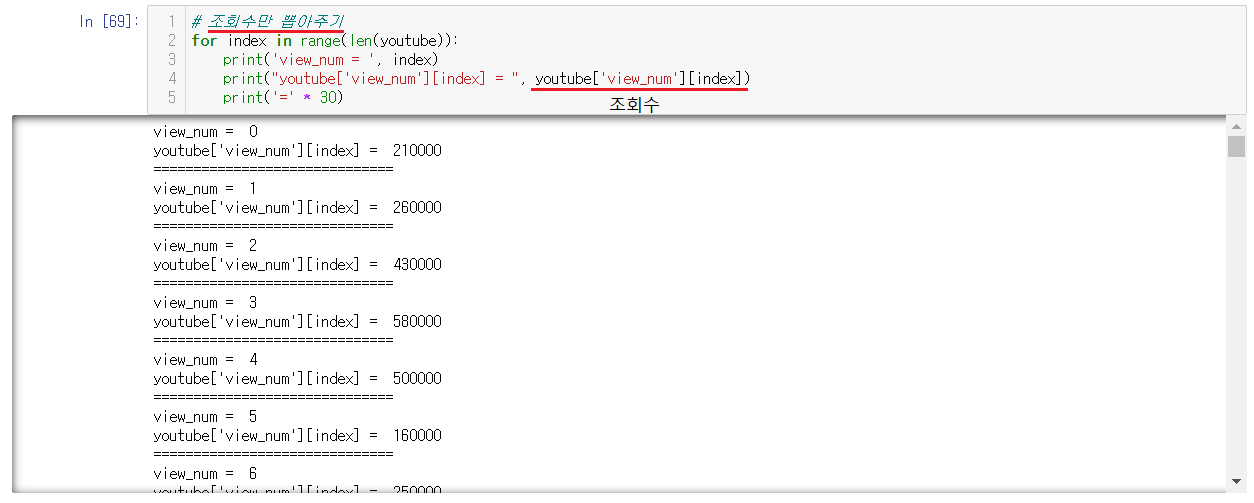
위에서 DataFrame이름['칸이름'][인덱스]로 조회수만이 출력가능하다는 것을 확인했으니, 이를 for문으로 돌려서 모든 조회수를 출력한다.
6-3-4) view_num2에 값 넣어주기
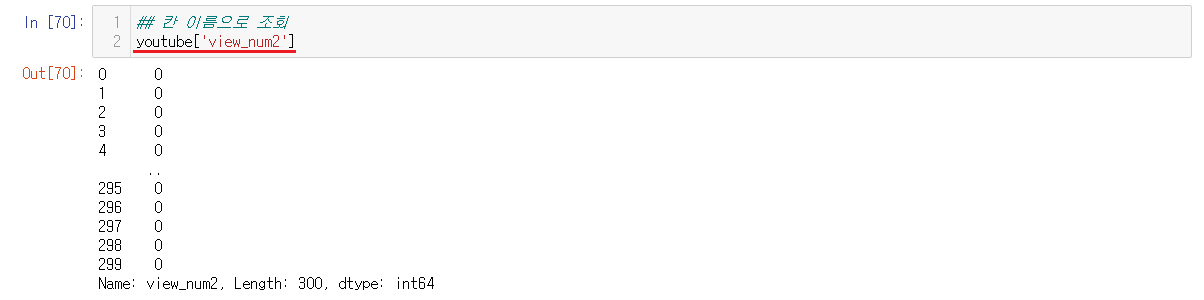
view_num2에 값을 넣어주기전에 재대로 들어있는지를 확인해준다. 확인해보기 0으로 값들이 다 들어있고 300개인것도 알 수 있다.
먼저 전체적으로 값을 바꾸기전에 값을 어떻게 바꾸는지 알아보자면,
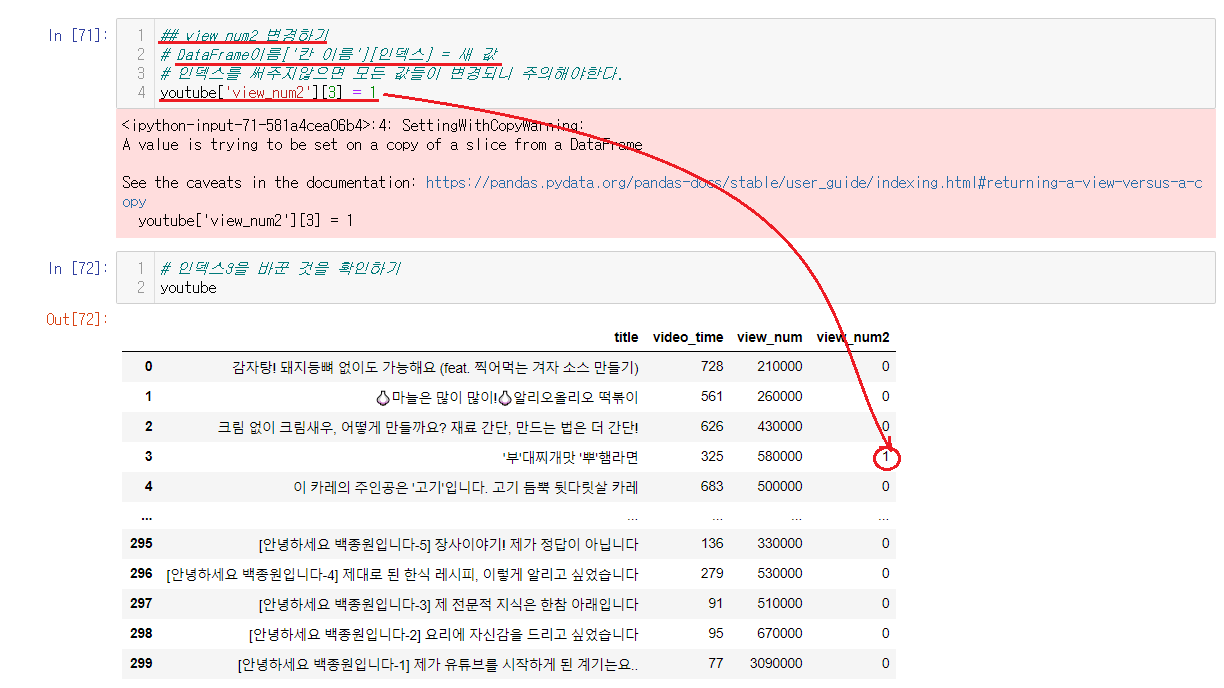
DataFrame이름['칸 이름'][인덱스] = 새 값
값을 원하고자하는 인덱스의 번호를 적어서 새 값을 입력해주면 값이 변경된다. 주의해야할 점은 인덱스를 써주지않는다면 모든 칸의 값들이 바뀌니깐 주의해야한다. 만약 그렇게 입력해버렸다면 먼저 인덱스를 적어주고 당황하지말고 다시 처음부터 실행하면 된다.
