2) 날씨 데이터 크롤링
기상청 오늘의 날씨를 이용해서 날씨 데이터를 크롤링해볼려고한다.
url = www.weather.go.kr/weather/observation/currentweather.jsp
크롤링할 데이터: 동네이름, 기온, 습도
2-1) requests.get 사용하기
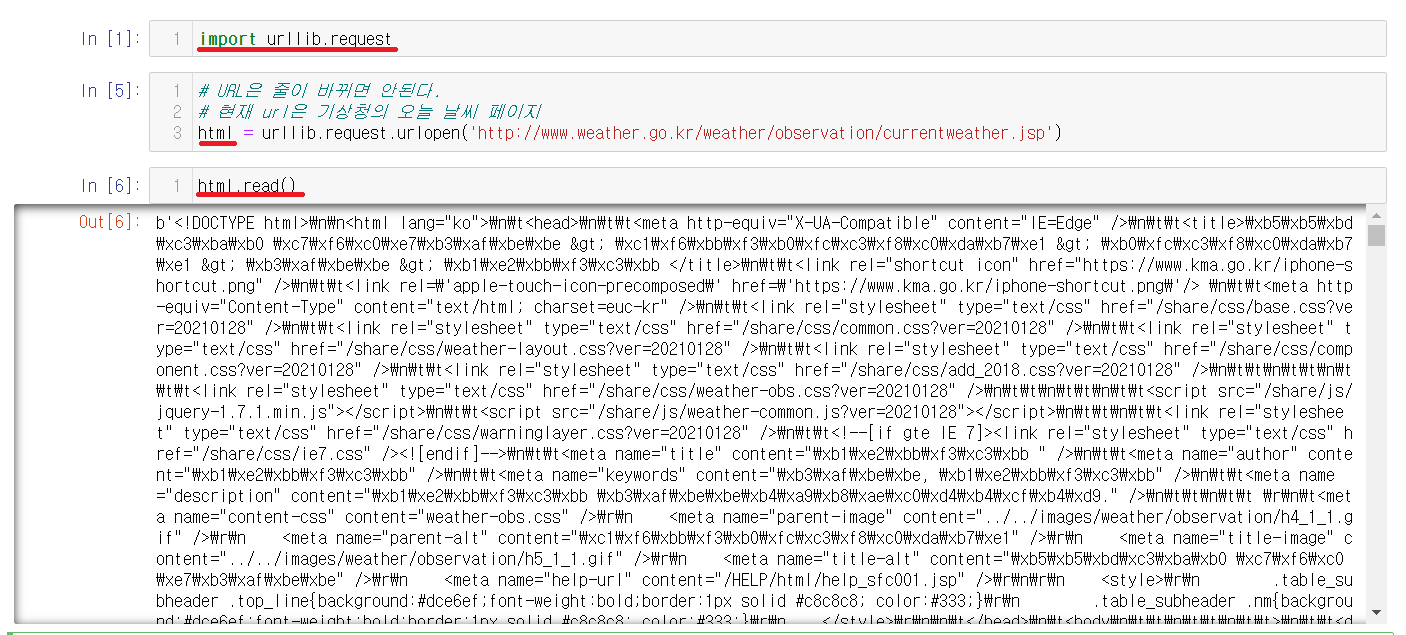
기존에는 read()를 사용해서 불렀지만 read()보다 한번에 가져올 수 있는 requests를 사용할 것이다.
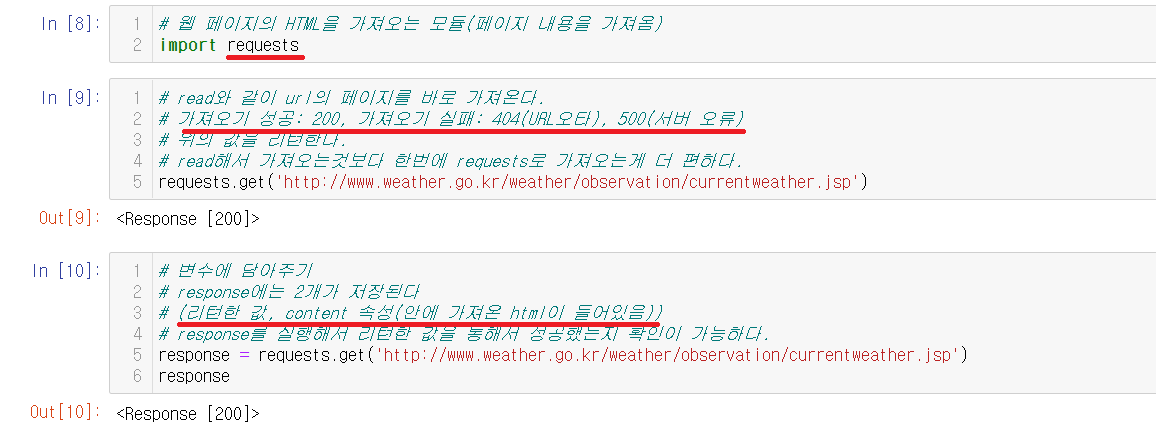
import requests로 requests를 불러온다. read()와 같이 requests는 get()을 통해서 가져온다. requests.get은 2가지의 값을 가지고 있다.
requests.get
1) 리턴한 값
가져오기 성공: 200, 가져오기 실패: 404(URL오타), 500(서버 오류)
2) content 속성
가져온 html의 내용이 들어있다.이런식으로 2가지의 값을 가지고 있다. response.get을 가진 변수 response를 출력해서 리턴값을 통해 가져오기에 성공했는지를 확인할 수 있다.
2-2) response.content, response.text
response.content, response.text를 사용해서 html의 내용을 출력할 수 있다.


response.content로 html을 불러올 수 있다.
content와 text를 이용해서 출력이 가능한데 둘의 다른점은 content는 encoding으로 text는 decoding이라는게 차이점이다.
| content | text |
| encoding(한글이 숫자로 표시) | decoding(한글을 한글로 표시) |
encoding은 한글을 숫자로 표기해주고 decoding은 한글을 한글로 표시해준다. 위의 사진들을 통해서 숫자와 한글의 표시를 확인할 수 있다. 즉, content는 encoding, text는 decoding되어서 나온다.
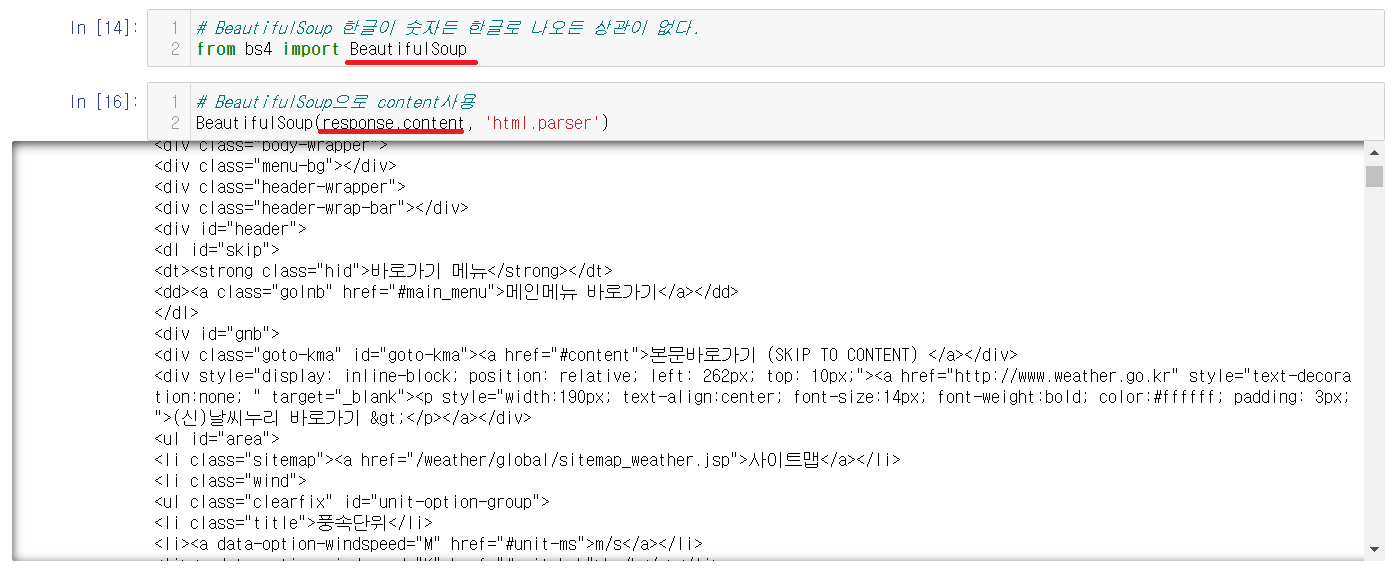
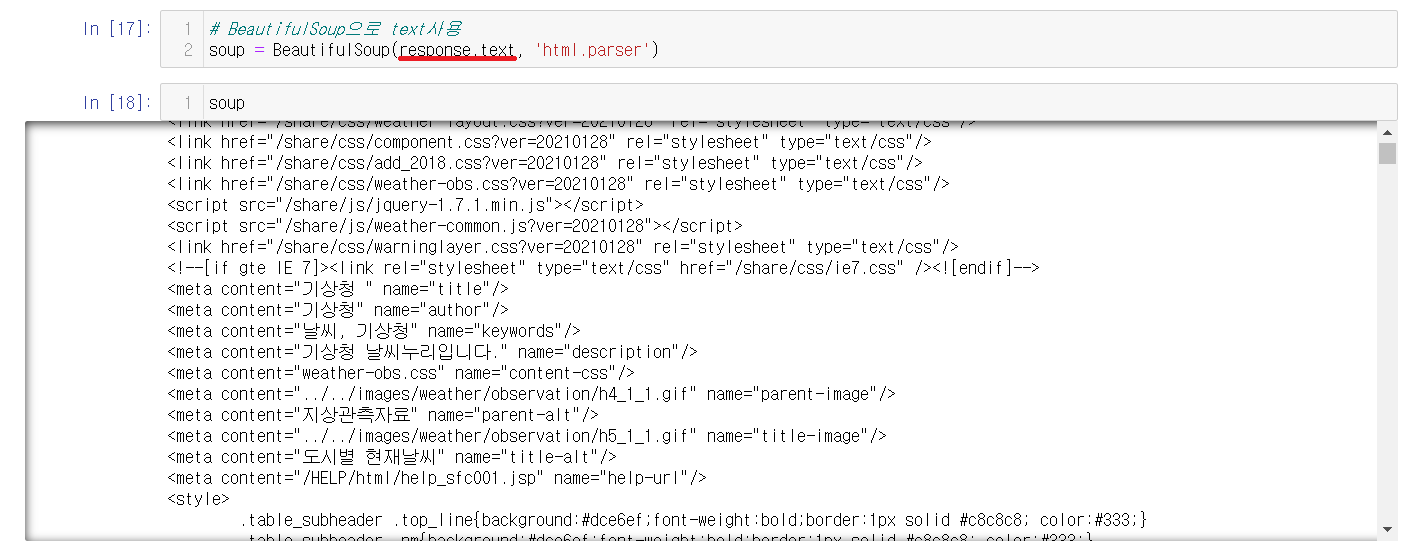
※ BeautifulSoup을 사용한 content, text
BeautifulSoup에서도 사용이 가능하다.
2-3) 날짜 데이터 크롤링
찾아야할 데이터: 동네 이름, 온도, 습도
2-3-1) 지점 검사하기
기상청에 들어가서 지점 마우스 오른쪽 클릭으로 검사를 눌러서 들어가서 웹 페이지 구성을 본다.
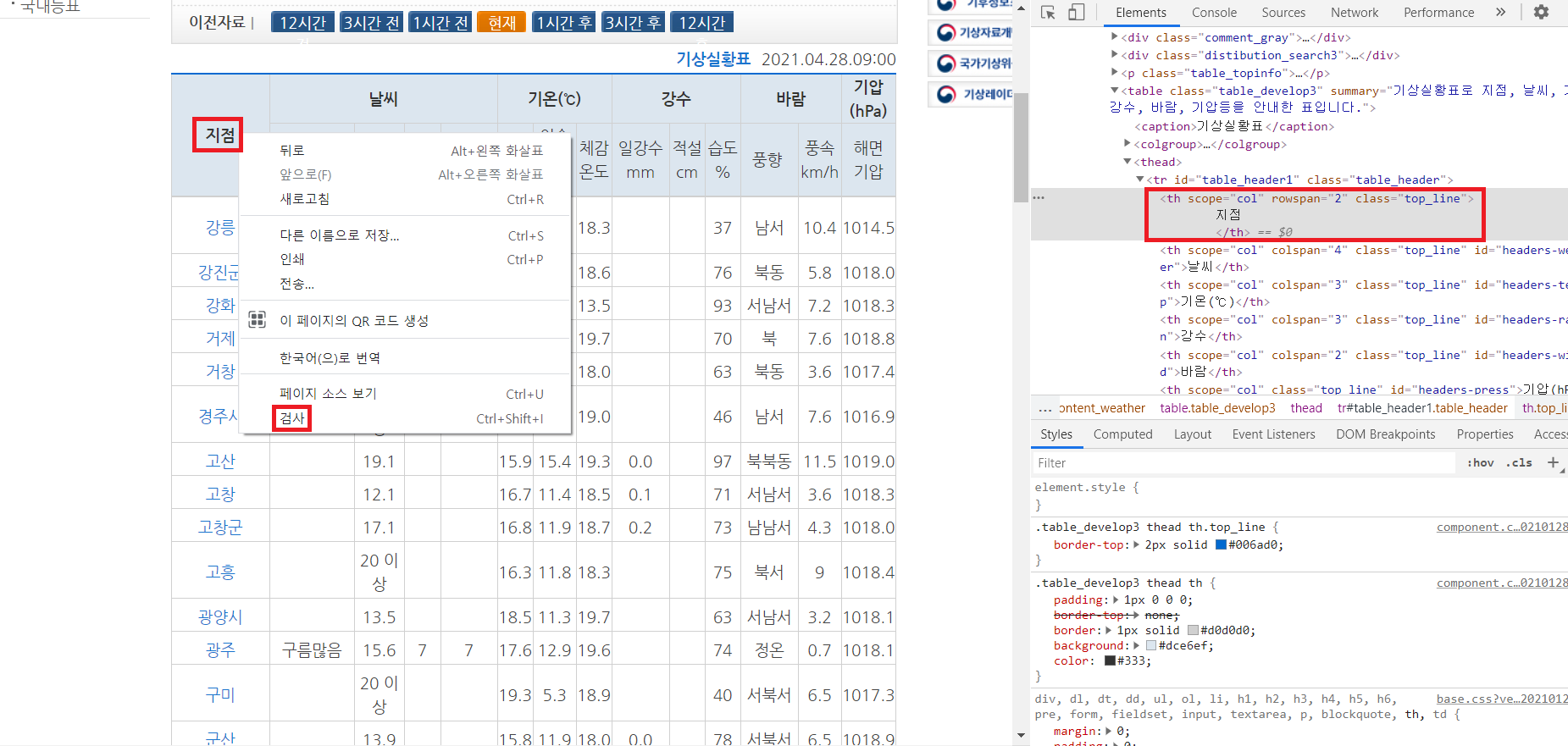
지점이 동네 이름을 나타내고있기에 지점을 눌러서 검사에 들어가서 확인한다.
