1) 데이터 크롤링
1-1) 데이터 크롤링
- 자신이 원하는 정보를 웹페이지에서 가져오는 행위 또는 작업
1-1-1) BeautifulSoup 다운받기
1) Anaconda Prompt를 실행
2) pip install BeautifulSoup4 쳐서 다운해주기

1-1-2) Jupyter Notebook을 실행해서 웹 크롤링해보기
1) 먼저 url크롤링에서 사용할 urllib를 import한다.
2) 접속해서 가져올 페이지를 설정한다.
3) 사이트의 내용을 가져올 객체를 생성한다.
4) 사이트를 불러온다.

1-1-3) 이미지 크롤링
1) 이미지의 주소를 복사한다.
2) url에 이미지 주소를 넣어준다.
3) 파일을 저장할 이름도 지정해준다.
4) ulretrieve(다운받을 url, 저장할 이름)을 넣어준다.
5) 실행해주면 현재 jupyter notebook을 실행한 곳에 다운된다.

1-1-4) 가짜 페이지를 크롤링
1) 가짜 페이지를 만들어준다
2) BeautifulSoup을 통해서 가짜 페이지를 크롤링한다.
1) 전체를 크롤링하기


만든 가짜 페이지가 크롤링된 것을 확인할 수 있다.
2) 태그로 크롤링하기

현재 생성된 가짜 페이지의 구조대로 변수가 생성되었으니 이걸 통해서 크롤링할 수 있다.
2-1) h1 크롤링하기

<h1></h1>의 태그가 싫으면 srting 혹은 text를 사용해서 글씨만 뽑을 수 있다.
2-2) p 크롤링하기

p는 현재 2개인데 그냥 p를 사용하면 첫번째 p가 나온다. next_sibling으로 다음으로 넘길 수 있는데 다음은 엔터를 사용해서 엔터가 나왔고 그 뒤의 것을 뽑기위해서 next_sibling.next_sibling을 사용해서 뽑을 수 있다.
3) id로 요소를 찾는 방법
id는 웹 표준에서 지정한 그 페이지에서 id 속성의 값이 유일하다는 것이다. 먼저 그 페이지에서 지정하면 그 값이 유일하다는 의미다.
next_sibling으로 넘기면서 하기가 힘드니 id를 이용해서 뽑는다. id를 뽑을 때는 id 속성이 일치하는 태그를 리턴하는 find라는 함수를 이용해야한다.

id를 가진 가짜 페이지를 다시 생성해준다.

find 함수는 id 속성이 같은 태그(element) 딱 한개만 리턴한다. 혹은 아예 없을 때의 None을 리턴한다.
4) 클래스로 크롤링하기

새로 만들어줫으니 새롭게 soup에 다시 넣어줘야한다.
4-1) find와 class를 사용하기

find와 class를 사용했다. 속성은 딕셔너리라서 파이썬 딕셔너리를 사용하듯이 딕셔너리를 사용해서 찾을 수 있다.
4-2) findAll와 class를 사용하기

여러개의 값을 리턴받기 위해서는 findAll을 사용해서 받아야한다. 그냥 find는 하나만 리턴받으니 여러개는 findAll을 사용한다.
※ 문자만 추출

태그없이 문자만을 보고싶다면 text 혹은 string을 사용해서 문자만 추출하기가 가능하다.
4-3) find와 findAll 같이 사용하기

ul태그이면서 class속성이 'reply'인 태그에 포함된 li만 찾고싶을 때에는 find와 findAll을 같이 사용하는데 이 때 .으로 연결해서 같이 사용해주면 된다.
※ 읽기 방법 차이
read()와 BeautifulSoup으로 읽는 방법이 있다.
read로 읽는 방법이 조금 더 번거롭다.
1) read()