6-3-5) 조회수를 나눠서 view_num2에 값 넣어주기
조회수를 예측하기 위해서 0, 1, 2로 조회수 값을 나누어주려고 한다.
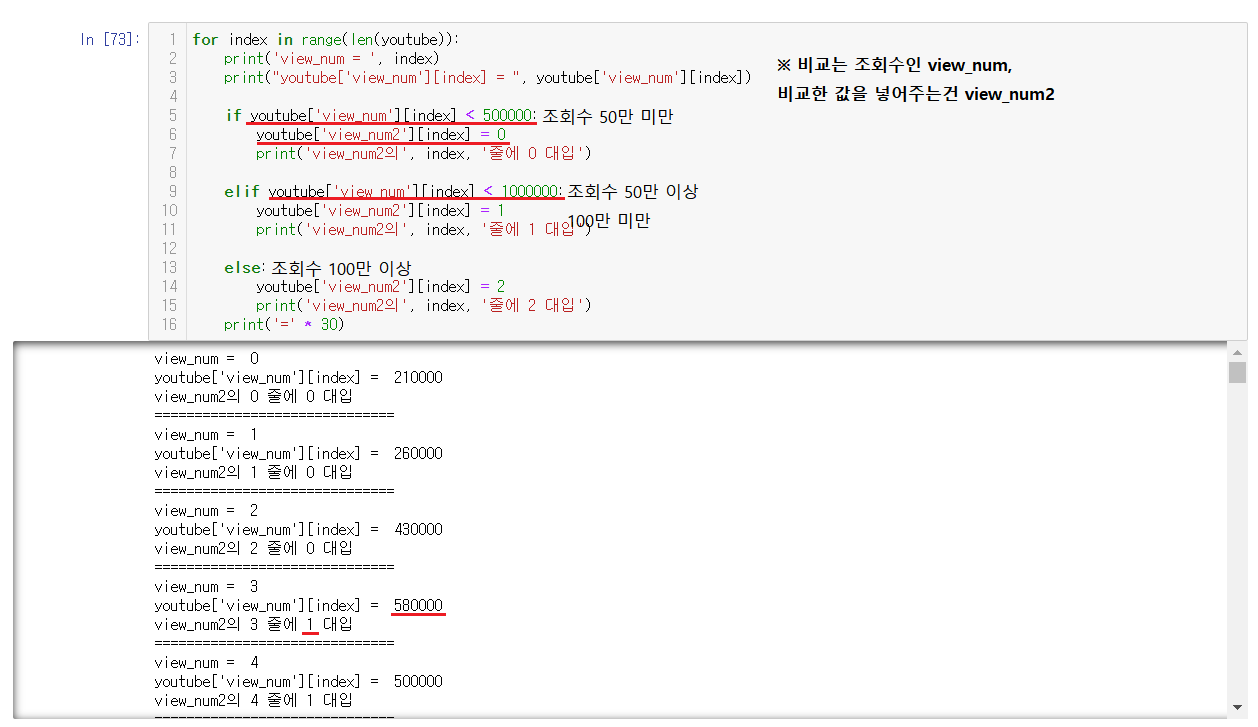
0 : 조회수가 50만 미만
1 : 조회수가 50만 이상 100만 미만
2 : 조회수가 100만 이상
이렇게 나누어서 view_num2에 넣어진 값들을 이용해서 예측할 것이다.
※ 조회수가 들어있는건 view_num이라서 if문에서 비교할 때 view_num을 사용하지만, 직접적으로 비교한 값이 들어가야할 곳은 view_num2이므로 주의해야한다. 만약에 값이 둘을 잘못쓴다면 값들이 변해서 사용할 수 없으니 틀린 부분을 수정 후 다시 처음부터 실행하면 된다.
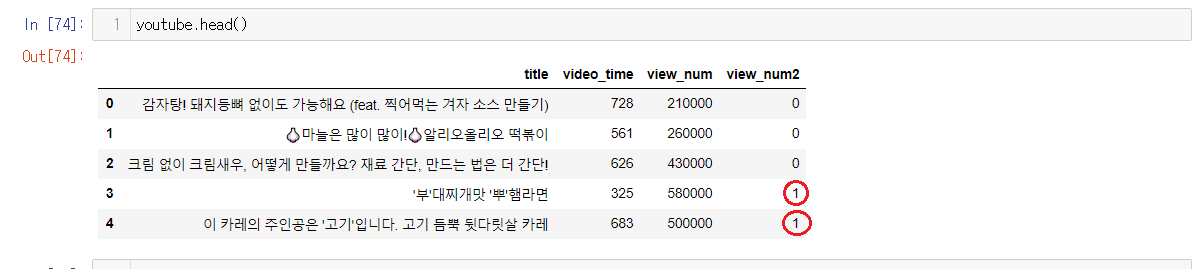
head()을 통해서 앞의 5개를 확인해보니 값들이 조회수를 나눈것에 맞춰서 변경되어있음을 확인할 수 있다.