2-3-2) find를 사용할 부분 찾기
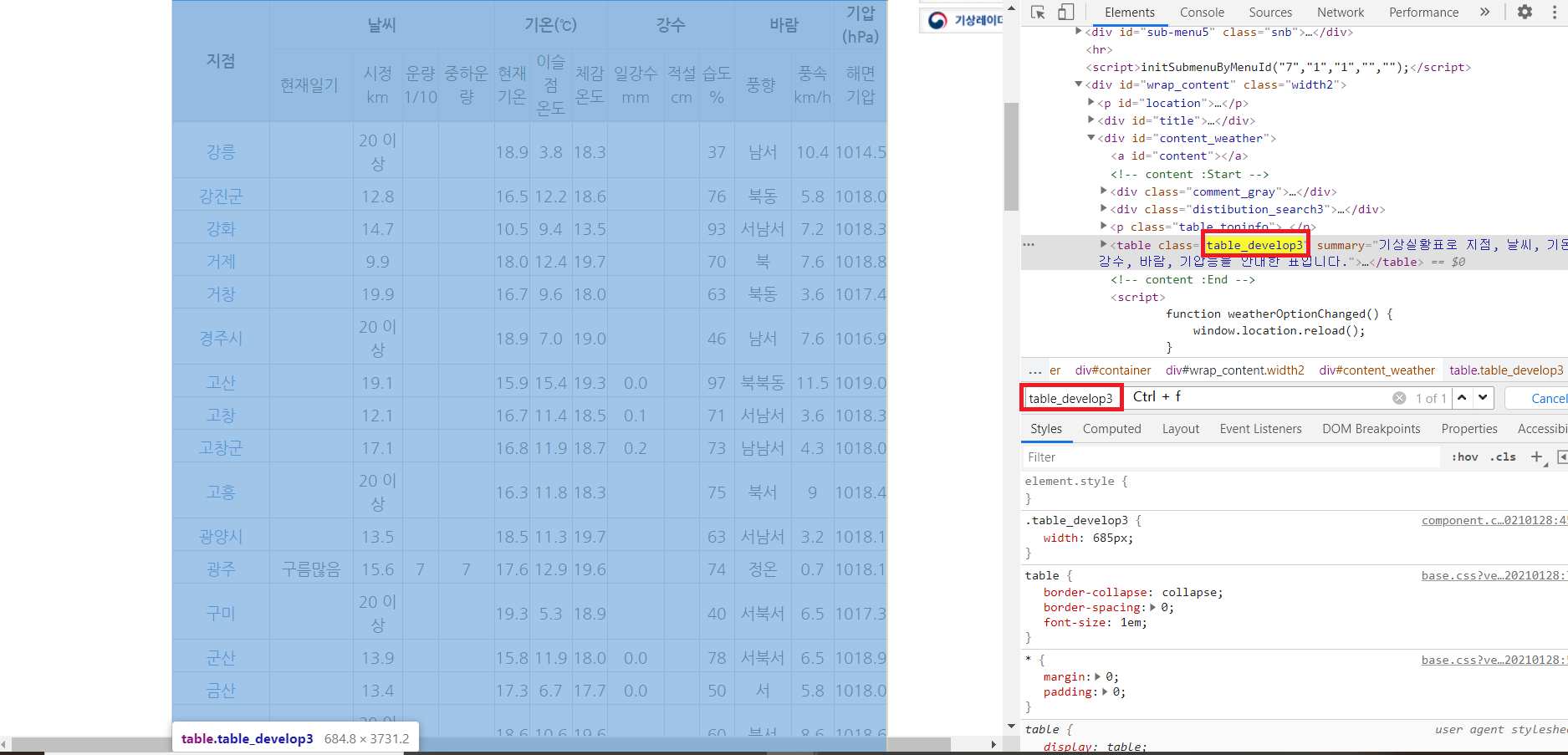
find를 찾기 위해서 구조들을 보면서 살펴보니 table_develop3가 하나만 있다는 것을 알 수 있다. 하나뿐이기에 find를 이용해서 찾을 수 있다.
2-3-3) 기상청 내용불러오기
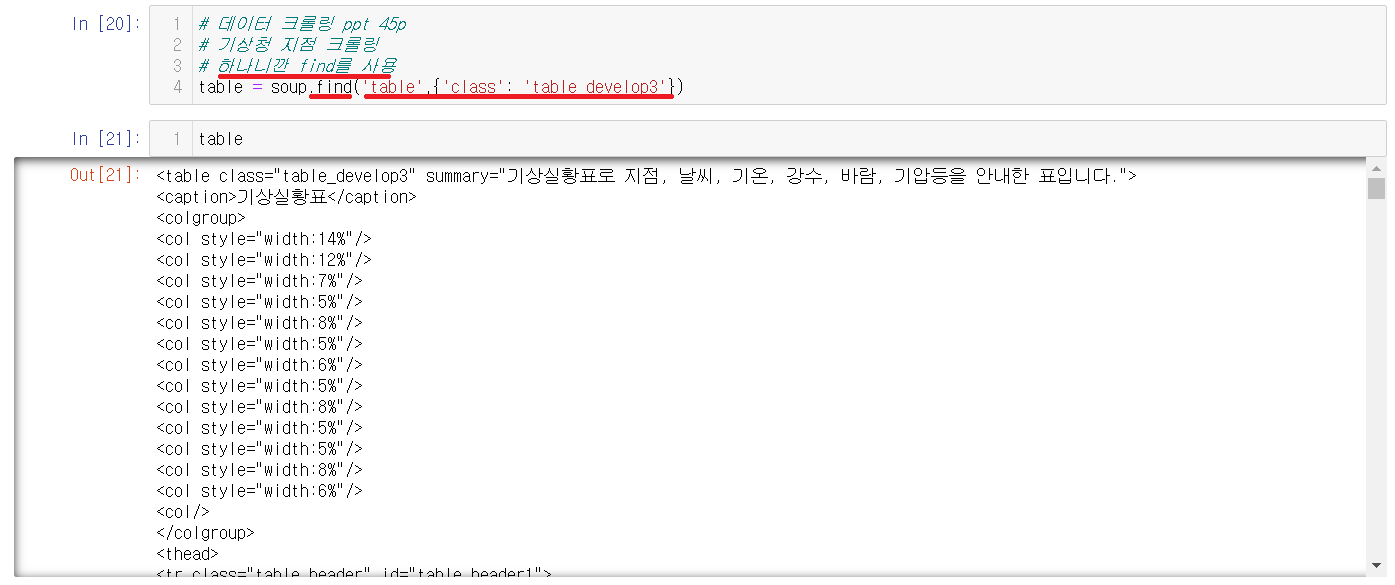
find를 통해서 기상청에 현재 날씨를 불러왔다. 하지만 여러값들이 섞여있어서 보기가 어려운 것을 확인할 수 있다.
2-3-4) 동네 이름을 찾아보기
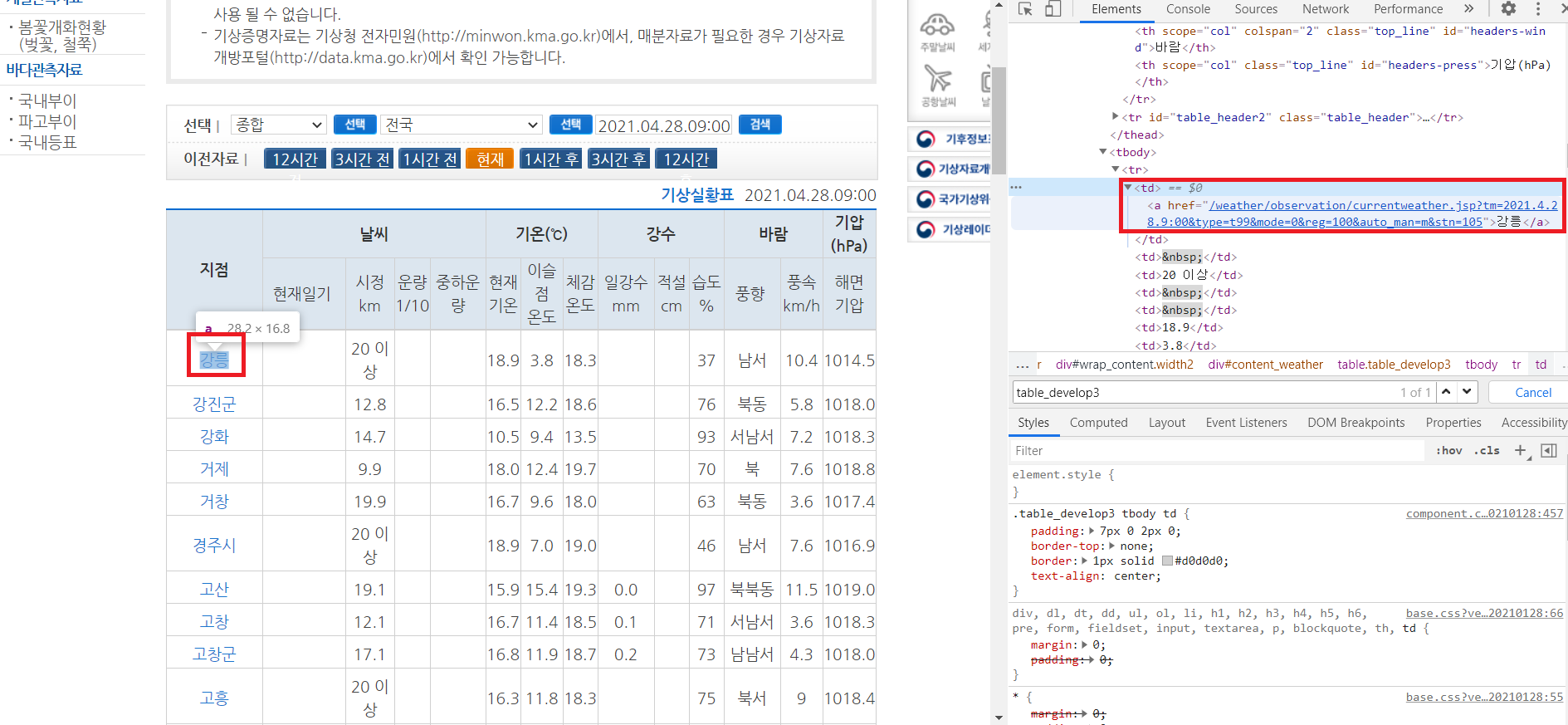
안에 내용이 너무 많아서 뭔지 모르니깐 강릉을 눌러서 어디에 들어있는지 확인해본다. 찾아보니 <a></a>안에 강릉이 들어있는것을 확인할 수 있다. 이제 동네 이름이 어디에 위치한지를 찾았다.
2-3-5) 내용안에서 tr태그를 찾기
동네 이름은 td에 위치하고 있고 td의 상위에는 tr이 위치하고 있다. 우리는 동네 이름말고도 온도, 습도도 찾아야하기에 모든 tr을 조회해본다.
2-3-5-1) 첫번째: findAll
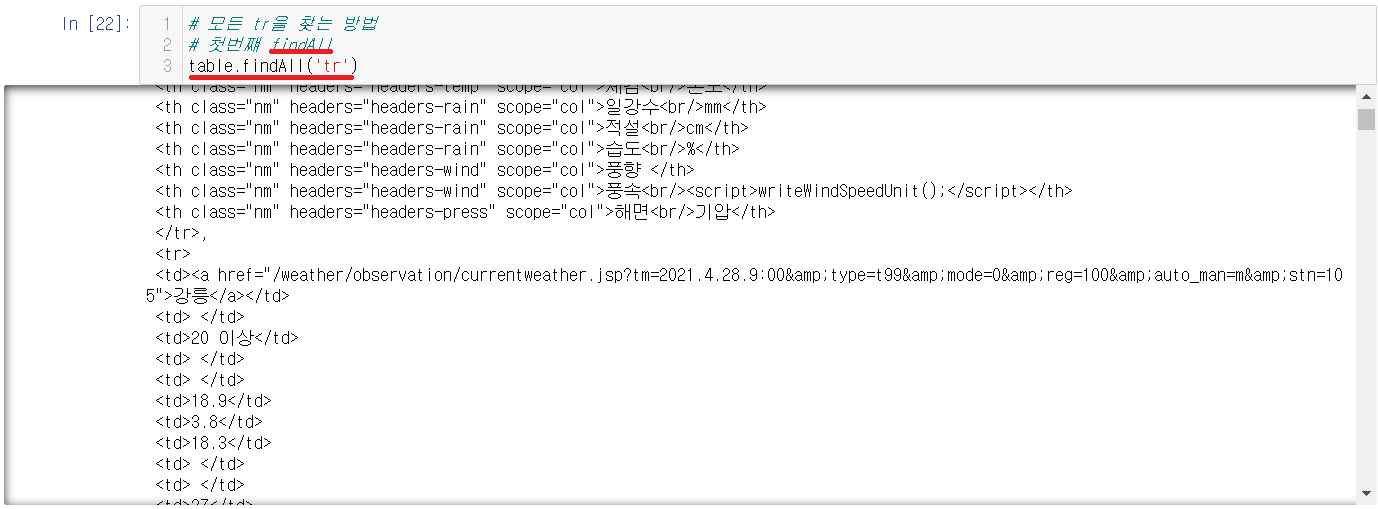
모든 것을 찾을 때, 사용한다던 findAll을 사용한다. 하지만 다른 방법으로도 찾을 수 있다.
2-3-5-2) 두번째: find_all
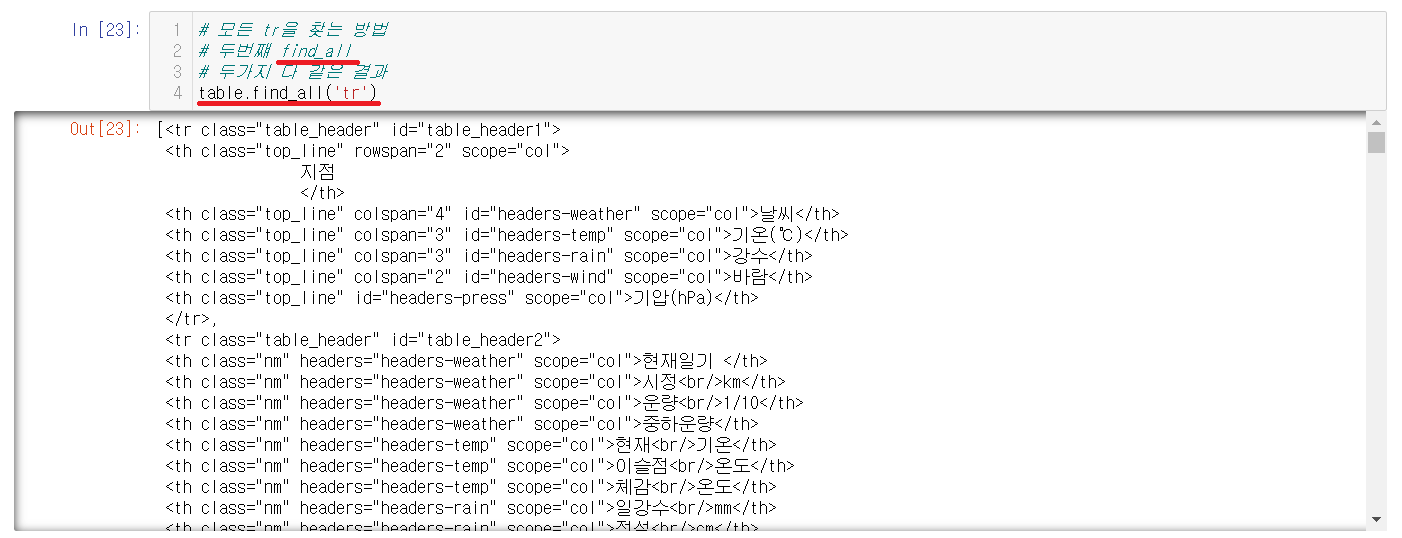
find_all로도 찾을 수 있다. 둘의 결과는 같으니 findAll이나 find_all 아무거나 사용해도 무방하다.
2-3-6) td로 찾기
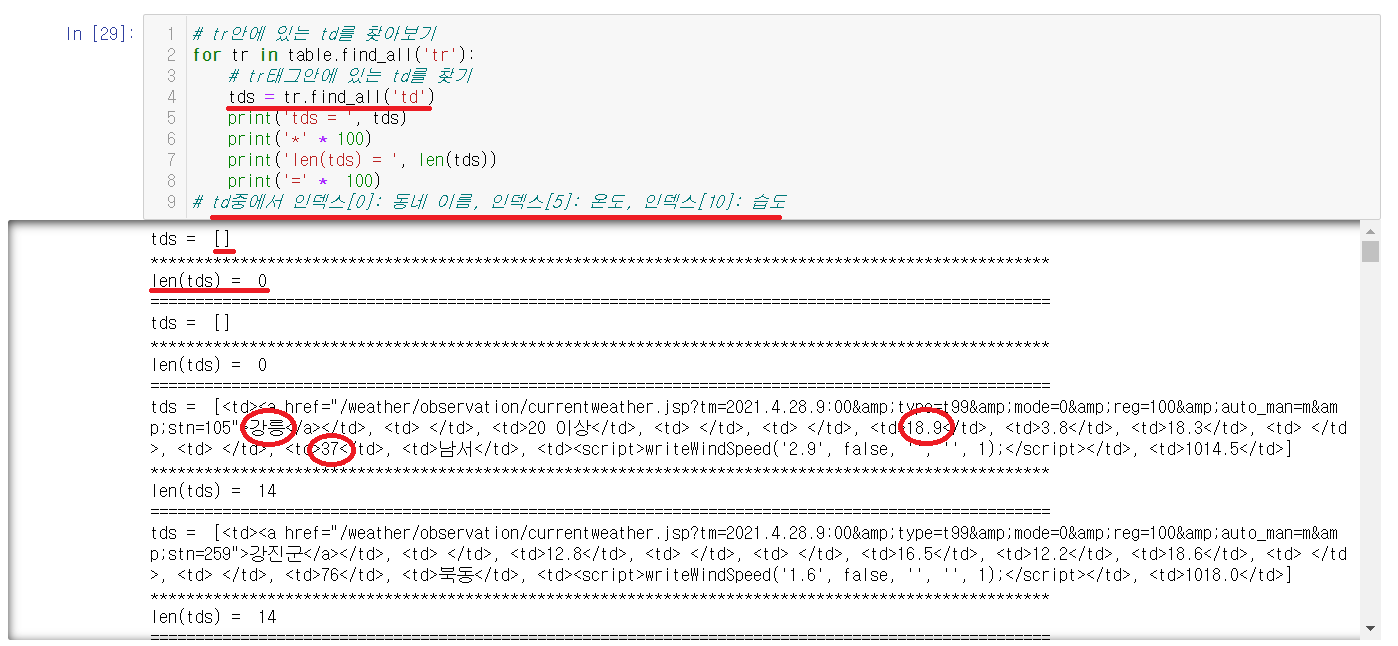
tr태그안에 위치한 td태그의 내용들을 출력해본다. 출력을 해보니 td중에서 인덱스[0]: 동네 이름, 인덱스[5]: 온도, 인덱스[10]: 습도가 위치한 거을 확인할 수 있었다. 처음 시작하는 td태그안에는 아무것도 들어있지않음도 확인할 수 있다.