2) BeautifulSoup

딱 한번만 출력되니 주의해서 사용해야한다. 이럴 때는 다시 한번 객체를 만들어서 지정해주고 사용해야한다.
5) 네이버 크롤링
5-1) 네이버 크롤링하기
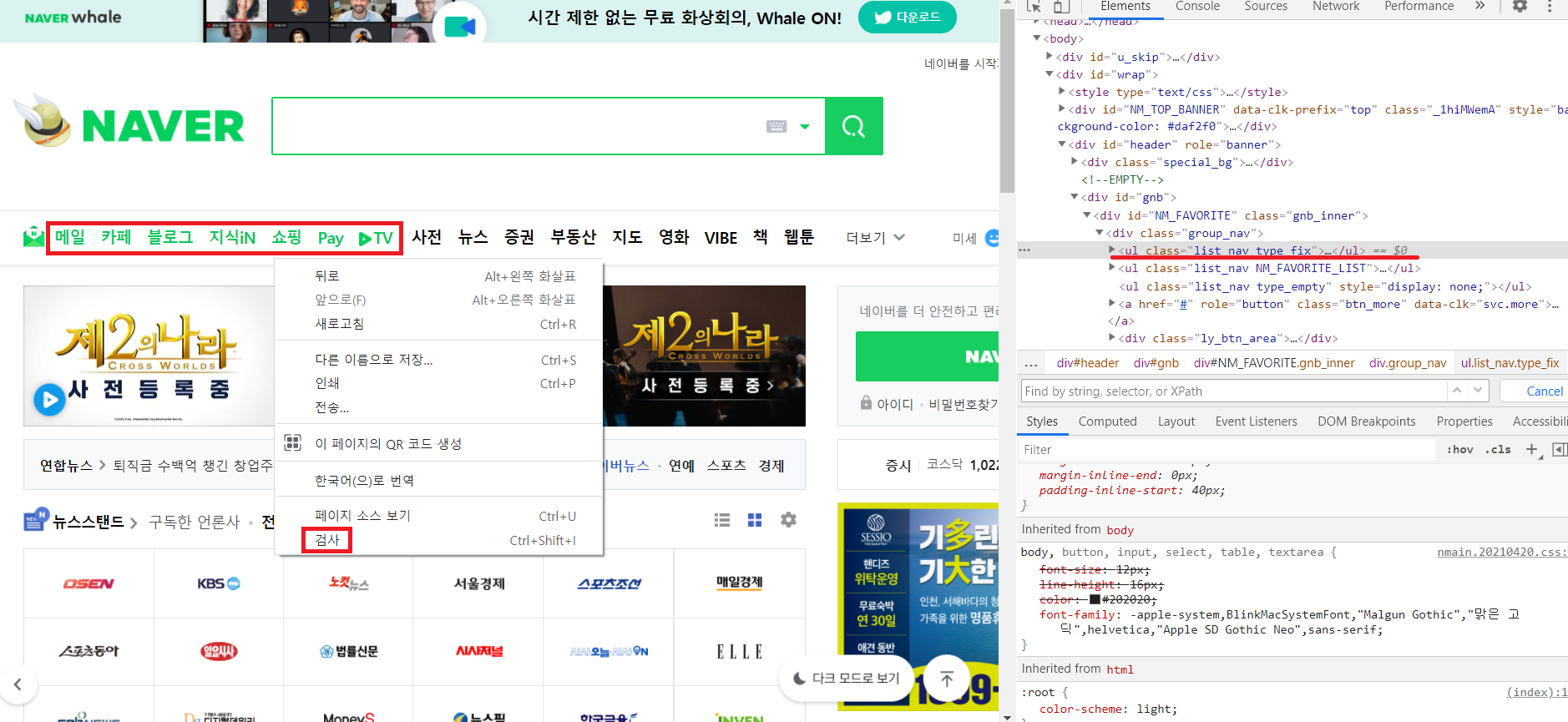
네이버를 크롤링하려고한다. 위에 메일 카페 블로그 부분에서 마우스 오른쪽을 클릭해서 검사를 들어간다. 현재 이부분 페이지에 대해서 나오는데 크롤링을 하기 위해 어떤 부분을 크롤링할지를 확인해야한다.
5-2) 크롤링할 부분을 확인

Ctrl + f 를 눌러서 값을 검색할 수 있는데 find함수를 쓰기 위해서 list_nav와 type_fix를 검색했을 때, type_fix값이 1개이므로 find를 쓰기에 적합하다.
5-3) find사용하기
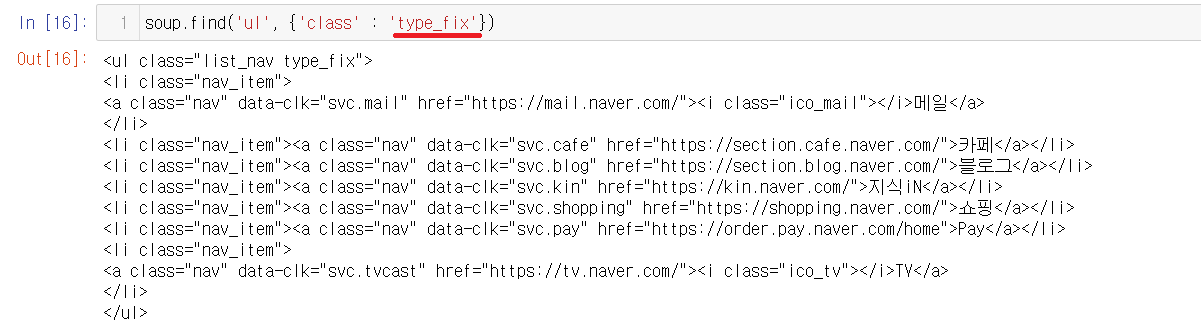
class가 type_fix인 부분이 한 개임으로 find를 사용해서 값을 가져온다.
5-4) li부분만 값을 가져오기

type_fix에서 찾은 값에 li를 가진 부분만 찾고 싶다면 findAll을 사용해서 li부분의 값만 받는다.
※ string과 text의 차이

위에서 크롤링한 li부분을 확인해보면 string과 text의 차이를 확인할 수 있다. string에서 None이었던 부분에 text로 출력하니 값이 찾있음을 확인할 수 있다.
차이를 알아보자.