6-3-6) 시각화하기
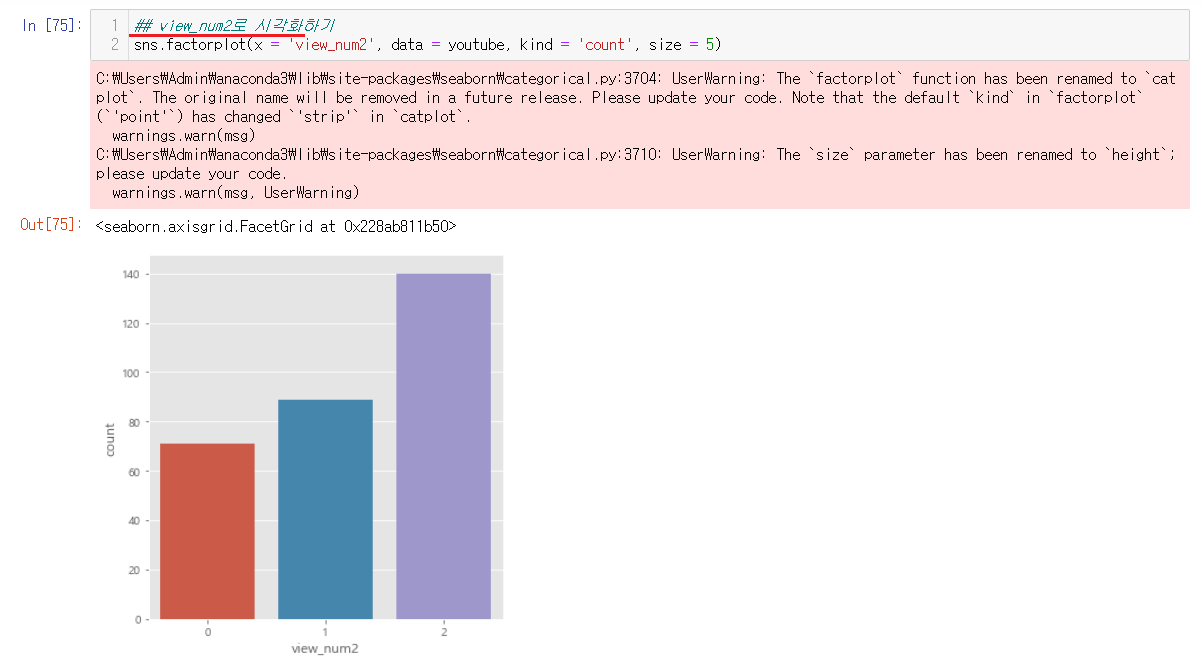
view_num2를 시각화해서 조회수의 값이 얼만큼인지를 시각화를 통해서 볼 수 있다.
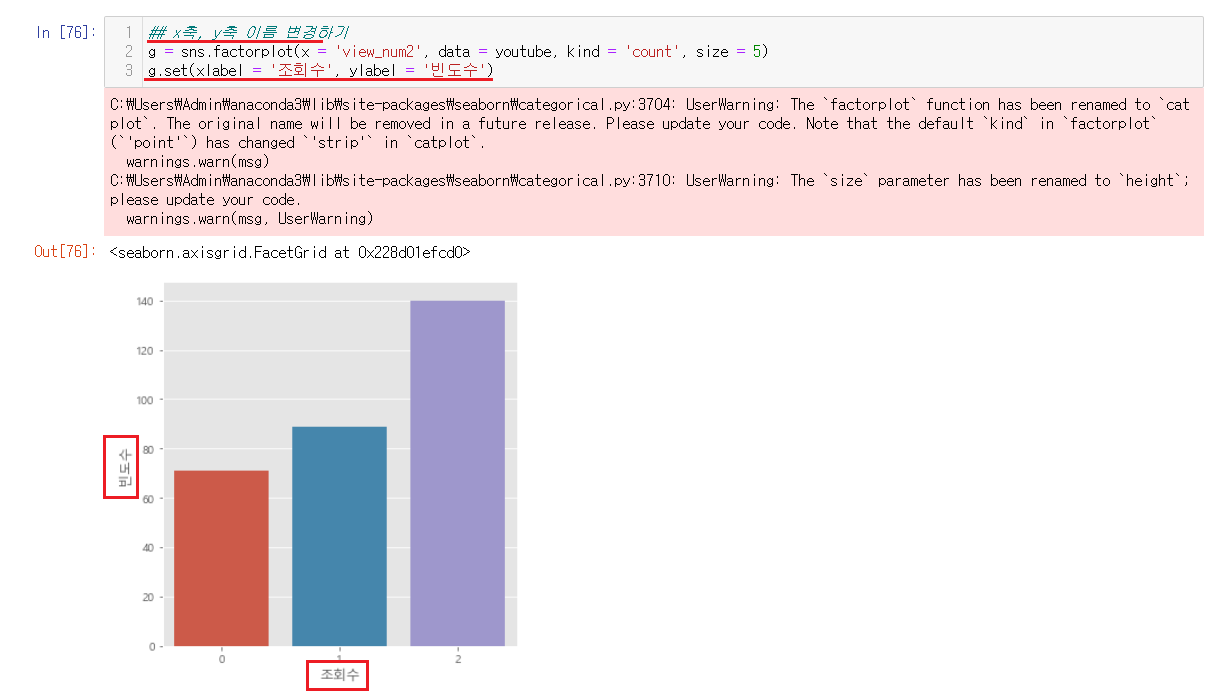
좀 더 보기편하게 x축과 y축에게 이름을 주어서 무엇을 나타내고있는지 알 수 있도록 설정해주었다.