2-3-7) 원하는 데이터 크롤링하기

리스트가 비어있는 td태그안에 인덱스를 출력하려고하면 오류가 난다. 그렇기에 if문을 사용하여 td리스트안에 아무것도 들지않은 것을 제외하여서
원하는 결과
인덱스[0]: 동네 이름, 인덱스[5]: 온도, 인덱스[10]: 습도를 지정하여서 출력할 수 있다.
2-4) 날짜 데이터 크롤링을 다른 방법으로 해보기
2-4-1) tr태그 출력하기
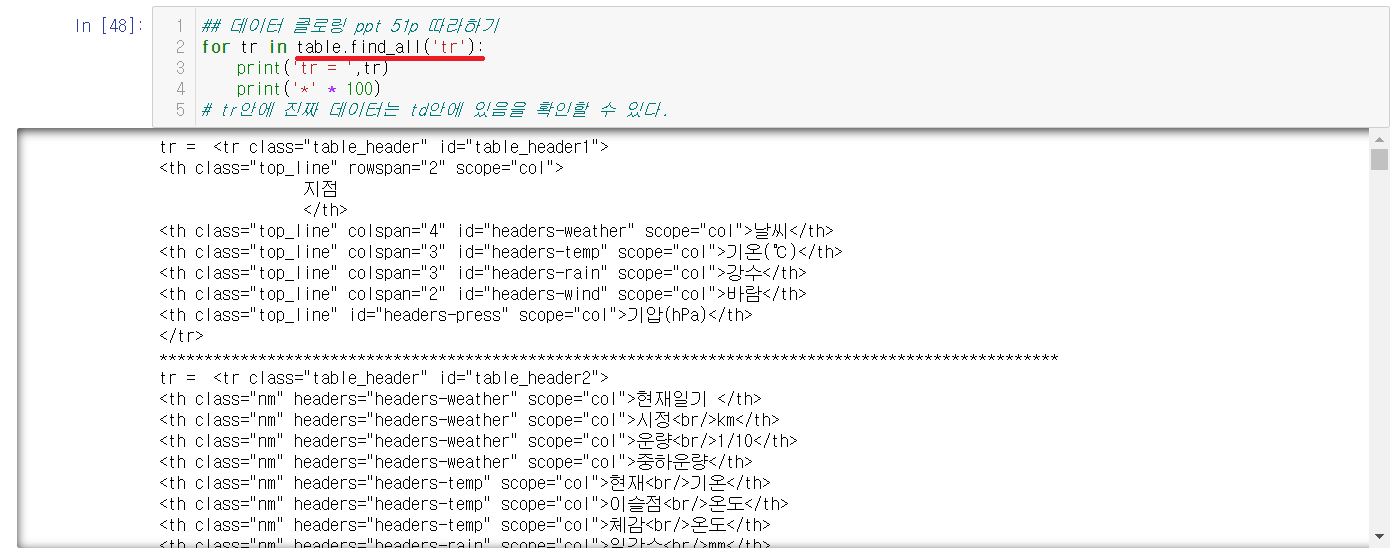
2-4-2) td태그 출력하기
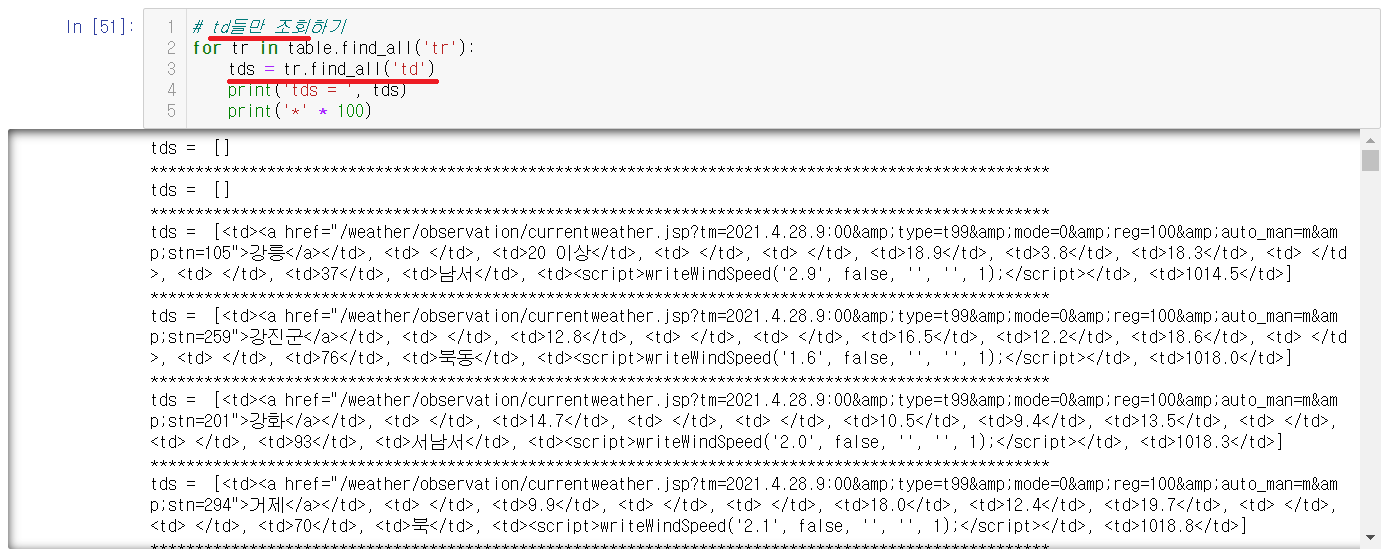
tr태그안에 정보를 들고있는 td만 출력해본다.
2-4-3) a태그 확인하기
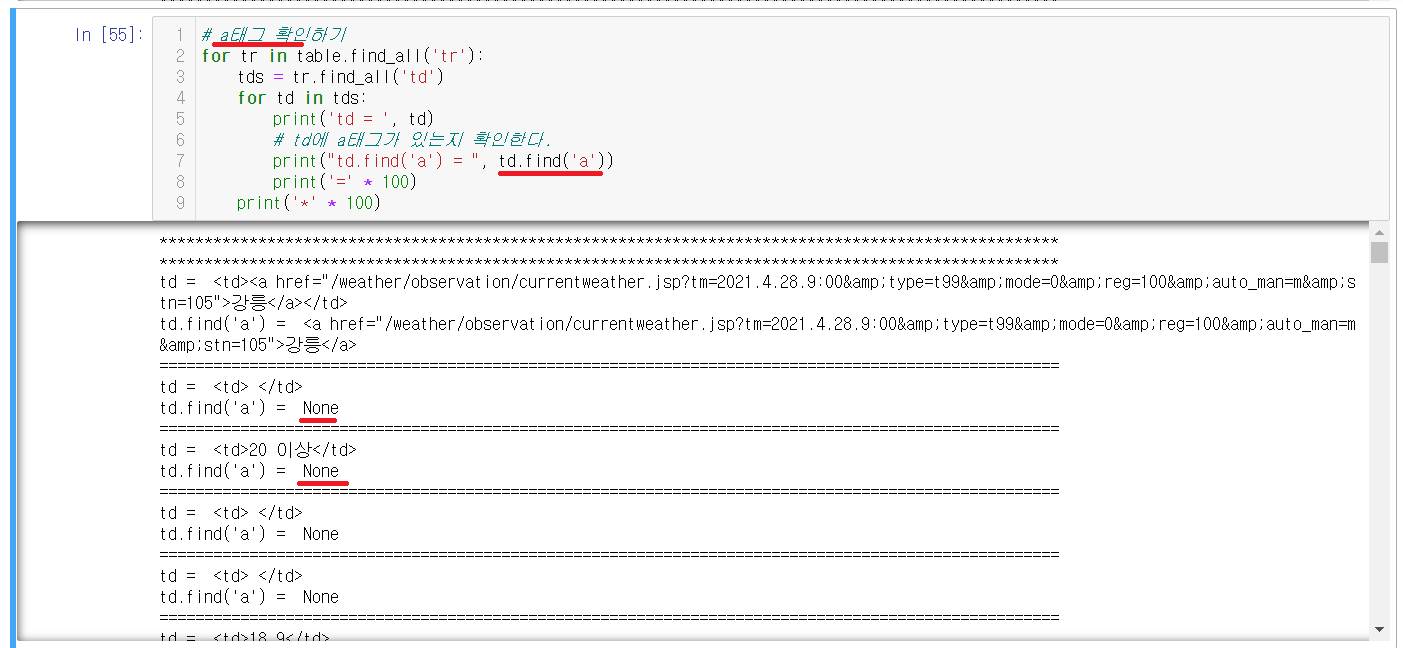
위의 방법과 조금 다른 점은 a태그를 추가해서 a태그 안에있던 정보를 찾을려고 하는 것이다. find를 이용해서 a태그를 찾아주는데 이 때 print("td.find('a')", td.find('a')) 이런식으로 적어주어야한다. 밖에는 ""(큰 따음표), 안에는 ''(작은 따음표)를 이용해주어야 오류가 나지않으니 유의해야한다.
밑에 출력된 값을 확인해보면 None값도 있음을 확인할 수 있다.
2-4-4) None을 이용하기
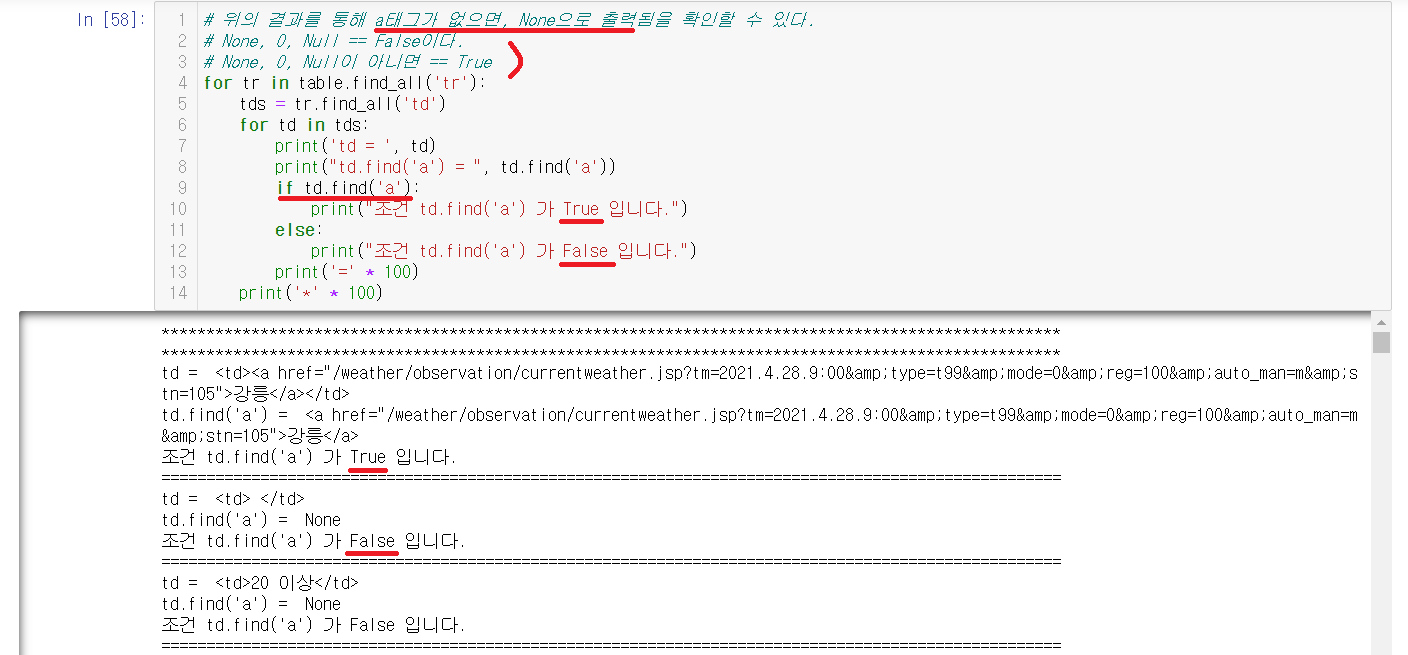
None을 이용하여서 출력을 해줄려고한다. 그전에 먼저 None에 대해서 알아야한다.
| False | True |
| None, 0, Null | None, 0, Null이 아닌 것 |
위의 표와 같이 None은 False의 값을 갖고있다. 표를 참고하여서 사진을 보면 if문을 통해 a태그가 들어있다면 True, a태그가 들어있지않으면 False로 나타낸 것을 확인할 수 있다.
2-4-5) True를 이용해서 내용 출력하기
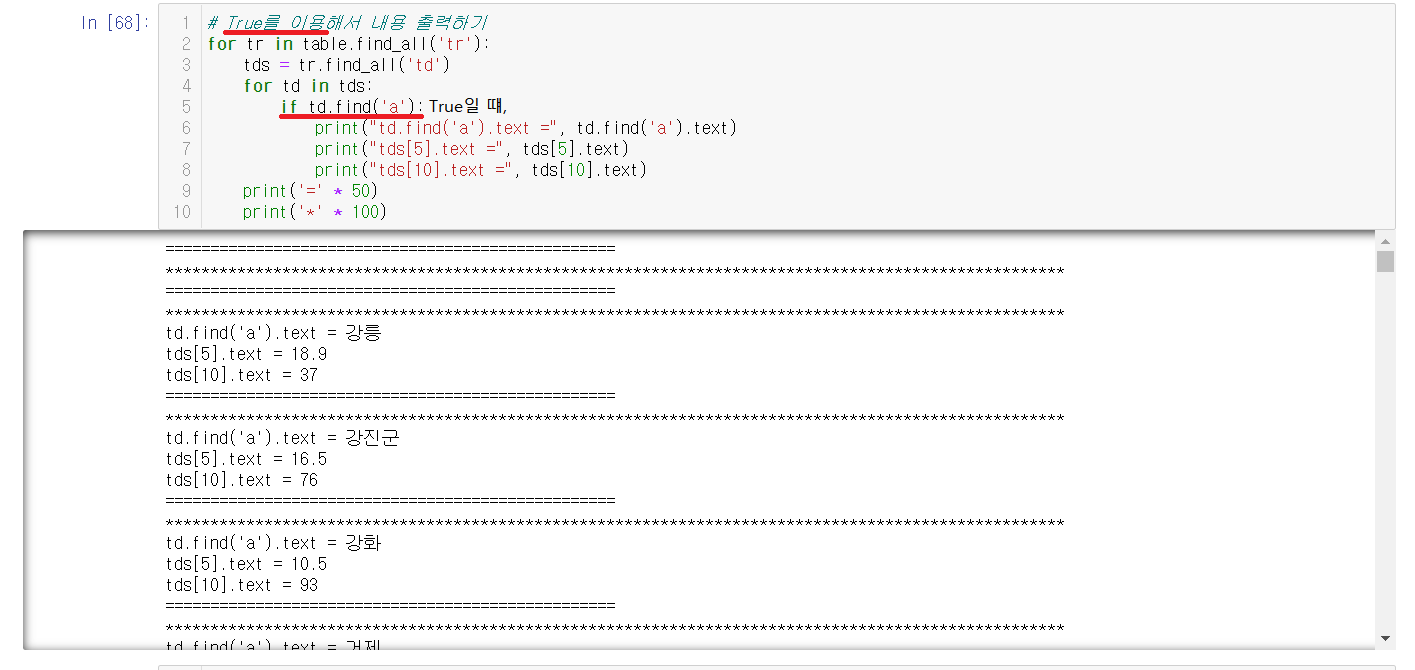
True값이 a태그를 포함하는 것을 위에서 확인했으니, 이를 이용한다.
a태그가 들어있을 때, 원래 목표했던 찾고자했던 데이터
인덱스[0]: 동네 이름, 인덱스[5]: 온도, 인덱스[10]: 습도를 print안에 출력해준다. 결과를 보면 원하는 데이터가 출력되어있음을 확인할 수 있다.
