4) 유튜브 크롤링
4-1) 유튜브 구성 확인하기
4-1-1) Selenium 실행

Selenium을 실행해주고 실행하기쉽도록 변수에 넣어서 실행해준다.

이런식으로 새로운 크롬창이 만들어진다.
4-1-2) 유튜브 채널에 들어가기

get()을 이용해서 url에 들어갈 수 있다. 유튜브는 어제의 인터파크와는 다르게 페이지가 아닌 스크롤로 이루어져있다. 스크롤이 들어있느 body를 확인해본다. body는 태그이므로 find_element_by_tag_name()을 사용한다.
4-1-3) 스크롤 내려기

END Key를 사용해서 스크롤을 내려줄건데 사용하기위해서 import를 진행해준다. END Key를 사용하면 현재 페이지의 스크롤이 내려가는건데 동영상에 더 많을수록 화면이 길어지면서 스크롤을 더 해주어야한다.
4-1-4) 화면의 길이 확인하기

화면의 길이를 알아보는 이유는 스크롤을 다 내렸을 때의 더이상 길어지지않는 화면의 길이를 이용하여 얼마나 스크롤을 내려야하는지 알아보려하기 위함이다.
document.documentElement.scrollHeight는 화면의 길이를 알려주는 자바 스크립스 언어이며, 이것을 return해서 값을 받아볼 수 있다.
4-1-5) 스크롤을 끝까지 내리기

우리가 여태까지 진행한 것들은
1) 스크롤 1번 내리기
2) 화면의 길이 확인하기
에 대해서 배웠다. 이를 이용해서 스크롤을 끝까지 내릴 수 있다.
반복문을 통해서 1번만 내리는 스크롤을 반복해주는데 어디까지 반복하는지에 대해서 화면의 길이로 지정해준다. 화면의 길이가 더이상 늘어나지않으면 끝인것을 이용해주는데 스크롤하기 전의 길이와 스크롤을 하고난 후의 길이를 비교해서 같으면 반복문을 멈추게 지정해주면된다.
실행시키면 반복문을 통해서 스크롤이 끝까지 내려가는것을 확인할 수 있다.
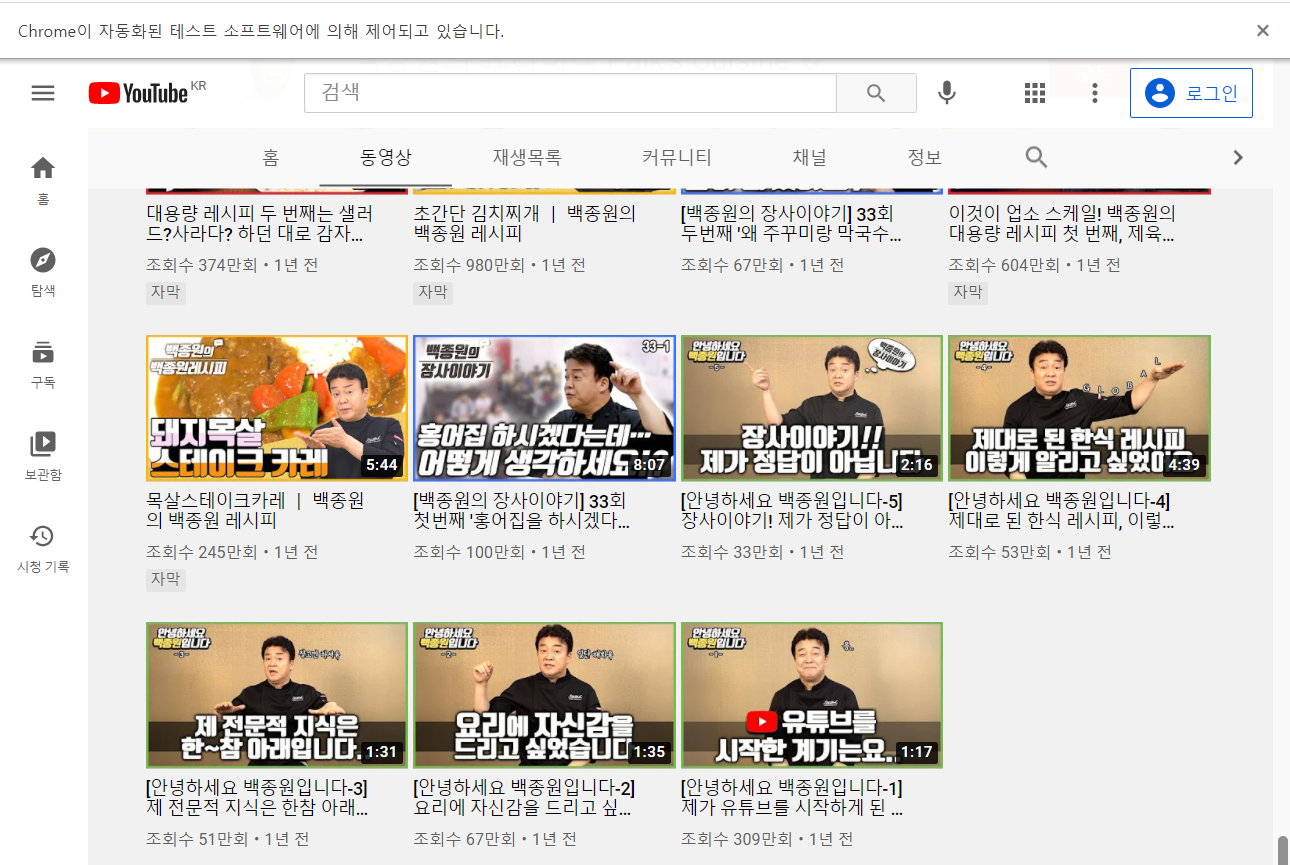
4-2) 유튜브 소스안에서 제목, 조회수 찾기
4-2-1) 유튜브 제목 찾기
4-2-1-1) 유튜브 소스 가져오기