6-4) Decision Tree를 사용해 제목으로 조회수 예측하기
6-4-1) Decision Tree
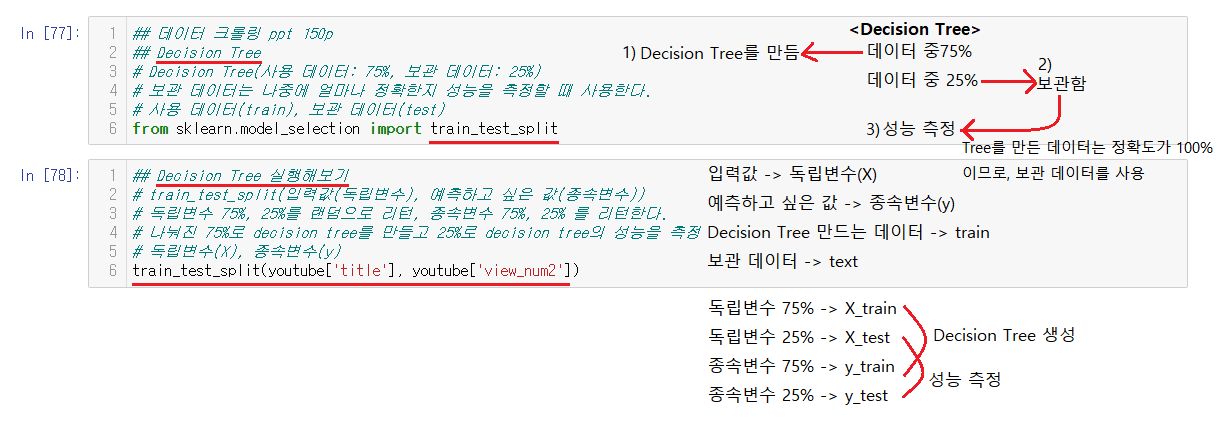
Decision Tree는 데이터를 75% ,25%로 나눈다. 75%의 데이터로는 예측하기위한 Decision Tree를 만드는데 사용하고 25%는 보관한다. 보관하는 데이터는 예측이 끝난 후, 예측이 정확하게 맞는지에 대한 성능을 측정할 때 사용한다. 따로 보관해서 사용하는 이유는 이미 데이터에 들어가있는 데이터를 성능 측정으로 사용하면 이미 들어가서 성능이 100%라고 출력되기때문이다.
입력된 값은 독립변수라고 부르며 표기할 때는 대문자 X를 사용한다. 예측하고 싶은 값은 종속변수라고 부르며 표기는 y로 한다. Decision Tree를 사용하기위해서 train_test_split를 통해 독립변수와 종속변수를 나누어준다.
6-4-2) 독립변수, 종속변수 나누기
위의 사용된 train_test_split의 결과를 확인해보면


Decision Tree를 설명한거와 같이 독립변수, 종속변수가 75%, 25%로 나누어졌다. 나누어지는 기준은 랜덤임으로 각자 다 다른 값들을 가진다. 현재 우리가 준 독립변수는 title, 종속변수는 view_num2로 제목을 통해서 조회수를 예측하는 것이다.

나누어진 값들은 설명했던 값들에 지정해서 넣어주면 된다.
혹시 모르니 값들이 잘들어갔느지 확인해준다.
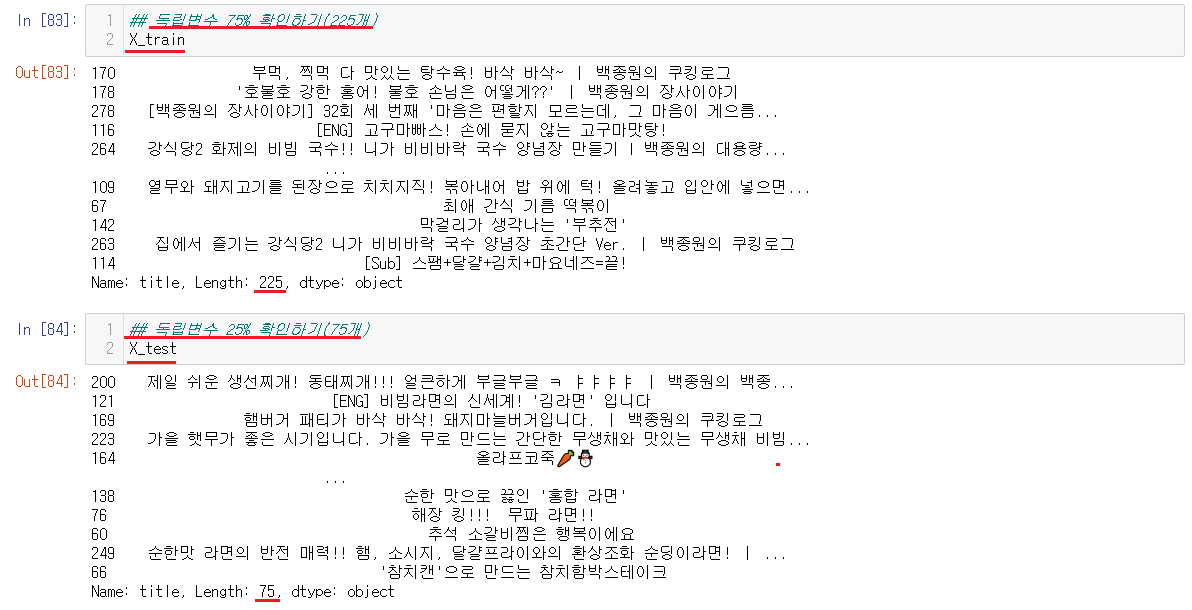
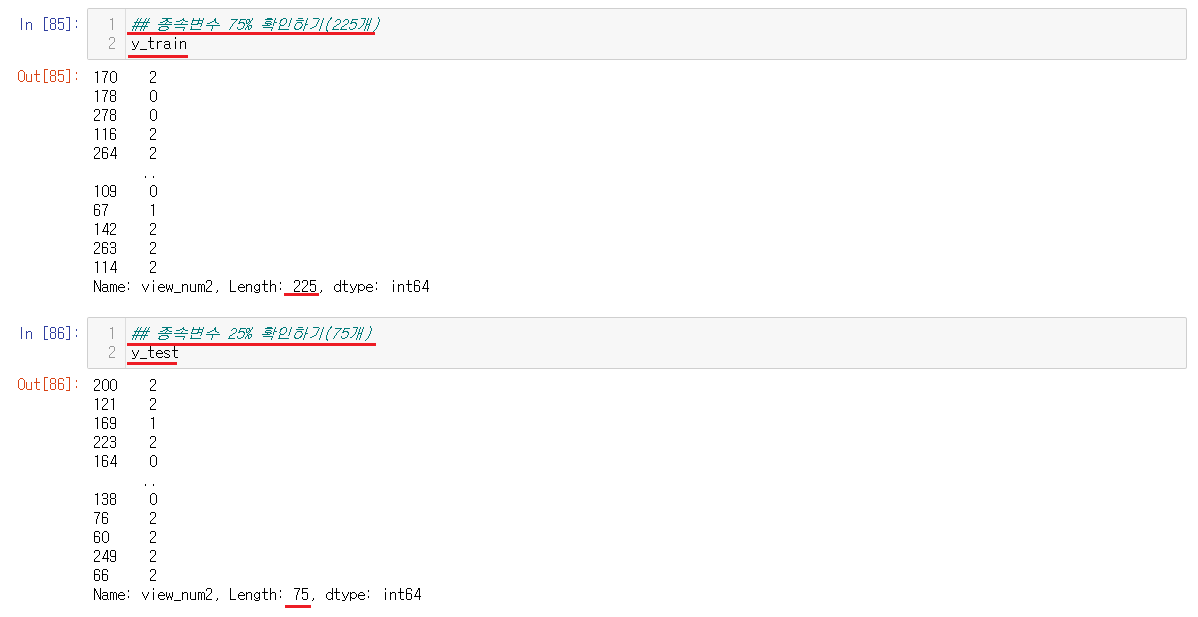
모두 잘 들어가있음을 확인했다.