찾고자했던 데이터를 찾는 것은 동일하지만, 쓰이는 함수들이 달라서 서로를 참고하여 본인에게 맞는 방법을 찾아가는 것이 좋다.
2-5) 데이터 파일에 저장하기
2-5-1) data에 데이터 넣기
시작전에 data = [ ] 해서 빈 리스트를 만들어준다.
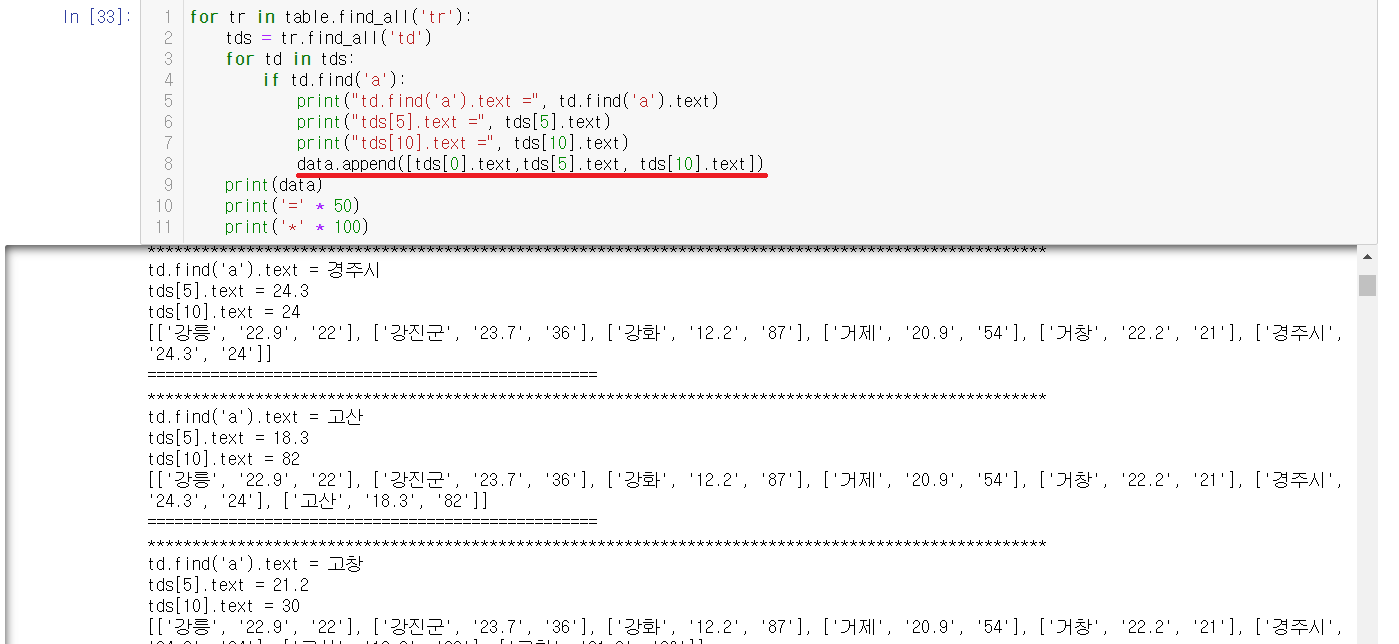
append를 사용해서 data리스트안에 원하던 데이터를 넣어준다.
2-5-2) 데이터 사이를 구분하기
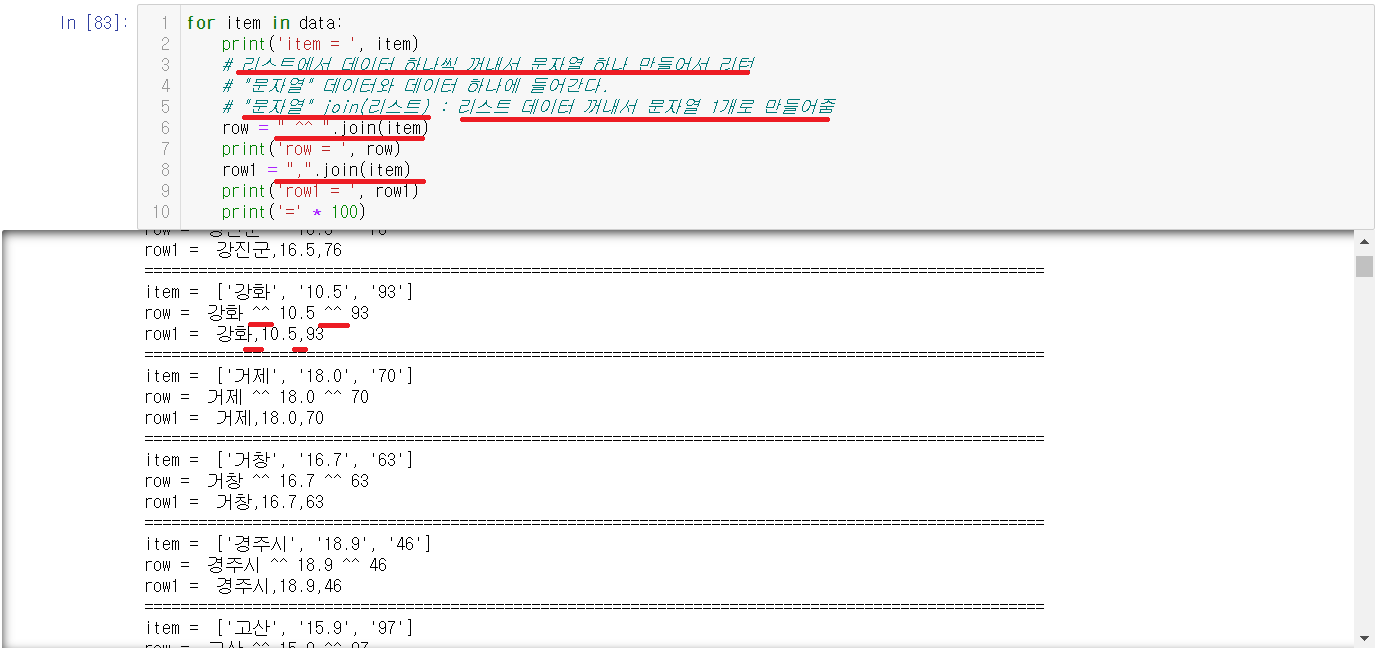
Join을 이용하여서 리스트안에 있는 데이터들 사이에 문자열들을 사이사이마다 넣어줄 수 있다. 위의 예씨는 ^^과 ,를 나누어보았는데 결과값에서 확인할 수 있다.
2-5-3) 파일 내용을 저장하기
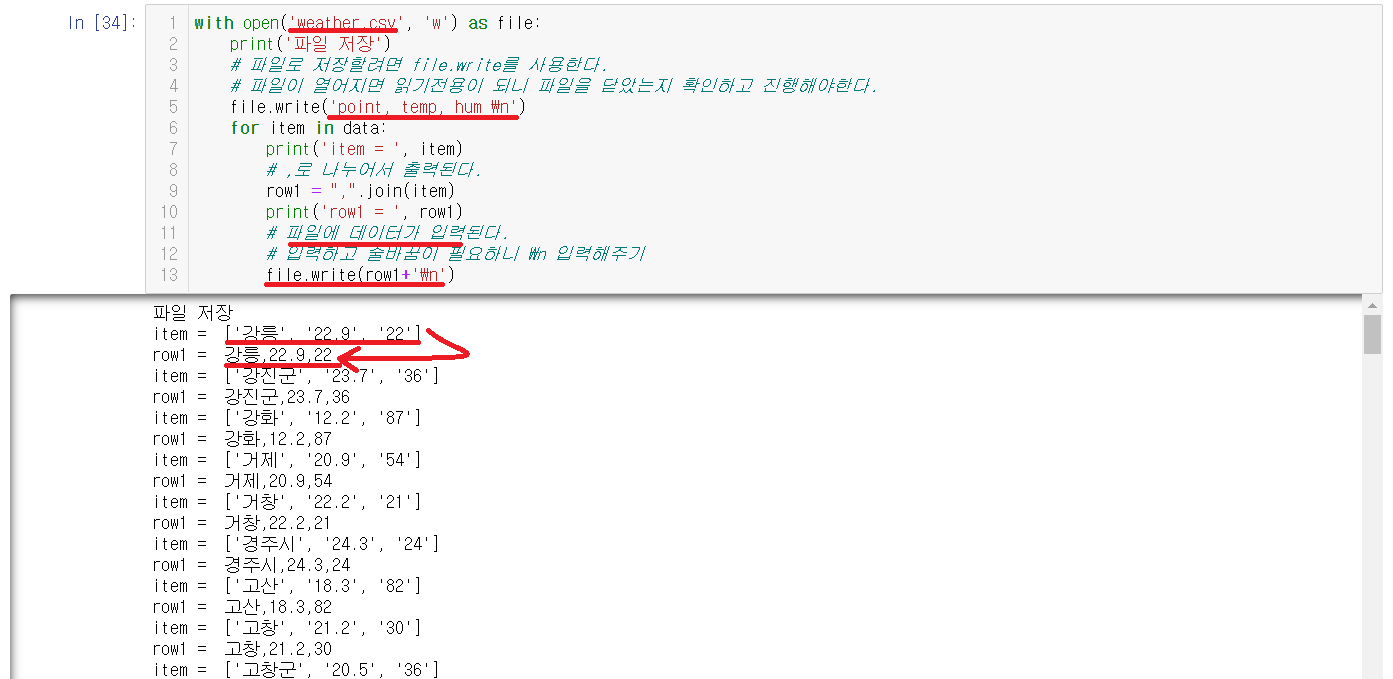
with opne(weather.csv','w') as file: 의 의미는
1) weather.csv라는 파일이 없으면 생성
2) weather.csv라는 파일이 있으면 내용을 다 지우기
현재 weather라는 파일이 없으므로 생성이 될 것이다. 생성되는곳은 현재 jupyter notebook이 실행되는 곳에 저장된다.
file.write로 파일에 내용을 입력할 수 있는데 'point, temp, hum \n'으로 위에 header를 입력한다.
그 밑에 위에서 ,로 나누어둔 data를 for문으로 file.write으로 파일에 입력해준다.
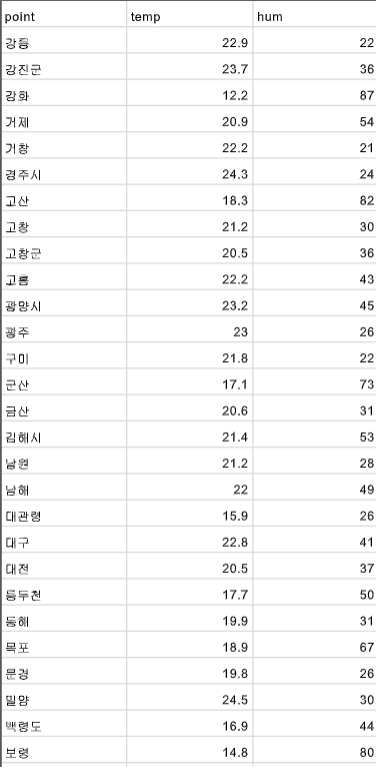
실행되고있는 폴더에 직접들어가서 파일을 열어보면 원하는 데이터들이 입력되어있음을 확인할 수 있다.
원하는 결과
동네 이름, 온도, 습도2-6) 데이터로 불러오기
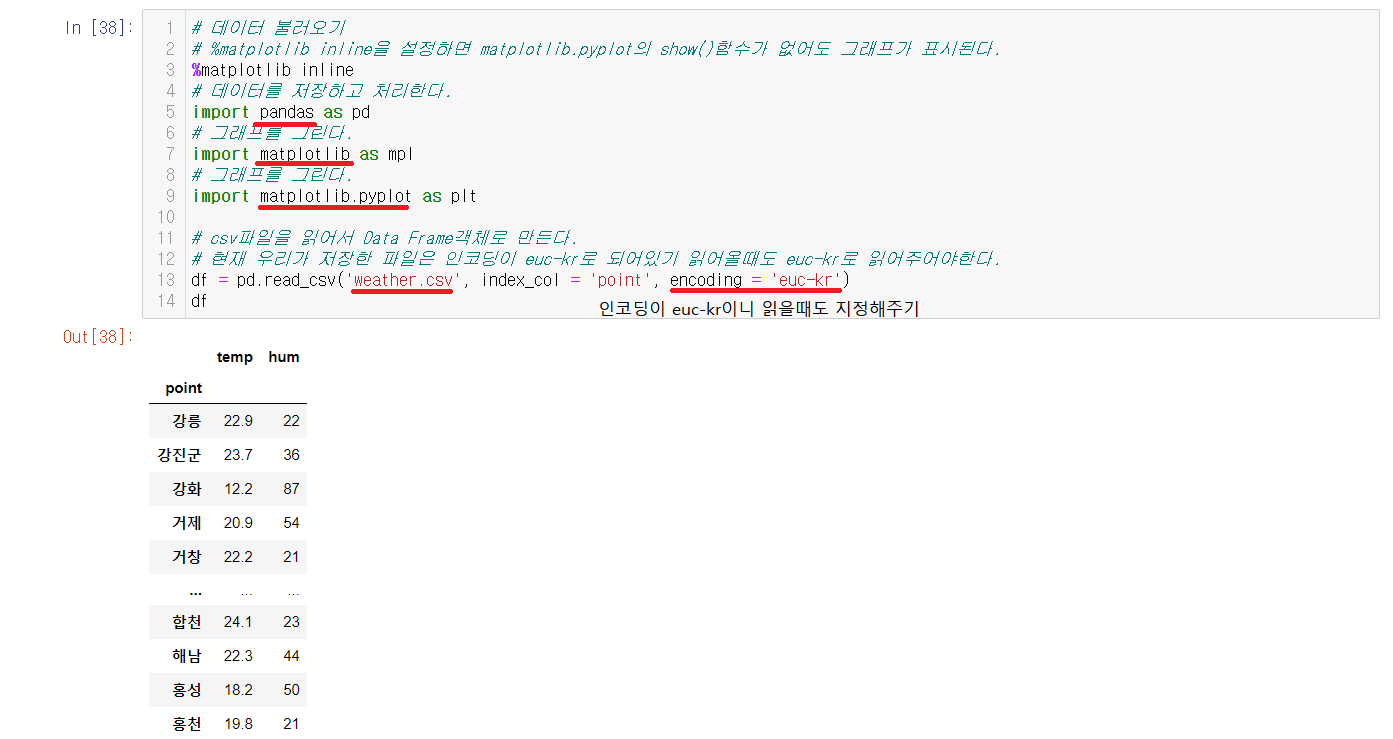
저장한 파일을 pandas를 이용해서 DataFrame으로 객체를 생성한다. 여기서 df변수에 encoding을 적어주지아니면 utf-8오류가 나는데 현재 우리는 파일을 euc-kr로 저장되어있어서 불러올때는 encoding해서 불러와야한다.
2-7) 특별시를 지정해서 불러오기
pandas를 이용해서 DataFrame으로 객체를 생성했는데 DataFrame에서는 loc 속성을 사용할 수 있다. loc는 특정 인덱스의 데이터를 가져올 수 있다. 이를 이용해서 특별시를 지정해서 불러오려고한다.
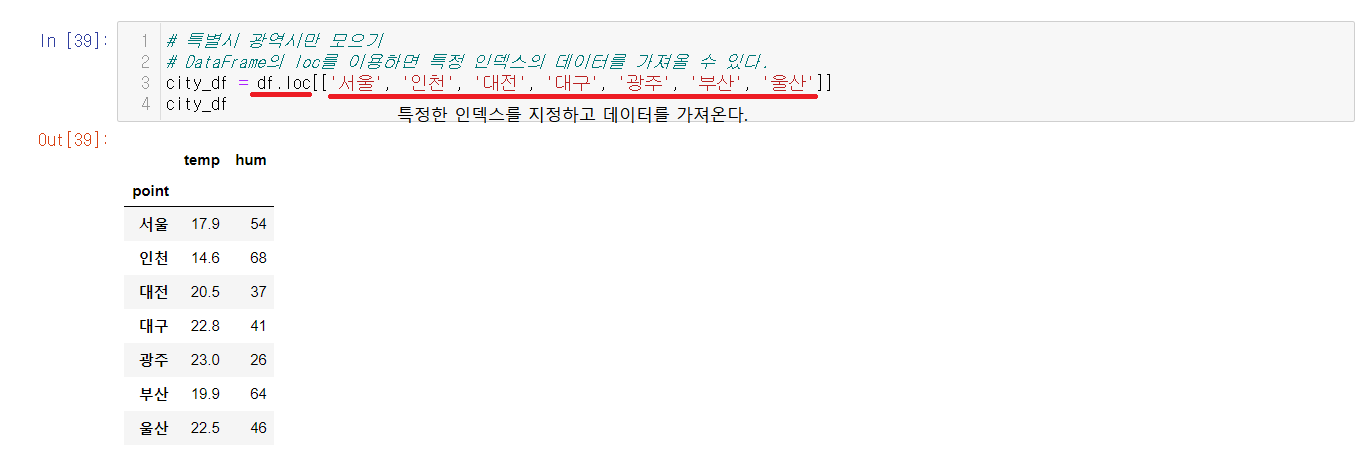
loc를 이용하여 특정한 인덱스들을 지정해주고 그 데이터를 불러올 수 있다.