page_source를 이용해서 페이지를 이루고있는 소스를 가져온다. BeautifulSoup을 이용해서 page변수에 저장해놓은 소스를 리턴해서 soup변수에 리턴해준다.
4-2-1-2) 제목과 조회수가 들어있는 dismissible을 출력하기

현재 유튜브에 제목과 조회수를 통틀어서 가지고 있는게 dismissible을 찾았는데 현재 300개로 이루어져있다. 이럴 때는 1개 이상이므로 find_all을 이용해야한다.

소스를 저장해놓은 all_video에서 조회해서 find_all을 통해서 dismissible를 찾아본다.
4-2-1-3) 제목 확인하기

2가지의 방법으로 찾을 수 있는데 첫번째로는 항상하던 검사를 통해서 찾을 수 있다. 검사를 통해서 현재 제목은 video-title이라는 것을 확인할 수 있다.

두번재로는 굵은 선에 표시되어있듯이 소스안에서도 찾을 수 있다. 소스안에서 제목을 찾고 그 앞에 있는 id가 video-title이라는 것을 확인할 수 있다. 편한 방법으로 사용하면된다.
4-2-1-4) 제목 찾기
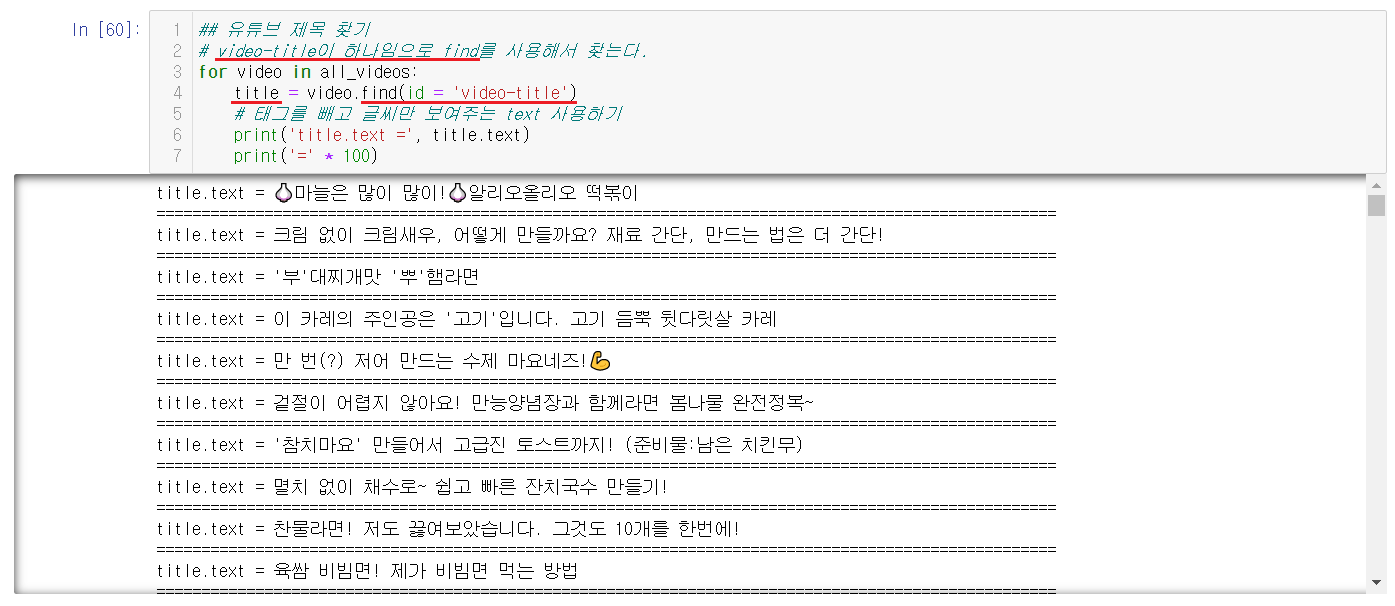
제목이 video-title임을 찾았으니, 소스에서 제목을 찾아보면된다. video-title은 하나이기에 find를 이용한다. 그냥 출력하면 태그들이 다 보여서 복잡해지니 미리 text를 사용해서 문자만 출력하면 위의 결과를 얻을 수 있다.
4-2-1-5) 제목을 리스트안에 넣기