6-4-3) 명사, 형용사 나누기
6-4-3-1) 품사 나누기 확인하기

문장을 나눈후 명사와 형용사만을 이용해서 TF-IDF를 진행할 예정으로 먼저 명사와 형용사를 나누어보고자한다.
6-4-3-2) 명사와 형용사만 뽑아내기
나누고 단어와 품사가 어디에 위치하는지도 알았다. 단어는 tagged[index]안에 0번 인덱스, 품사는 tagged[index]안에 1번 인덱스에 위치한 것을 이용해서 뽑아낼 수 있다.
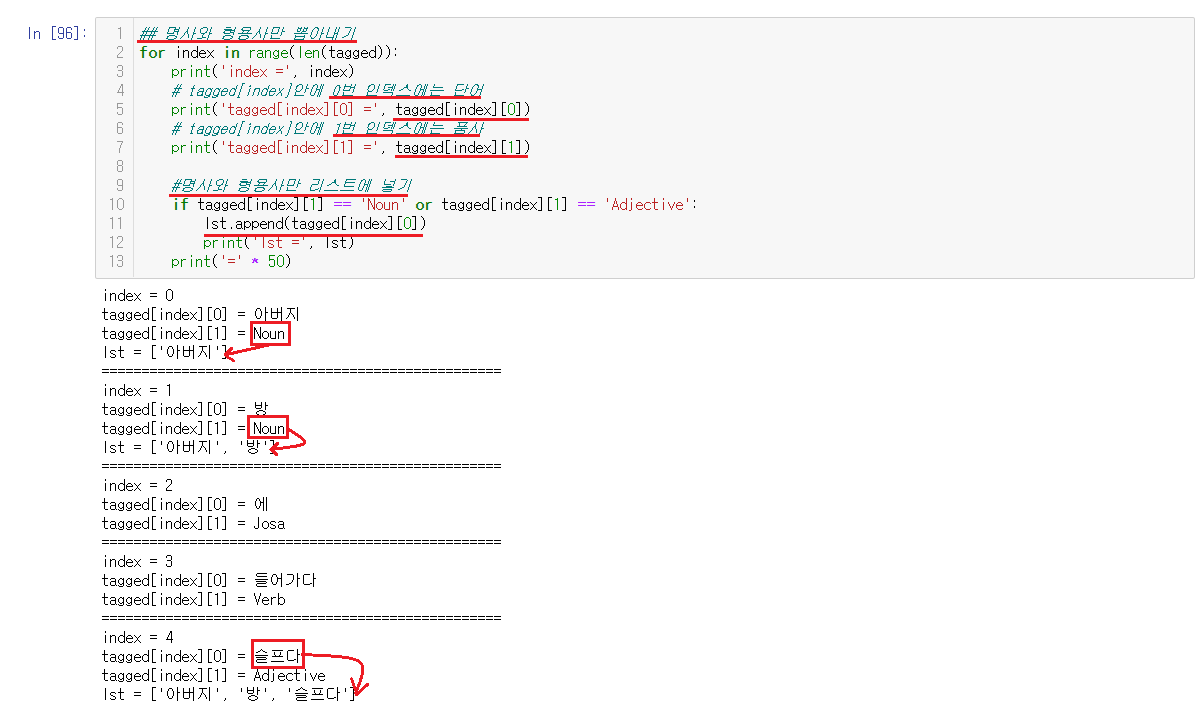
결과를 확인해보면 '에', '들어가다'는 리스트는 명사와 형용사가 아니므로 들어가지 못한다.
6-4-3-3) 명사와 형용사만을 리턴하는 함수 생성
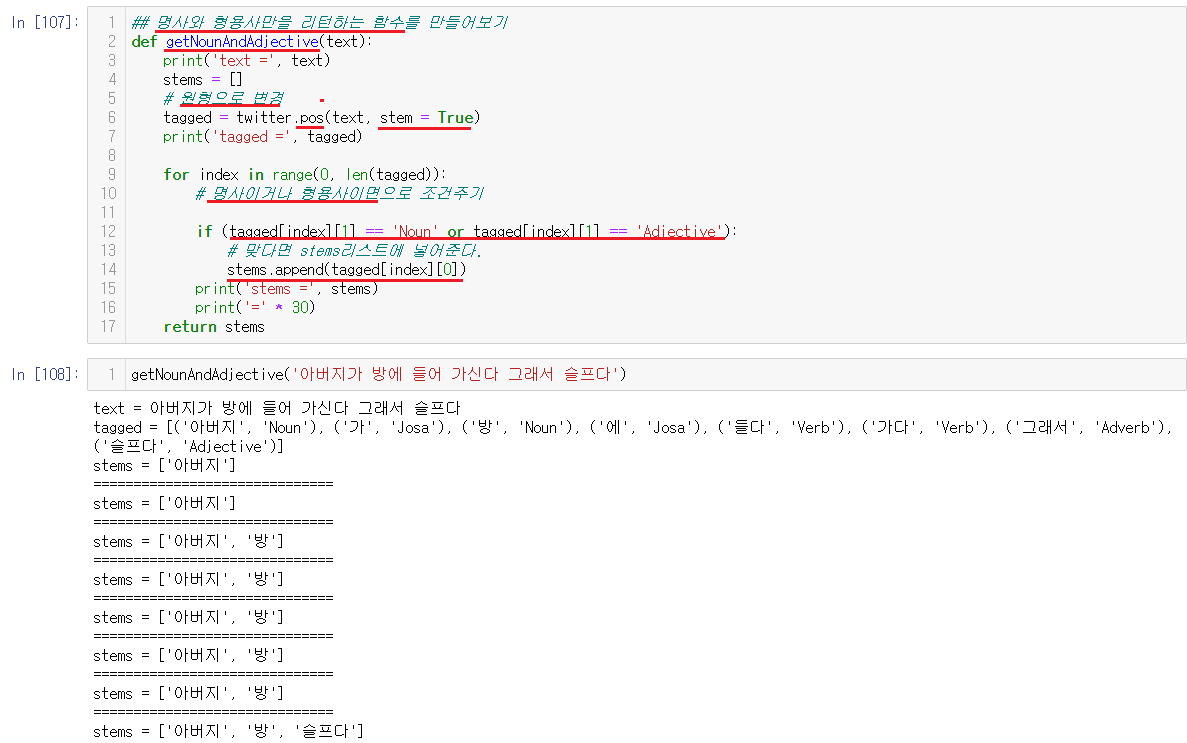
위의 for문을 이용해서 명사와 형용사만을 리턴하는 함수를 만들어서 편하게 나눠보고자한다. 현재는 stems라는 리스트안에 명사와 형용사가 들어가도록 되어있다. 항상 먼저 확인하는 것이 중요하므로, 당장 조회수에 대입하기보다는 먼저 예시로 실행해보는것이 좋다. 예시로 위에서 사용한 '아버지가 방에 들어 가신다 그래서 슬프다'를 사용해보면 똑같은 값으로 리스트에 잘 들어왔음을 확인할 수 있다.