※ loc에 인덱스를 하나만 사용, 다중 사용

loc를 하나만 지정하면 해당된 인덱스만 데이터로 가져온다.
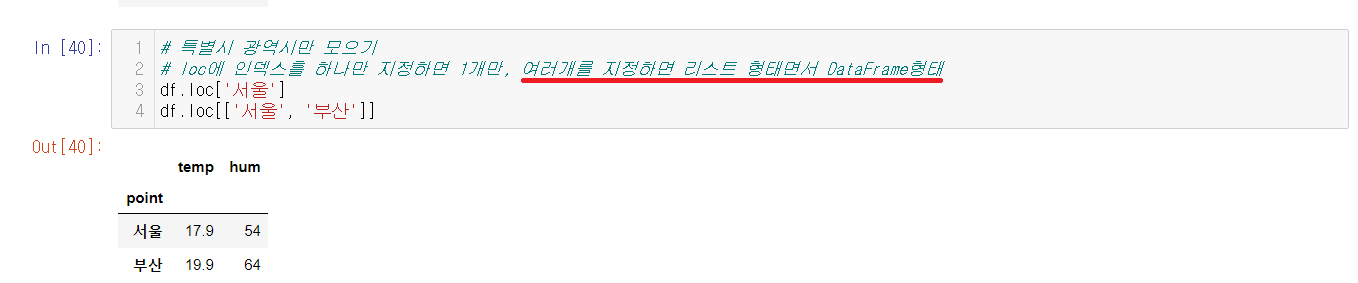
인덱스를 다중으로 입력해주면, 인덱스가 하나만 쳤을 때와는 달리 데이터가 아닌 DataFrame 형태로 나오게 된다.
2-8) 그래프 만들기
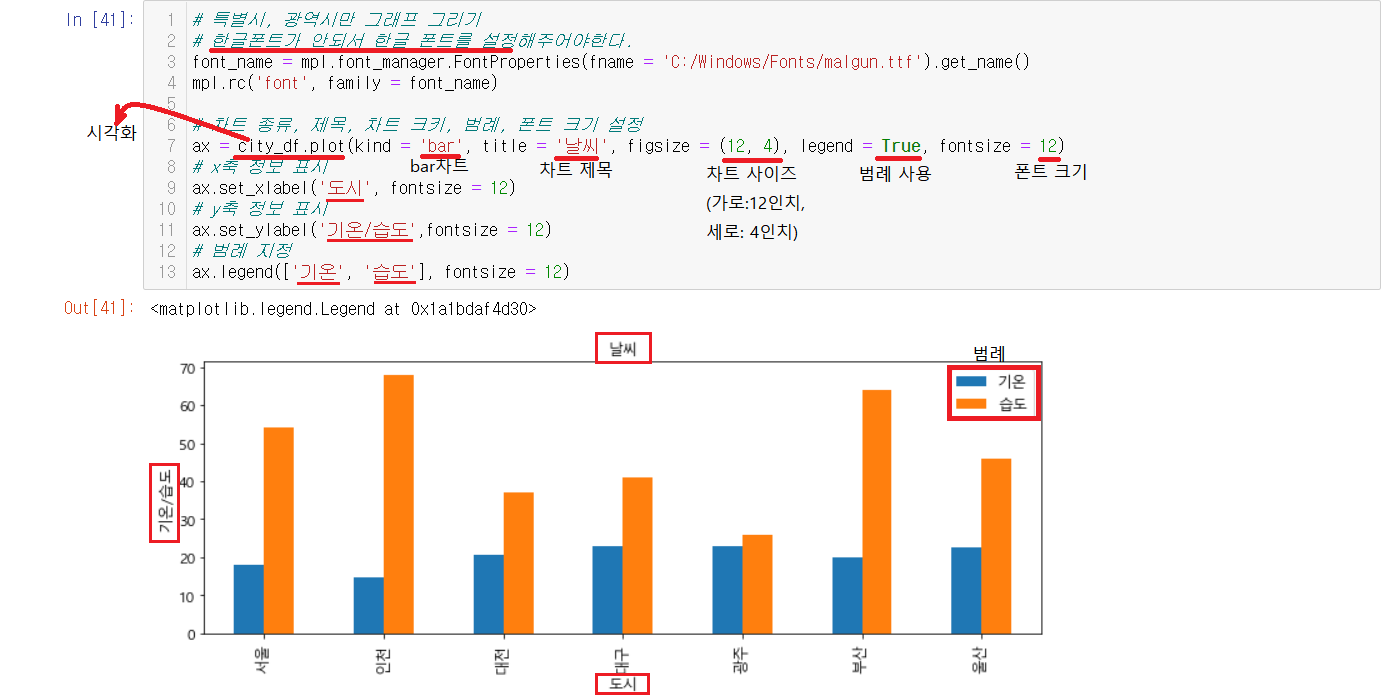
DataFrame은 그래프로 나타낼 수 있다. 먼저 주의해야할 점은 한글폰트가 설정되지않아서 한글폰트를 설정해주어야 실행이 가능하다.
plot메소드가 DataFrame은 그래프로 나타낼 수 있도록 시각화해주며 메소드안에서 디테일한 부분들을 설정할 수 잇다.
디테일을 설정 후, x축의 제목, y축의 제목, 범례등을 나타내주면 완성된다. 범례는 리스트로 넣어주어야한다.
이렇게 시각화까지하면 마무리된다. 기상청 홈페이지에서 데이터를 크롤링하고 그 데이터를 csv파일로 저장해주고 데이터를 불러와서 시각화까지의 과정을 마쳤다.
3) Selenium을 이용한 크롤링
Selenium은 웹을 테스트하는데 이용하는 프레임워크이다. 이번에는 Selenium을 이용해서 크롤링을 해보고자한다.
3-1) Selenium 설치
실행하기전에 먼저 설치하는 과정이 필요하다. 현재 우리는 크롬에서 크롤링을 하고 있는데 Selenium 역시 크롬과 연관이 있다.
3-1-1) 크롬 버전 확인
크롬 드라이버를 설치해주어야하는데 드라이버를 설치하기전에 현재 크롬의 버전을 알아야한다.
크롬 버전을 확인하는 방법은 크롬창에서 Chrome://version 을 입력하면 밑에와 같이 창이 뜬다.
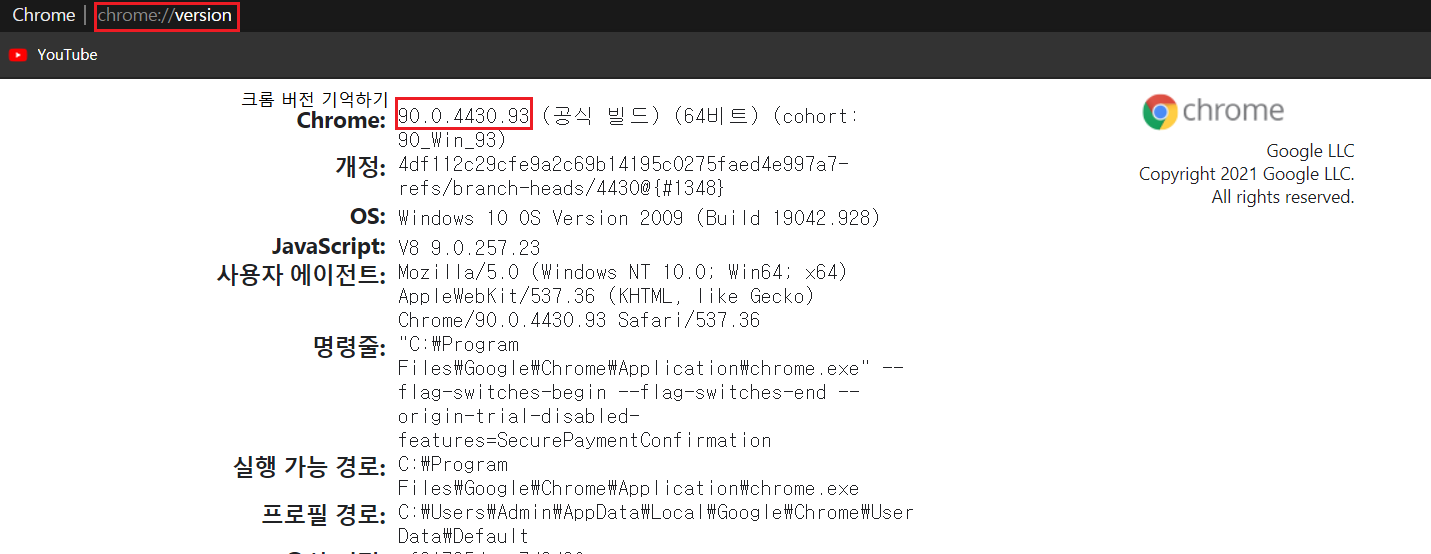
현재 크롬 버전은 99.0.4430.93 임을 확인할 수 있다. 크롬 버전을 기억해야지 맞는 버전의 드라이버를 설치할 수 있으니 복사해놓는게 좋다.
3-1-2) 크롬 드라이버 설치
sites.google.com/a/chromium.org/chromedriver/downloads
Downloads - ChromeDriver - WebDriver for Chrome
WebDriver for Chrome
sites.google.com
크롬 드라이버로 들어가서 아까 확인했던 크롬 버전과 맞는 버전을 깔아준다.
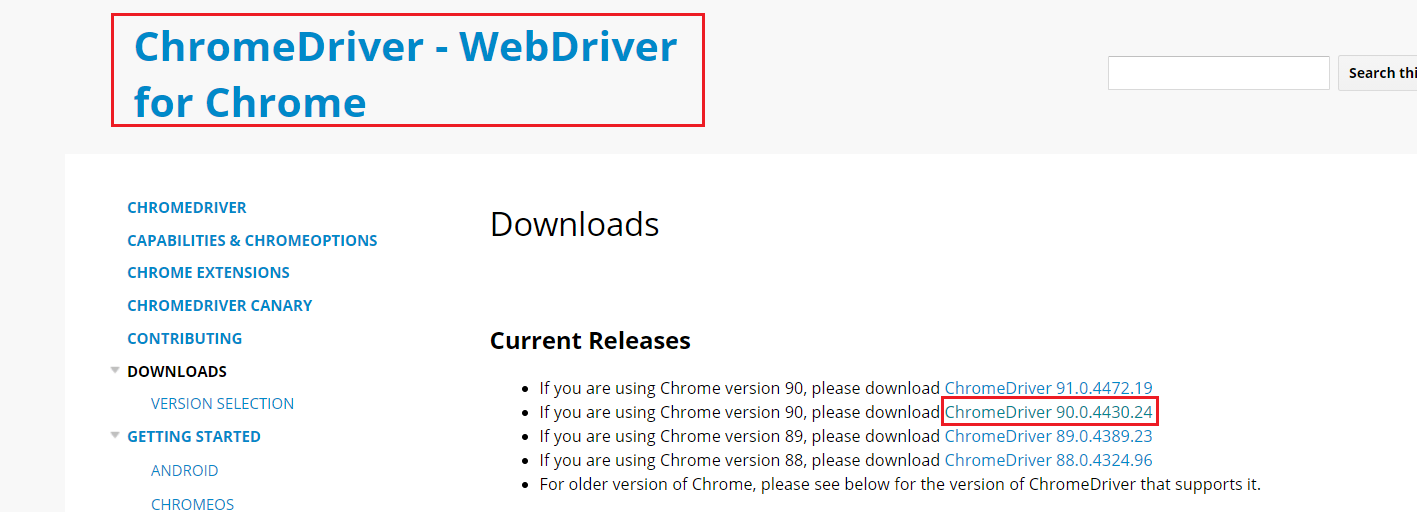
맞는 버전을 누르면 다운로드 경로가 나온다.
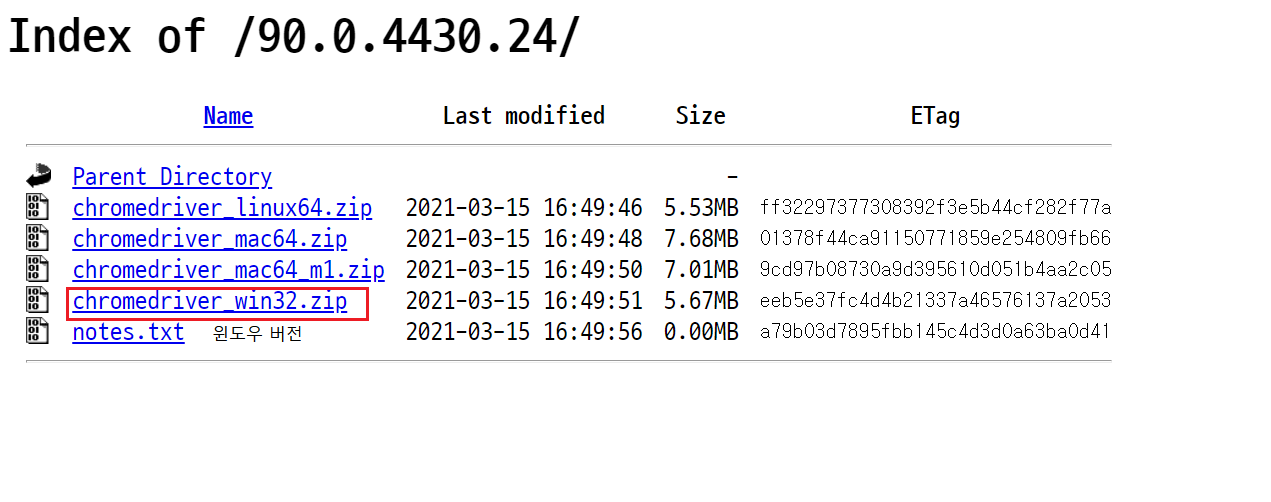
각자에게 맞는 버전을 설치하면되는데 현재 윈도우를 사용해서 윈도우 버전으로 다운받았다.
3-1-3) 경로 설정하기
다운받은 파일의 압축을 풀어줘야하는데 이 때의 압축푸는 장소를 잘 기억해야한다. 이 압축을 푼 장소에서 jupyter notebook을 실행해서 진행해야한다.
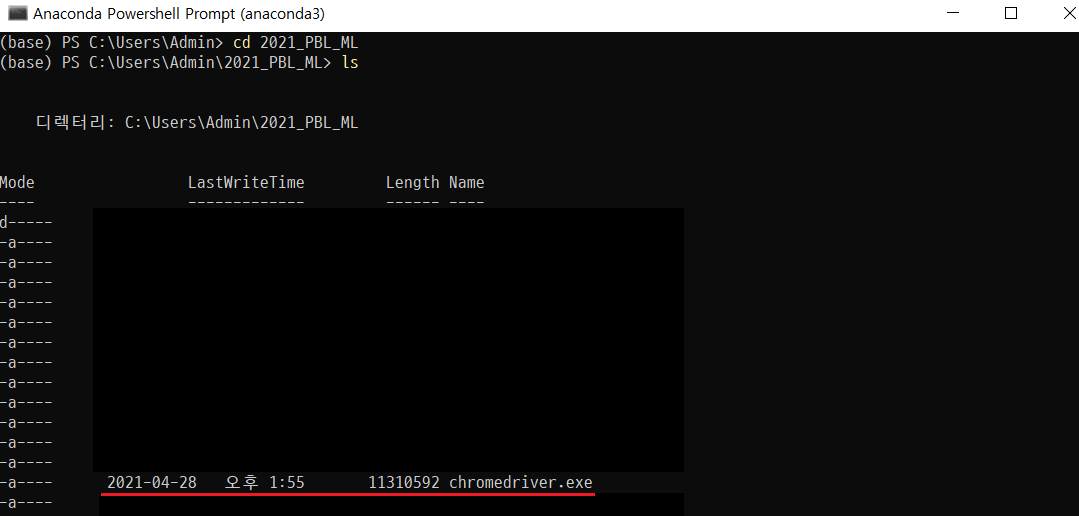
Anaconda prompt를 실행하여서 파일의 압축을 해제한 곳에 파일이 들어갔는지를 확인한다. 확인해보니 들어있다. 여기서 jupyter notebook이라고 입력해서 jupyter notebook을 해당 폴더안에서 실행시켜준다.