둘의 차이는 string은 태그에 딱 하나만 포함된 것을 출력하고 text는 태그에 포함된 여러개 문자열을 출력한다. 예시와 같이 포함하는 것이 2개 이상이 되면 string은 None을 출력한다. 그렇기에 2개이상이라면 text를 써야한다.
6) 영화 크롤링
네이버 뮤비에서 크롤링을 해보려고한다.
6-1) 검사를 통해서 class찾기

검사를 눌러서 아까와 같이 값이 1개인 값을 찾아본다. 현재는 값이 1개인 것은 td class = 'title' 이다.
6-2) class = 'title'로 찾기
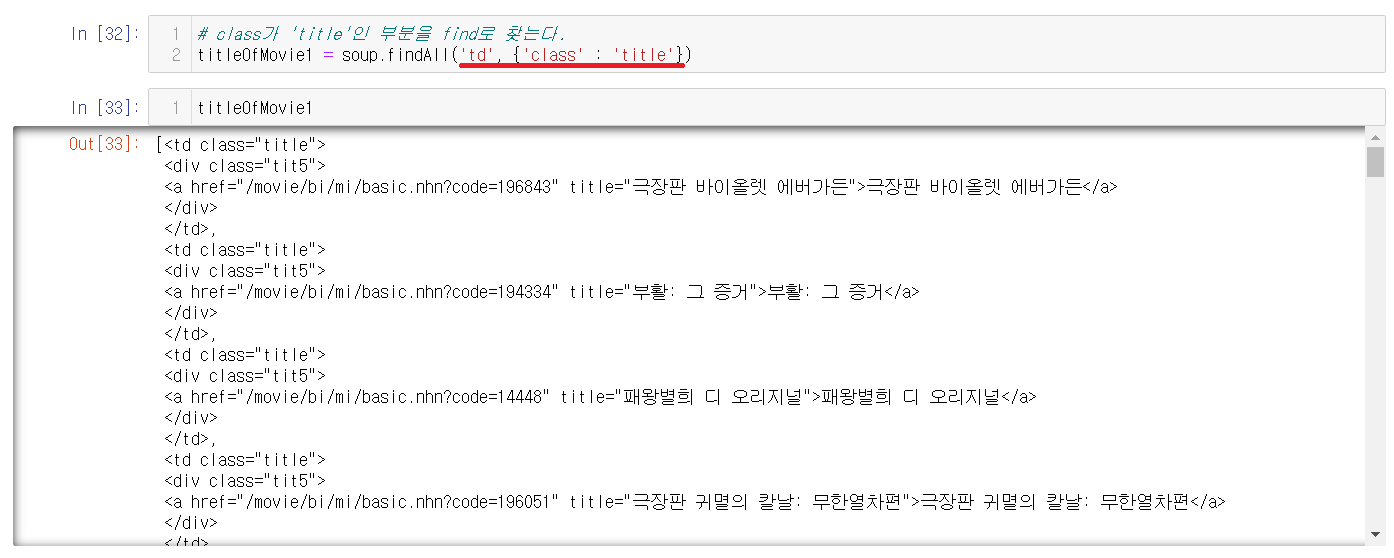
td 태그에 class = 'title'인 부분을 가져오면 태그들이 섞여있는 것을 확인할 수 있다.
6-3) 문자만 추출
태그가 섞이면 보기 어려우니 문자만 추출한다.

text를 이용해서 문자만 추출할 수 있다. 이번에는 태그가 없어졌지만, 엔터들이 눈에 거슬리게 된다.
6-4) 엔터 지우기

strip()은 공백과 탭을 지워주는데 사용한다. strip()을 사용해보니 엔터부분들이 지워지고 말끔하게 출력되는 것을 확인할 수 있다.
6-5) 평점 구하기
제목을 추출한 것과 같이 별점을 추출한다.

6-6) 제목과 평점 합치기

제목과 별점을 합치기 전에 먼저 둘의 길이를 확인한다. 둘 다 50으로 range(50)을 통해서 for문을 돌려서 합쳐줄려고 한다. 위의 결과와 같이 합쳐지지만 zip을 이용해서 좀 더 깔끔하게 만들 수 있다.
6-7) zip 사용하기

zip은 여러개의 리스트를 합칠 때 사용한다. zip을 이용하면 이전의 결과보다는 더 깔끔하게 출력됨을 확인할 수 있다.
※ zip

zip에 대한 예시이다. zip은 여러개의 리스트를 합칠 때 사용된다. 위의 예시와 같이 합쳤다고 출력되지않고 list함수를 통해서 출력할 수 있다.
'PBL 빅데이터 > 빅데이터 수집' 카테고리의 다른 글
| [수업] 빅데이터 수집4 (0) | 2021.04.30 |
|---|---|
| [수업] 빅데이터 수집3 (0) | 2021.04.29 |
| [수업] 빅데이터 수집2 (1) | 2021.04.28 |