6-4-4) TF-IDF
나눠준 단어들을 넣어서 이 단어들의 빈도수를 체크해주어야한다.
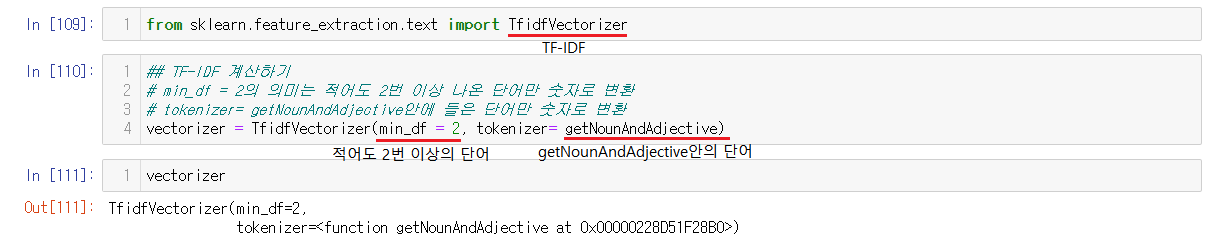
먼저 시작전에 TfidfVectorizer를 import해주는 것을 잊으면 안된다. 빈도수를 체크하는데 min_df로 몇번 이상 등장한 단어들만 뽑을건지를 설정하는 것도 가능하다. tokenizer로는 숫자로 변환할 단어들을 넣어준다.
6-4-4-1) 독립변수 75%를 숫자로 변경하기
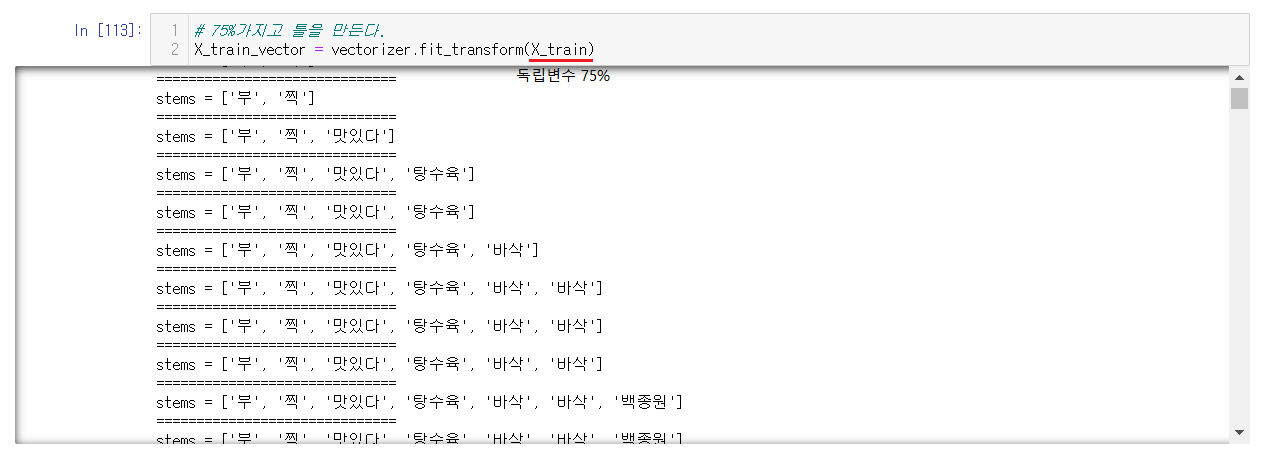
Decision Tree를 만들 독립변수 75%인 유튜브의 제목들을 명사, 형용사로 나누어서 넣어준다.
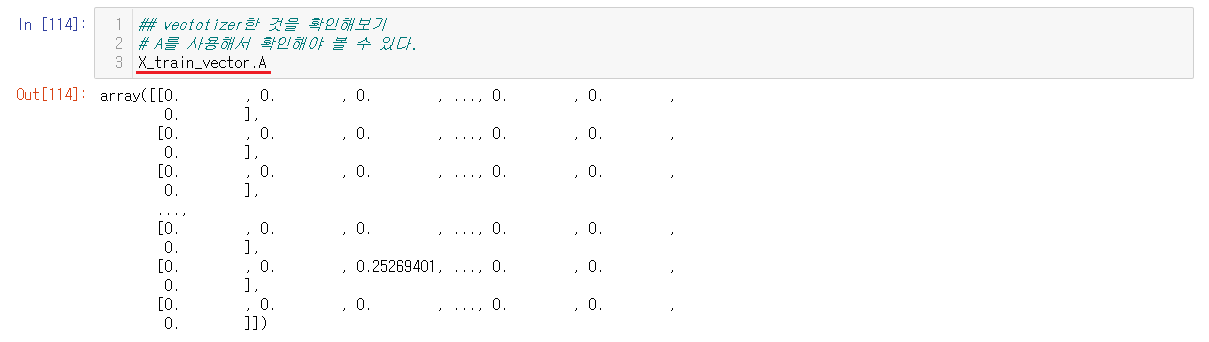
재대로 되었는지 확인해보는데 항상 확인하기위해서는 A를 사용해서 확인한다.