3-1-4) Selenium 설치하기

pip앞에 !(느낌표)도 적어주어야 진행된다. cell을 실행시키면 Selenium가 설치가 된다.
3-2) 크롬 드라이버 로드하기
Selenium설치했으니 크롬 드라이버를 로드한다. 위에 설치부분에서 폴더를 기억하고 압축을 푼 그것에서 jupyter notebook을 실행시켰는데 이에대한 이유는 크롬 드라이버를 로드하기 위해서이다.
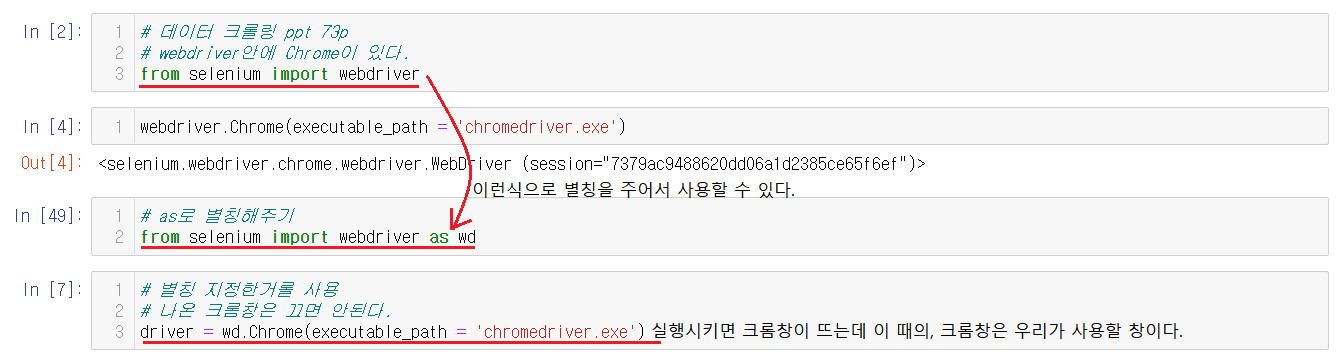
from selenium import webdriver 혹은 from selenium import webdriver as wd 로 별칭을 주어서 사용할 수 있다.
driver = wd.Chrome(executable_path = 'chromdriver.exe')라는 문구로 크롬창을 실행하는데 이는 우리가 사용할 크롬창이다.
열려있는 크롬창을 닫아버리면 밑에있는 문장들을 실행할 수 없으니 혹시 닫았다면 다시 한번 실행시켜서 크롬창을 켜주어야한다.
3-3) 네이버 검색하기
우리가 직접 마우스로 누르는게 아니라 jupyter notebook에서 코드를 통해서 실행시킬 수 있다.
3-3-1) 네이버 들어가기

driver.get()을 통해서 원하는 사이트에 들어갈 수 있다. 위의 코드를 실행하면 켜졌던 크롬창에서 네이버가 실행되는 것을 확인할 수 있다.
3-3-2) 네이버에서 검색 내용 입력하기
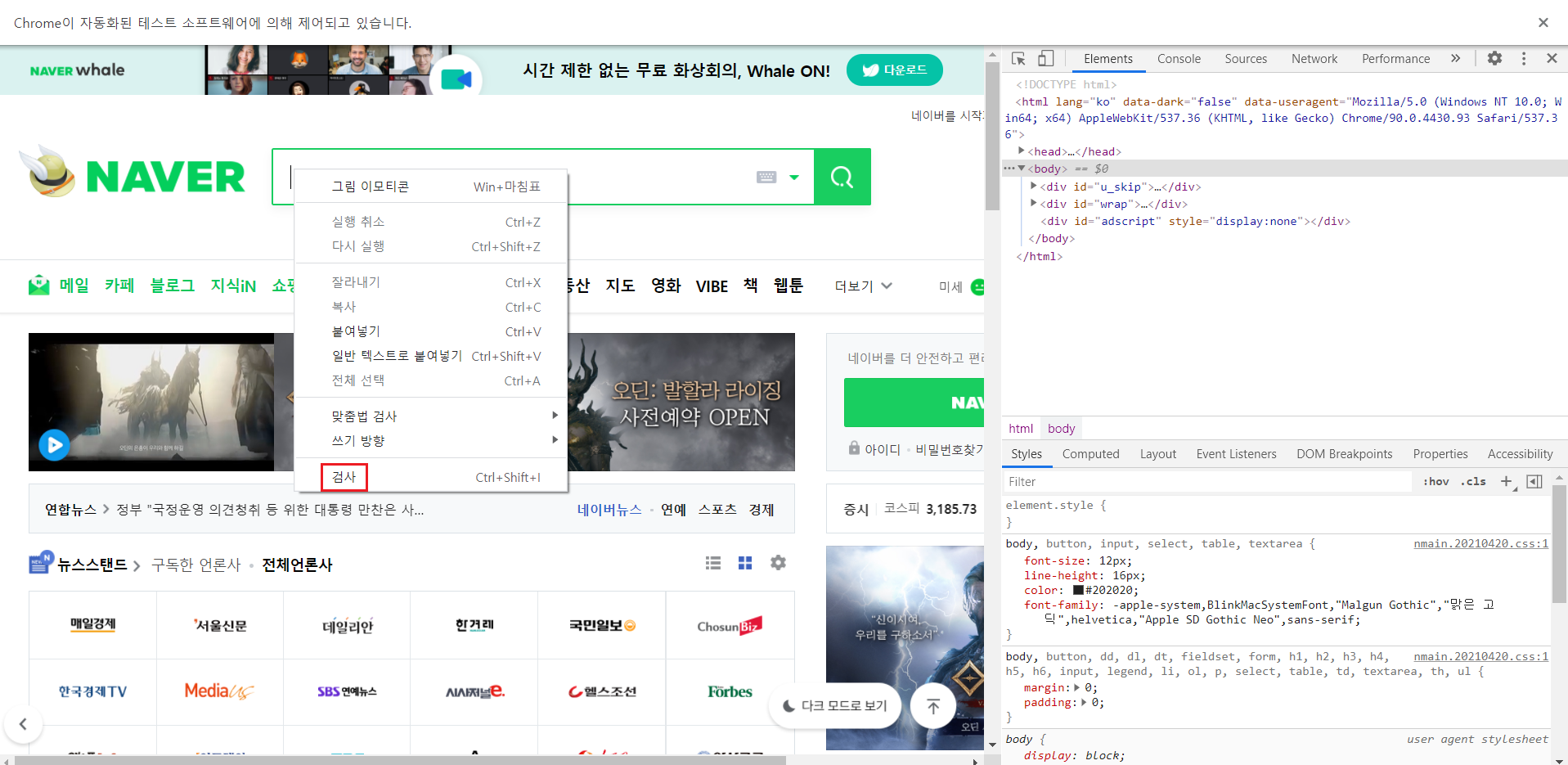
검색어를 입력할 곳을 누르고 검사를 진행한다. 검사에서 예전과 같이 find로 찾을 것을 찾는다.

find로 입력할 것은 query이며, 검색을 진행할 내용은 '윤여정'이다. 대신 입력하기위해서 send_keys()를 이용해서 내용을 적어주고 실행시킨다.
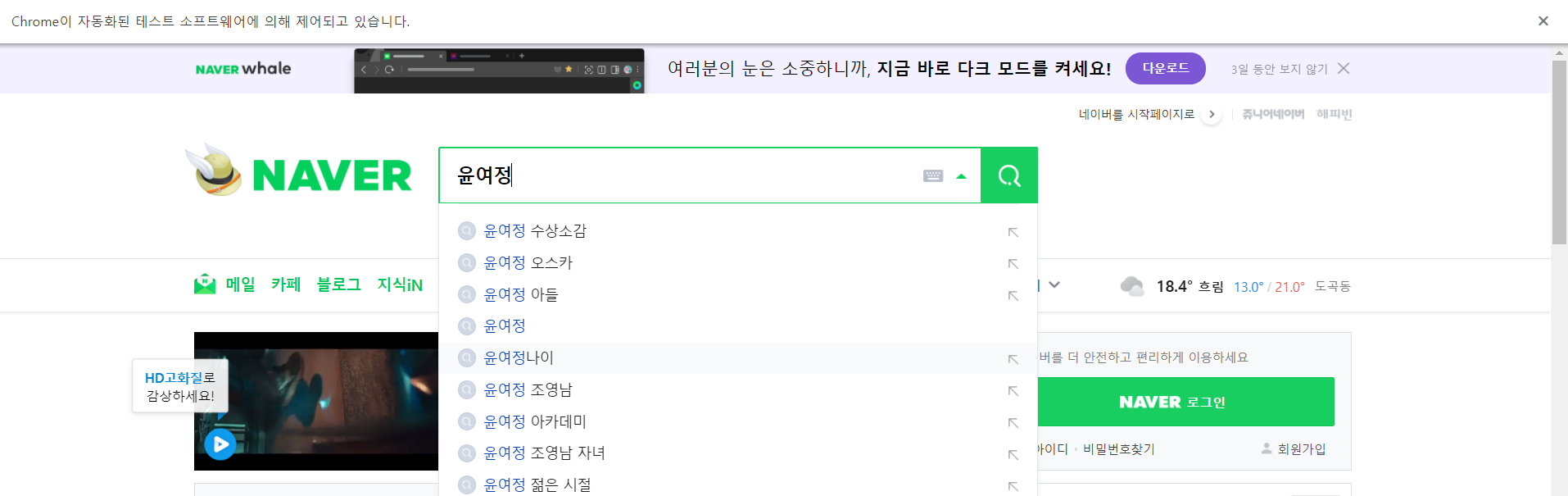
실행시키면 이렇게 '윤여정'이라고 검색어에 입력되어있음을 확인할 수 있다.
3-3-3) 검색어 버튼 누르기
입력을 마쳤으니 검색 버튼을 눌러서 내용을 검색해보아야한다.
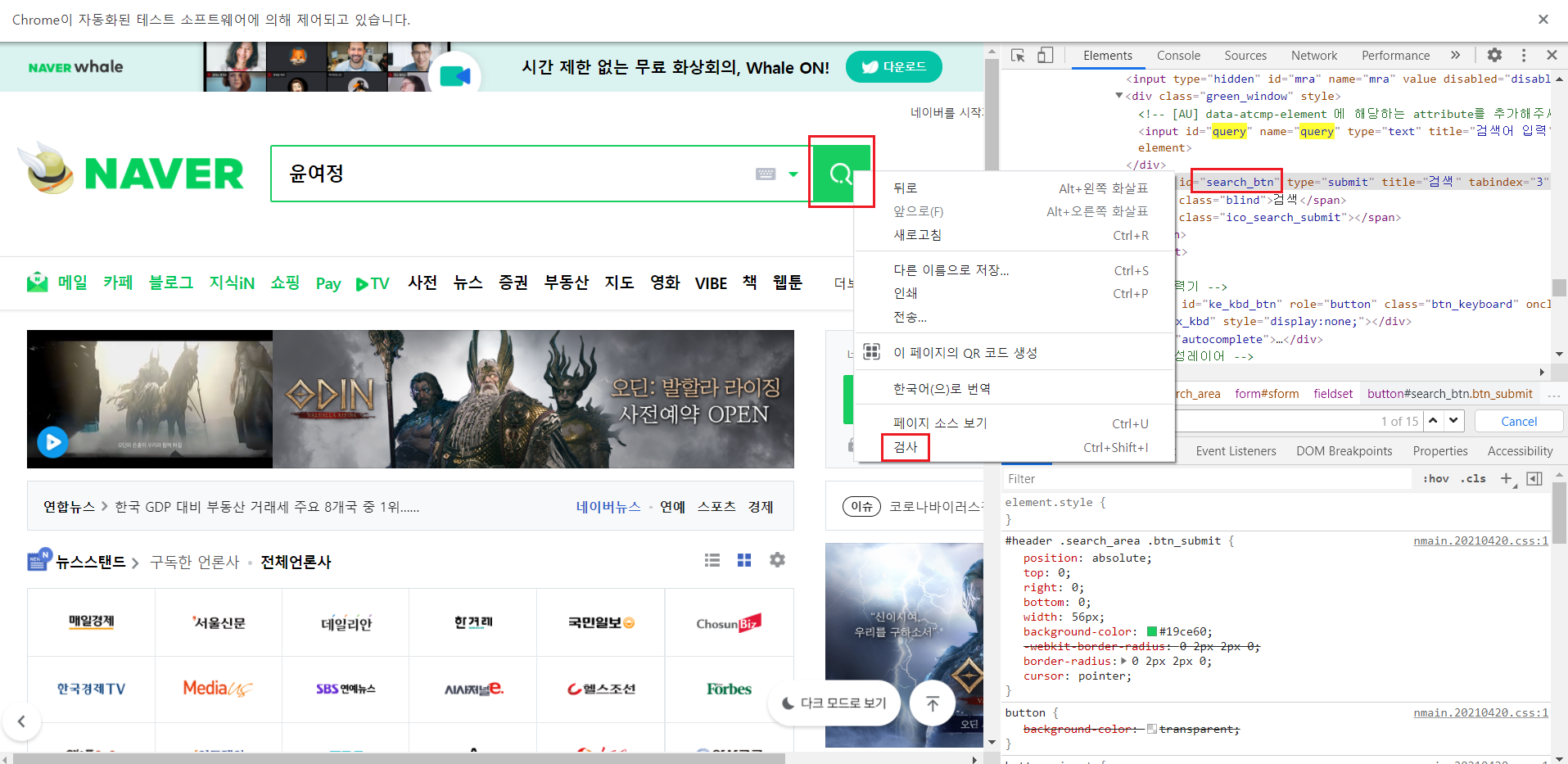
검색 버튼을 검사하여서 검색 버튼을 찾기 위해서는 search_btn을 찾아야한다는 걸 알아냈다. 한 개 인지도 확인해주어야한다.

검색 버튼의 search_btn을 찾아서 .click() 입력해서 검색 버튼이 클릭되도록 한다.
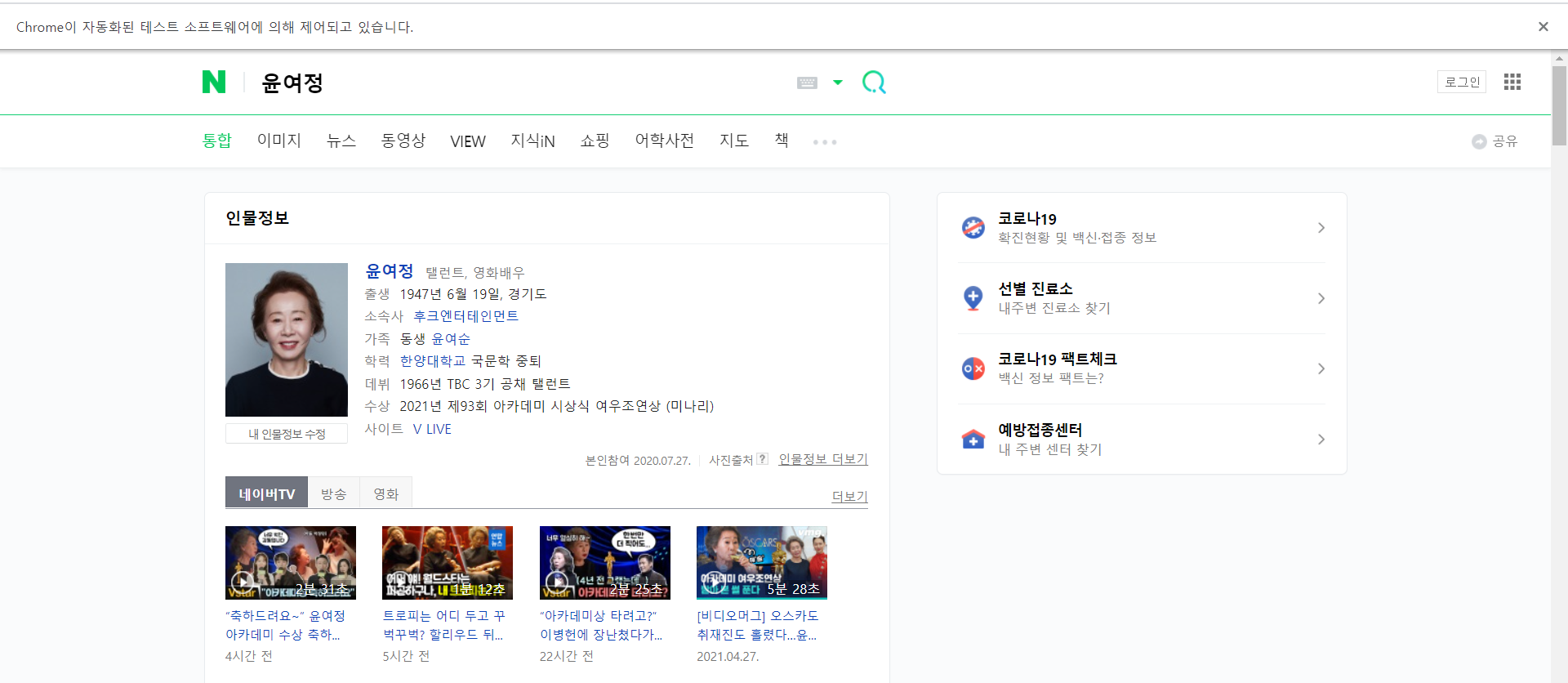
실행시키면 검색 버튼이 눌려서 검색한 결과가 나온다.