우리의 목표는 제목과 조회수를 둘 다보는것이기에 일단 제목을 리스트안에 넣어서 보관해준다. 제목을 넣은 빈리스트를 생성하고 그안에 위의 for문을 이용해서 append코드를 붙여서 넣어주면 제목을 보관할 리스트안에 제목이 들어감을 알 수 있다.

len()을 통해서 제목의 갯수를 알 수 있다. 제목의 갯수는 동영상의 갯수를 의미하기도 한다.
4-2-3) 시간 찾기
4-2-2-1) 시간 확인하기

시간을 확인해보면 style-scope ytd-thumbnail-overlay-time-status-renderer로 이루어져있다.
4-2-2-2) 시간 찾기

find를 이용해서 시간을 찾고 그걸 빈 리스트에 넣어서 채워줬다.
4-2-2-3) 시간을 변경

리스트안에 있는 시간들을 꺼내서 fot문으로 돌려서 불러와서 변경한다. 시, 분, 초로 나누어서 계산해주는데 시가 있는 곳과 없는 곳을 나눠서 계산해준다. 시간은 *3600, 분은 *60, 초는 더하기를 해줘서 계산하고 다시 새로운 리스트안에 넣어주었다.
4-2-3) 조회수 찾기
4-2-3-1) 조회수 확인하기

조회수를 확인해보니 style-scope ytd-grid-video-renderer임을 찾을 수 있다.
4-2-3-2) 조회수 찾기

제목을 찾을 때와 같이
1) 조회수를 넣을 빈 리스트를 생성
2) 소스를 넣은 all_video안에서 find를 이용해서 조회수(style-scope ytd-grid-video-renderer)를 찾기
3) 태그를 빼고 문자만 보기위해 text 사용
4) 빈 리스트에 조회수를 넣어주기