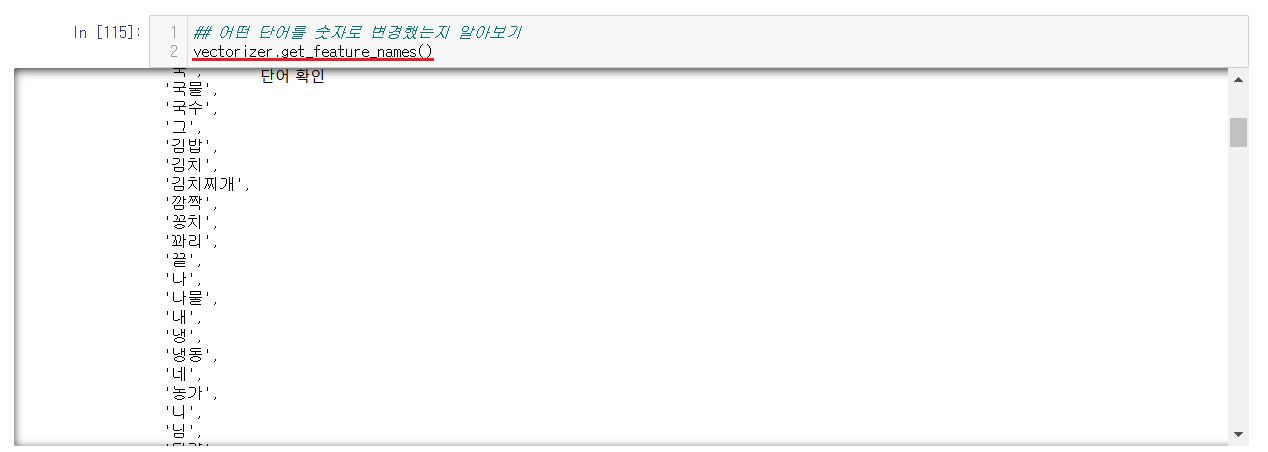
숫자로 변경된 것을 확인했지만, 무엇이 변경된건지는 알 수가 없음으로 .get_feature_names()을 통해서 무슨 단어들이 들어있는지를 확인해본다.
마지막으로 숫자로 변경된 단어들과 숫자의 값을 한번에 보기위해서 DataFrame을 만들어서 보기쉽도록 만들어서 확인해본다.
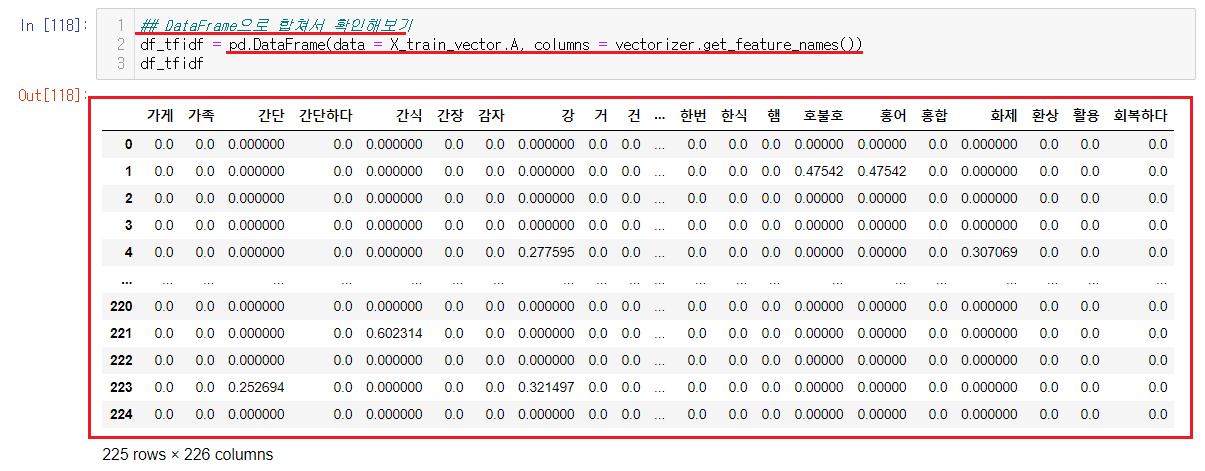
본인의 값이 다르더라도 당황하지않아도 된다. 처음의 독립변수와 종속변수가 랜덤으로 나눠졌음으로 사람마다 다른 값들을 가지고있는게 맞는 답이다.
6-4-5) Decision Tree

TF-IDF가 끝났으니 이제 Decision Tree를 생성한다. 시작하기전에 DecisionTreeClassifier(Decision Tree패키지)를 불러와야지 실행할 수 있다. Decision Tree를생성하는 함수는 fit()이며, 안에는 독립변수 75%, 종속변수 75%를 넣어준다. 우리의 독립변수 75%는 숫자로 변환된 제목, 종속변수 75%는 조회수이다. Decision Tree는 파이썬으로 직접 컴퓨터가 생성해서 만들게 된다.
6-4-5-1) 예측하기위한 유튜브 제목을 만들기

예측해보기 위해서 예측을 할 유튜브 제목을 생성해준다.