3-4) 인터파크 여행정보 크롤링
3-4-1) 인터파크 들어가기

driver.get에 인터파크 주소를 넣어서 인터파크에 접속한다.
3-4-2) 인터파크에서 검색 내용 입력하기
네이버때와 같이 검색창에 글을 쓰기 위해서는 검색창을 검사하여서 find할 것을 알아내야한다.

검색창을 검사하여서 현재 검색창의 위치와 검색창에서 find로 사용할 수 있는 'SearchGNBText' 도 알아봤다. 오른쪽을 확인하면 Ctrl + f 를 통해서 검색해서 1개만 검색되는 것을 확인했다.

find에 찾아온 'SearchGNBText'를 입력해주고 send.keys()를 통해서 '스위스'를 검색해준다.
3-4-3) 검색어 버튼 누르기
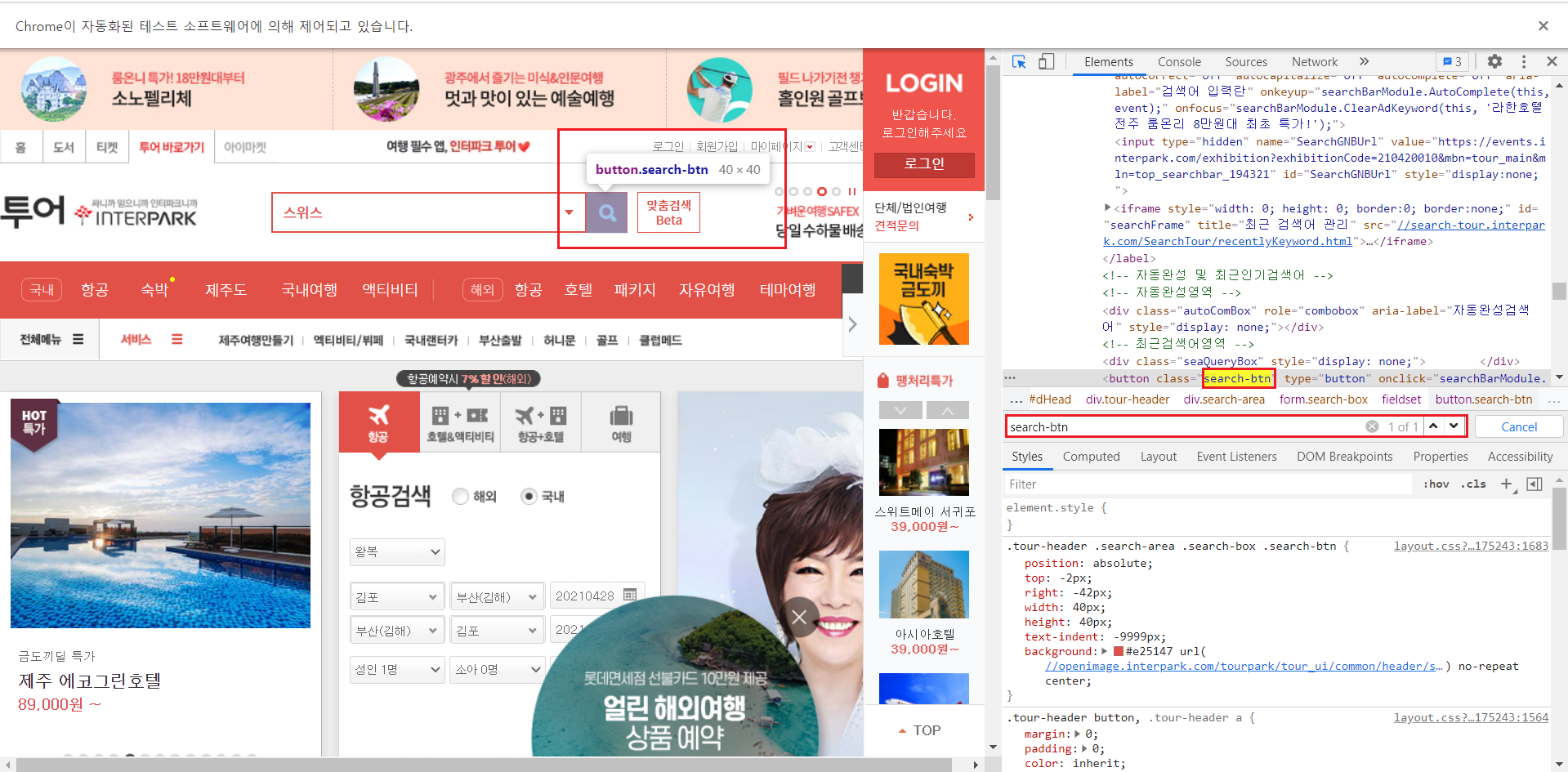
검색어 버튼을 검사하면 search-btn으로 이루어져있고 하나만 있다는 것을 확인할 수 있다.

검색어 버튼을 클릭하기 위해서 find를 써주는데 찾는 객체가 1개 이상이면 find_elements를 객체가 1개면 find_element를 사용한다. 현재는 1개이니 find_element를 사용한다.
검색 버튼을 눌러서 다음 페이지에 넘어가면서 driver.implicitly_wait(10) 를 사용해주는데 이는 페이지가 넘어가기전에 10초를 기다렸다가 실행한다는 뜻이다. 하지만 10초 이전에 페이지가 나온다면 무시되고 페이지가 나온다.
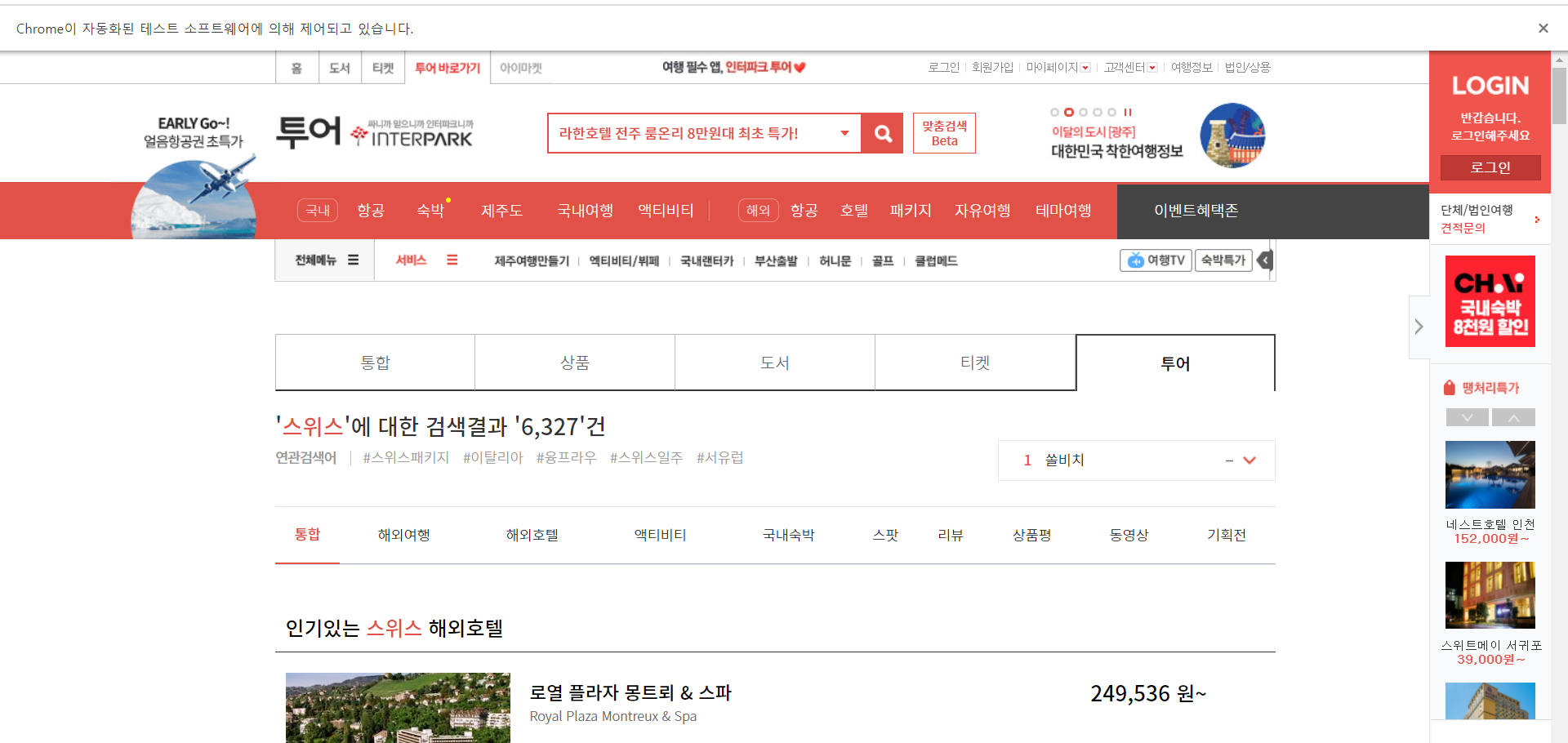
실행되면 검색 버튼이 눌려서 검색이 완료된 페이지가 나타난다.
3-4-4) 해외여행 누르기
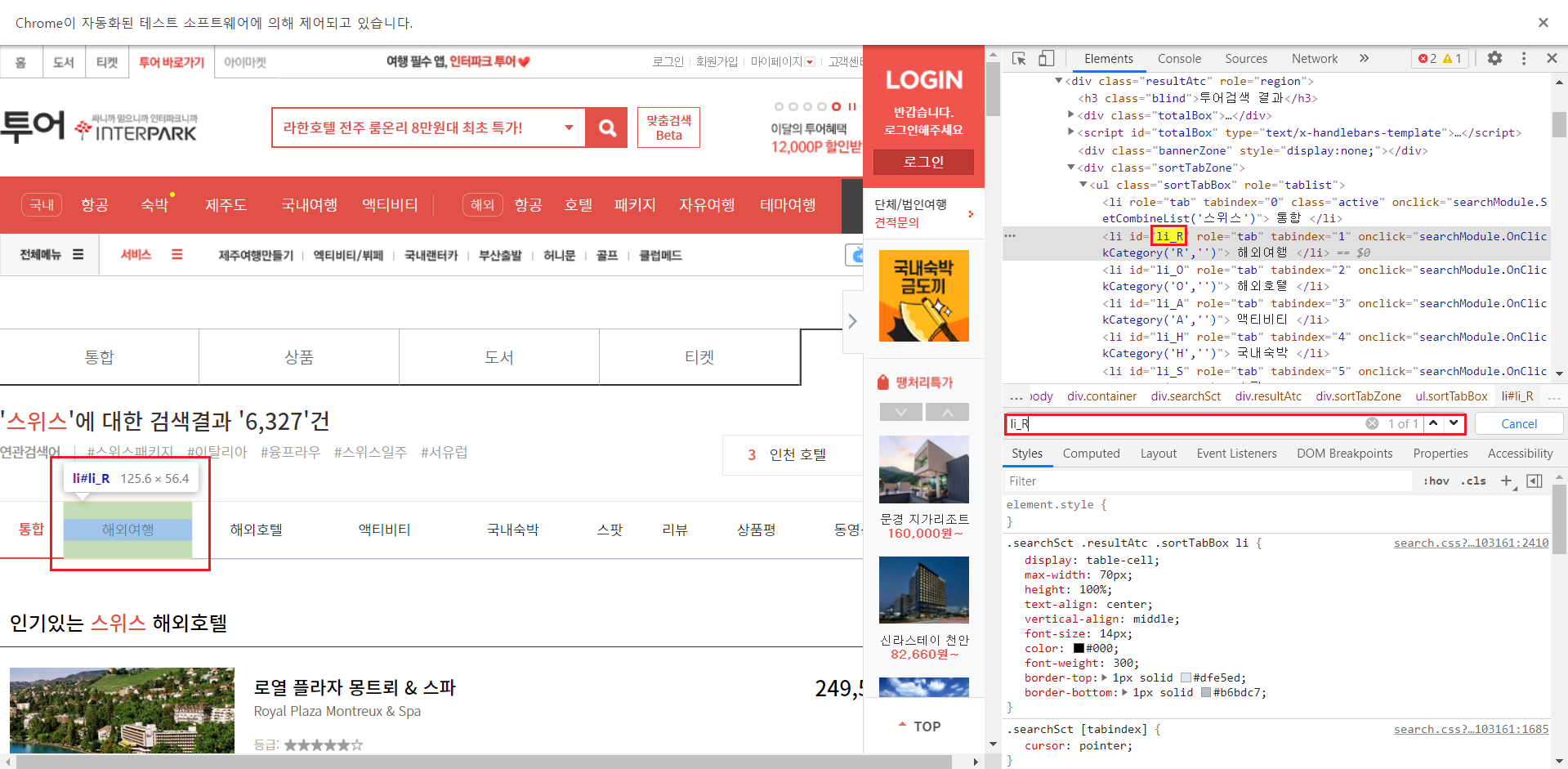
이번에는 스위스로 검색된 창에서 해외여행을 눌러보려고한다. 해외버튼은 검사를 통해서 li_R로 확인할 수 있다.

현재는 1개이니 find_element를 사용하고 해외여행을 클릭하면 페이지가 넘어가니 driver.implicitly_wait(10)도 사용해준다.
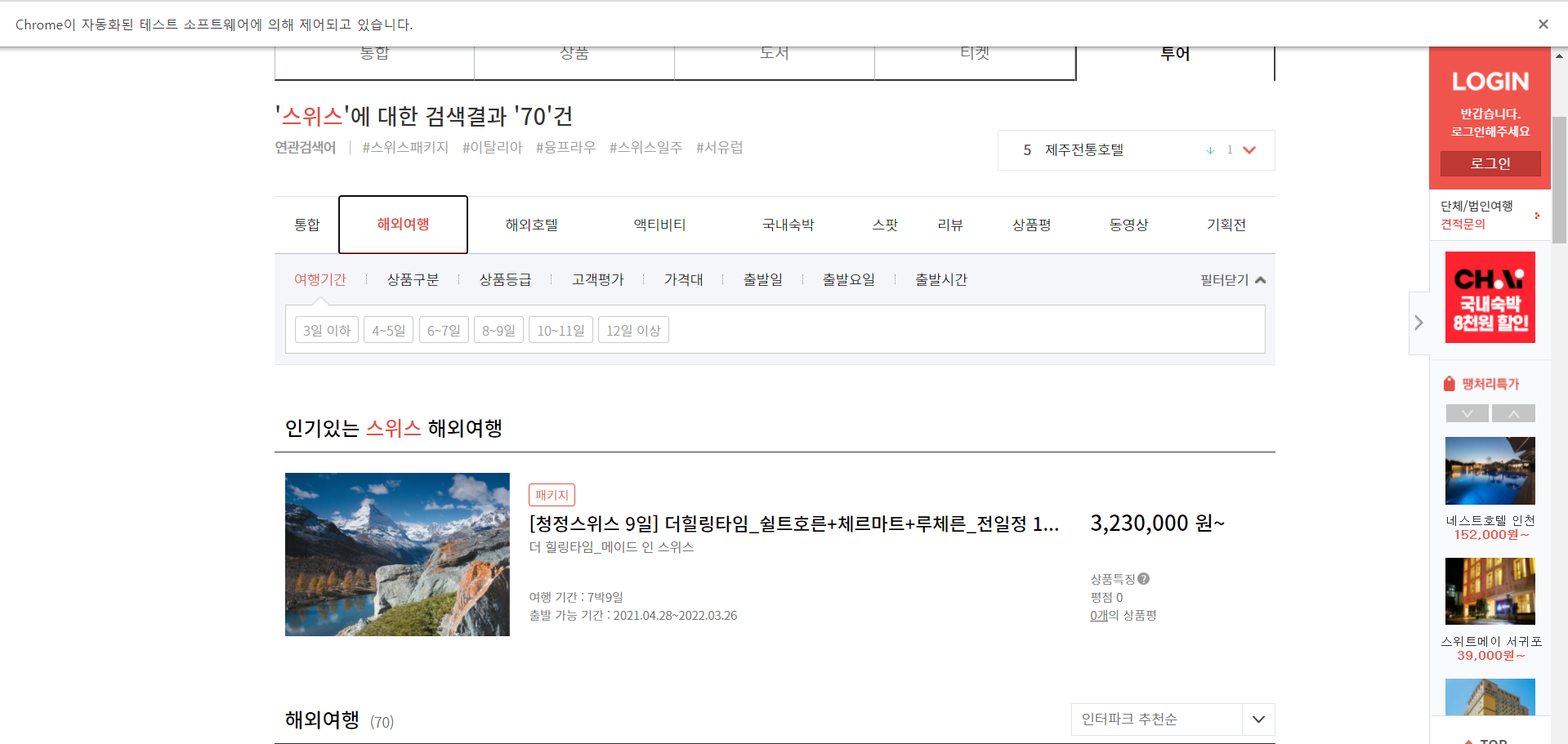
3-4-5) 상품명과 가격 출력하기
먼저 각 페이지마다의 상품명과 가격을 출력하기 위해서 페이지를 넘겨야한다.
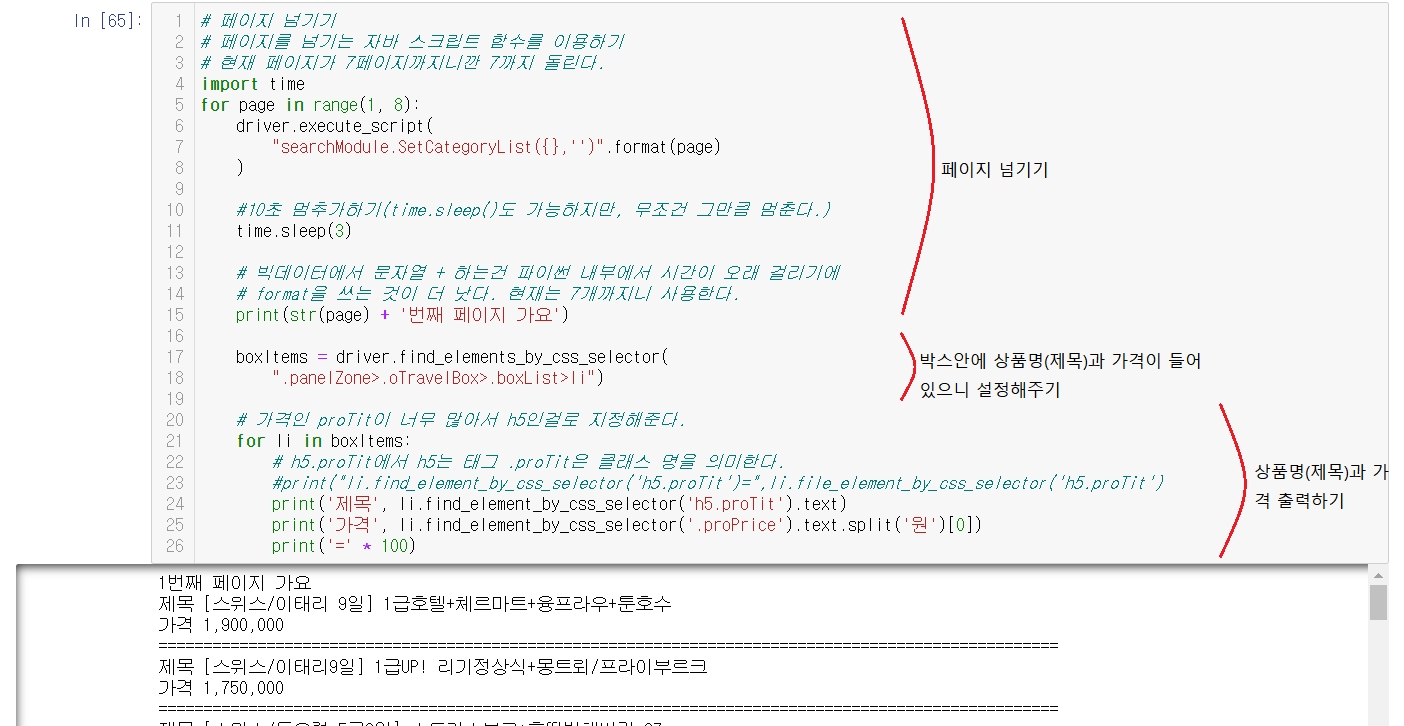
3-4-5-1) 페이지 넘기기
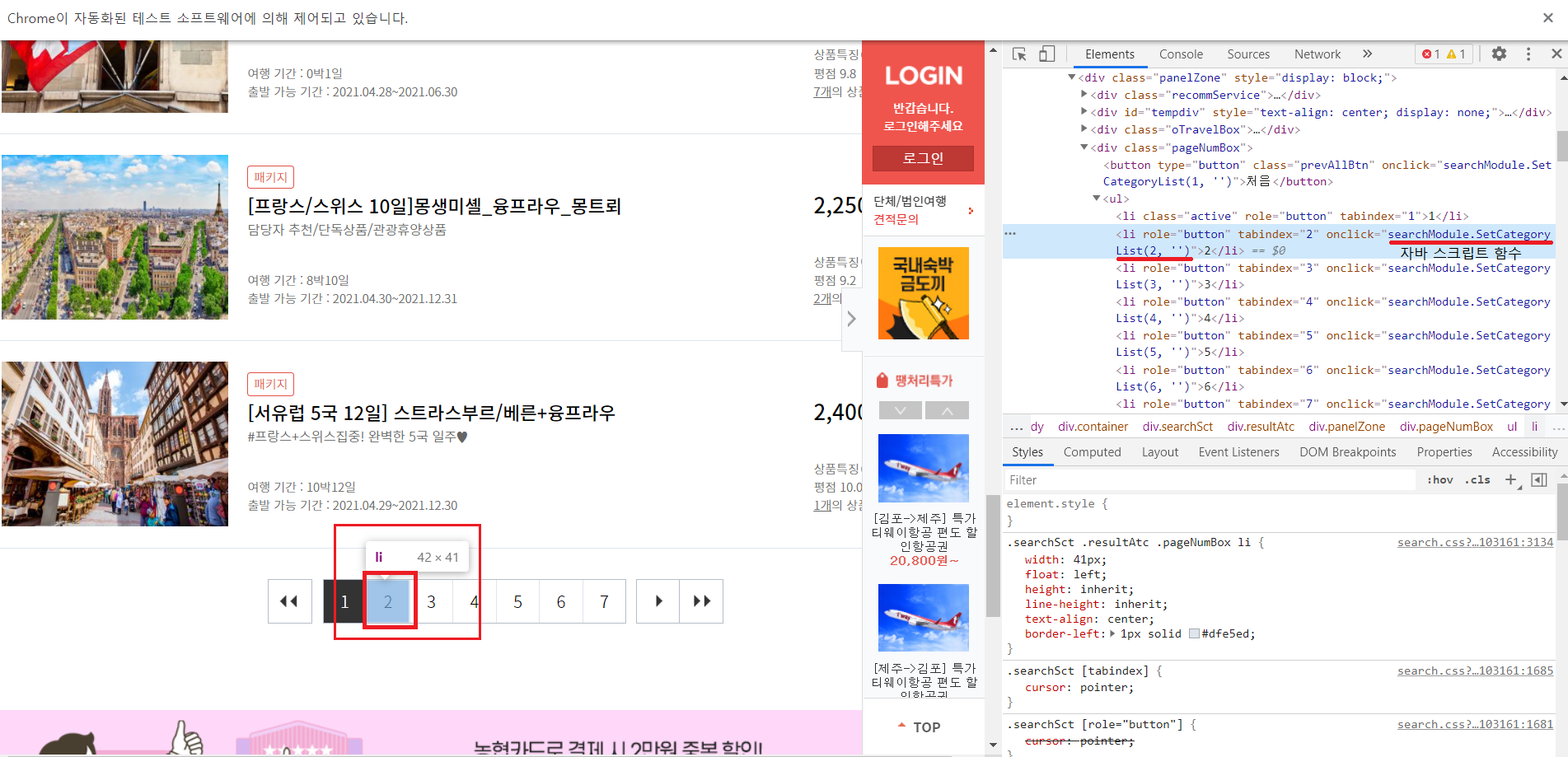
페이지는 driver.execute_script("searchModule.SetCategoryList({},'')".format(page))이 for문을 통해서 페이지가 하나씩 넘어간다. 페이지가 넘어가기때문에 import time을 입력해서 time.sleep()을 진행해주는 위의 썼던 것과 다른 것은 time.sleep은 무조건 그만큼 멈춰진다는 것이다.
3-4-5-2) 상품명(제목)과 가격 찾기
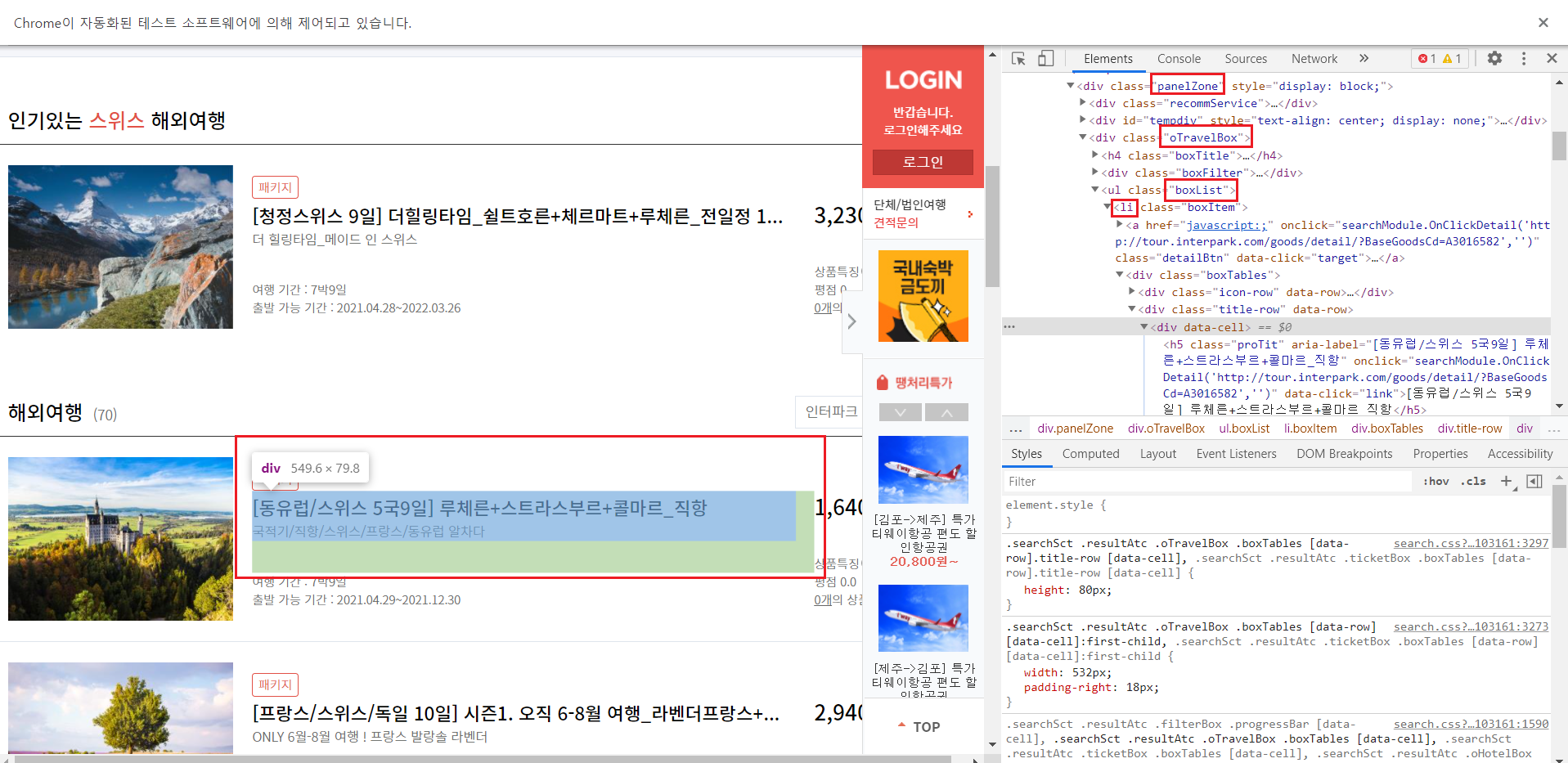
제목과 가격은 .panelZone>.oTravelBox>.boxList>li 안에 있음을 확인할 수 있다.
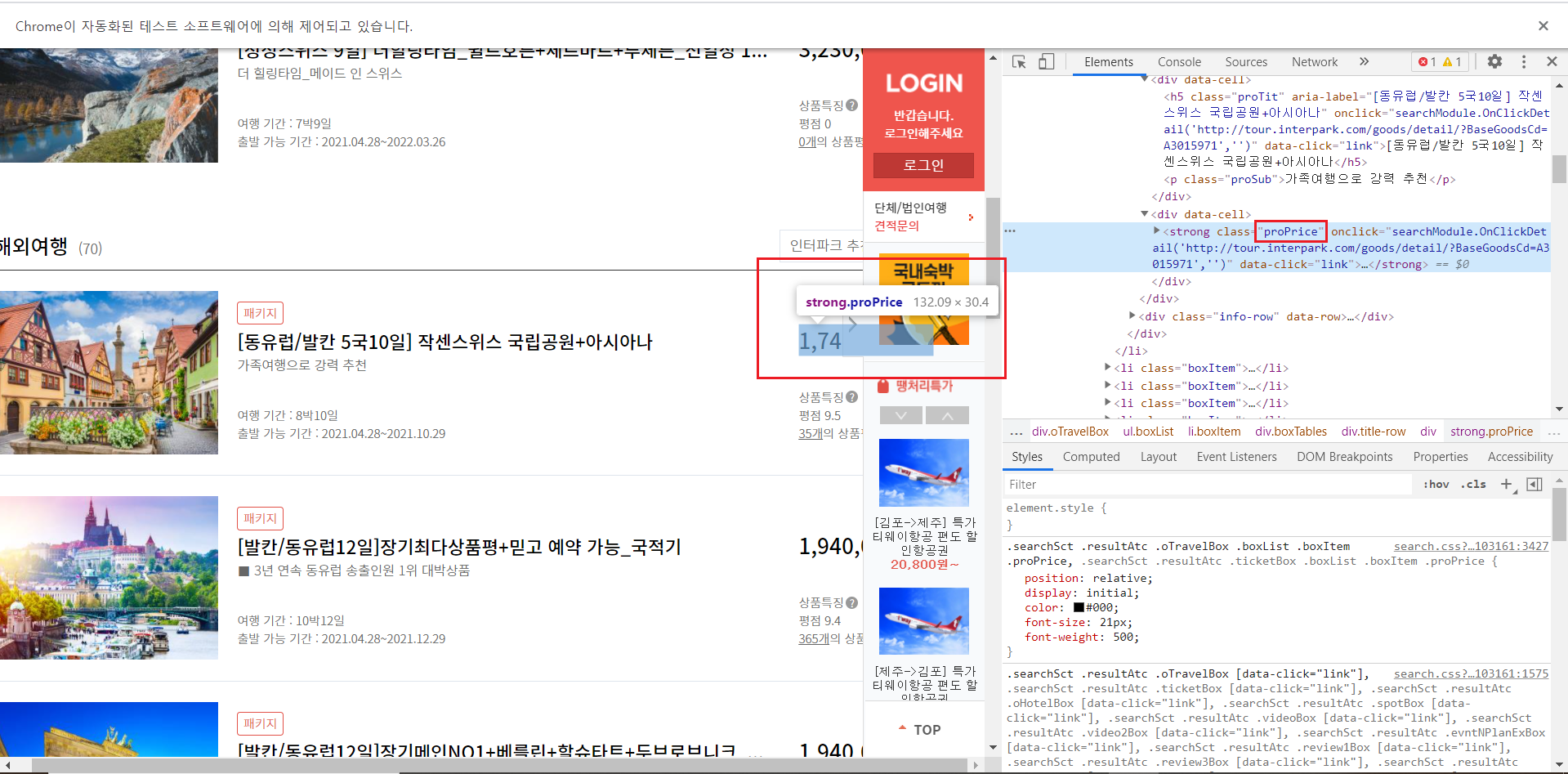
for문을 통해서 상품명(제목)의 'h5.proTit'과 가격의 '.proPrice'을 출력시켜서 상품명(제목)과 가격을 출력한 것을 확인할 수 있다.
'PBL 빅데이터 > 빅데이터 수집' 카테고리의 다른 글
| [수업] 빅데이터 수집4 (0) | 2021.04.30 |
|---|---|
| [수업] 빅데이터 수집3 (0) | 2021.04.29 |
| [수업] 빅데이터 수집1 (0) | 2021.04.27 |