6-4-5-2) 예측을 위해 제목들을 나눠고 숫자화
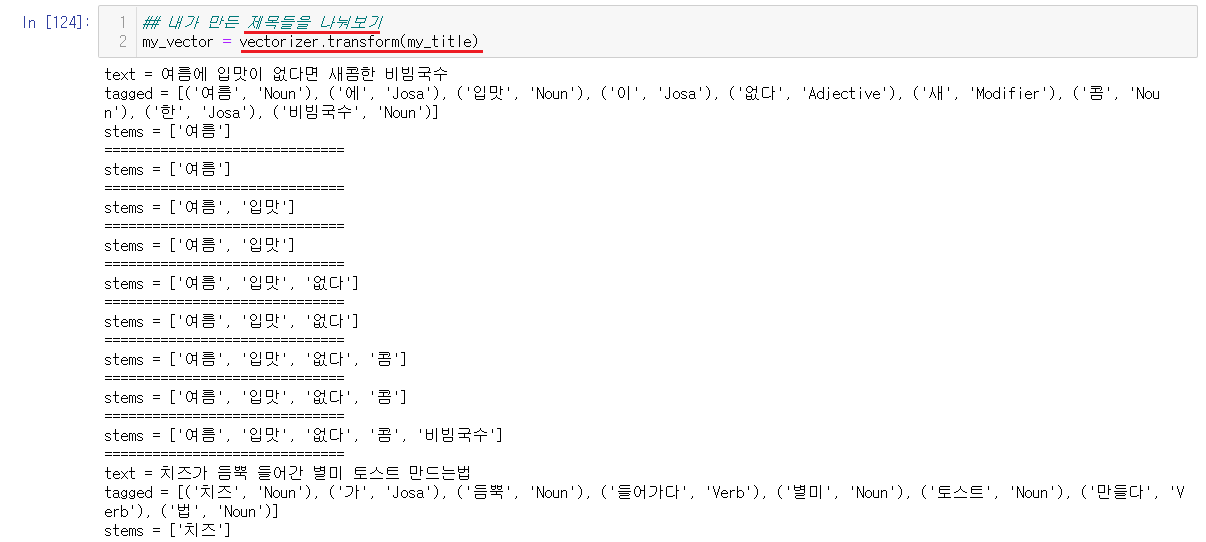
예측을 위해서는 만든 제목들도 숫자화해주어야하는데 우리가 숫자화를 위해서는 먼저 명사와 형용사를 나눈 후에 숫자화를 해주었기에 똑같이 명사와 형용사를 먼저 나누어준 후 숫자화시키고 확인한다.
숫자화가 잘 진행되어있음을 확인할 수 있다.
6-4-5-3) Decision Tree안에 넣어서 예측하기

predict() = 넣어서 예측하는 함수를 사용한다. fit은 생성하고 predict은 예측한다. 예측하기위해서 만든 유튜브 제목의 예측 결과에서 나온 리스트는 인덱스[0]의 0은 첫번째 제목은 50만 미만, 인덱스[1]의 2는 두번째 제목은 100만 미만, 인덱스[2]의 2는 3번째 제목은 100만 이상이라는 뜻이다.
6-4-5-4) 예측 성능을 확인을 위해 보관값 숫자화

보관해놓은 독립변수 25%를 이용해서 예측된 값의 성능을 확인하기위해서 값을 확인해본다.

Decisin Tree는 숫자만 되니, 명사와 형용사를 숫자로 변경해준다.
숫자화가 잘되어있는지 확인해준다.
6-4-5-5) 예측 성능을 확인하기
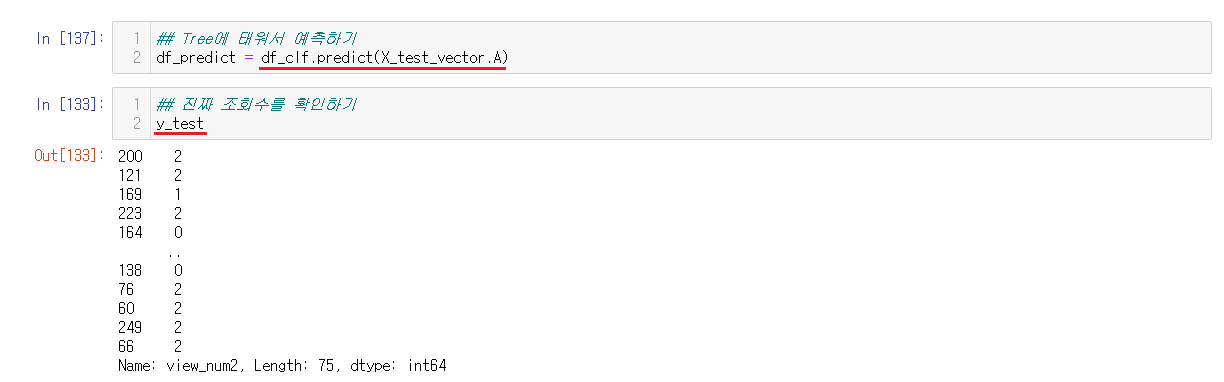
보관된 값들을 숫자화해서 predict()을 통해서 예측해준다. 예측한 값들을 진짜 조회수와 비교해보면 정확성을 확인할 수 있다.

accuracy_score를 통해서 보관을 통해서 예측한 값과 진짜 조회수가 얼마나 맞는지를 퍼센트로 나타내준다.

confusion_matrix를 통해서 어떻게 예측을 했는지 좀 더 디테일하게 볼 수 있는데 얼마나 맞았는지를 표처럼 보여준다.
| 예측: 0 | 예측: 1 | 예측: 2 | |
| 진짜 데이터: 0 | 2(예측:0, 진짜 데이터:0) | 3(예측:1, 진짜 데이터:0) | 7(예측:2, 진짜 데이터:0) |
| 진짜 데이터: 1 | 6(예측:0, 진짜 데이터:1) | 6(예측:1, 진짜 데이터:1) | 14(예측:2, 진짜 데이터:1) |
| 진짜 데이터: 2 | 2(예측:0, 진짜 데이터:2) | 9(예측:1, 진짜 데이터:2) | 26(예측:2, 진짜 데이터:3) |
위의 표를 참고하면 리스트의 뜻을 알 수 있는데 이런식으로 Decision Tree를 사용할 수 있다.
'PBL 빅데이터 > 빅데이터 수집' 카테고리의 다른 글
| [수업] 빅데이터 수집3 (0) | 2021.04.29 |
|---|---|
| [수업] 빅데이터 수집2 (1) | 2021.04.28 |
| [수업] 빅데이터 수집1 (0) | 2021.04.27 |