조회수의 갯수 역시 제목의 갯수와 일치하는 299개임을 확인할 수 있다.
3) 데이터 프레임 시각화

데이터 프레임으로 생성해서 자료를 시각화하려고한다.
1) 딕셔너리를 생성한다.
{'칸 이름' : 칸 데이터, '칸 이름' : 칸 데이터, '칸 이름' : 칸 데이터}
데이터는 리스트만 가능하다. 그렇기에 여태까지 우리는 자료들을 리스트에 넣었다.
2) pandas를 통해서 데이터 프레임을 생성
3) 조회하면 너무 많이 나오니깐 head()를 사용해서 앞의 5줄만 불러와서 확인한다.
현재 시각화되어서 확인이 가능한 것을 확인할 수 있다.
5) 정보 추출
5-1) Konlpy 설치하기
https://liveyourit.tistory.com/56
KoNLPy (파이썬 한글 형태소 분석기 ) 윈도우 설치 방법
파이썬 한글 형태소 분석기인 KoNLPy 설치는 아래 기입된 순서대로, 본인 환경(파이썬 버전, 윈도우 비트)에만 맞게 진행해주면 에러가 발생하지 않는다. 참고로 나의 환경은 '파이썬3.8, 윈도우10 x
liveyourit.tistory.com
블로그를 참고하여서 맞는 파이썬 버전을 선택해서 깔아야한다.
5-2) TF-IDF
5-2-1) TF(Term Frequency)
- TF는 특정단어가 특정 문장내에 등장하는 빈도수를 애기한다.
- TF값이 높을수록 문서에서 중요해진다.
5-2-2) IDF(Inverse Document Frequency)
- TF의 역수로 여기저기나오는 단어의 중요도는 낮추고 한문장에만 나온 빈도수가 낮은 단어들의 중요도를 높인다.
5-2-3) TF-IDF
- TF * IDF
- 특정 단어의 중요도를 수치화한 값이다.
- 특정 단어의 빈도(TF)가 높아질수록 값이 커진다.
- 단어가 희박하게(IDF) 등장할수록 값이 커진다.
- 둘의 값을 곱해야하므로, 둘의 값이 커질수록 큰 수가 나온다.
5-2-4) 실행해보기
5-2-4-1) 리스트 만들기

TF-IDF를 체크할 문장들을 리스트안에 넣어준다.
5-2-4-2) 벡터화

TfidfVectorizer를 import해주는데 혹시 안된다면 pip install sklearn으로 설치 후 진행하면 된다. 벡터화하기를 위해서 불러오고 지정된 변수에 넣어서 진행해준다. 만들어논 문장 word_list를 넣어주면 벡터화한 값을 알 수 있는데 vector.A를 통해서 내용을 출력해서 확인할 수 있다.
5-2-4-3) 인덱스 확인

min_df는 지정한 값보다 작은 경우에는 무시하고 진행된다. 현재 인덱스를 확인해보면 계산된 단어들을 확인할 수 있다. 이 때, 주의할 점은 단어가 1자리인 경우는 인식되지않으니 단어를 2자리로 적어주어야 재대로된 값을 얻을 수 있다.
5-2-4-4) 명사만 계산하기

명사만을 골라낼 함수를 설정해준다. 현재 확인해보면 split으로 나눠서 단어들로 문장들이 나눠지는 것을 확인할 수 있다.

다시 한번 결과값을 확인해보면 현재 사용된 단어들이 나오고 그 단어들의 벡터화를 확인할 수 있다. 아직은 명사만을 골라낸 것은 아니고 명사, 형용사등으로 나누기위해서 Konlpy을 내일 사용할 예정이다.
'PBL 빅데이터 > 빅데이터 수집' 카테고리의 다른 글
| [수업] 빅데이터 수집4 (0) | 2021.04.30 |
|---|---|
| [수업] 빅데이터 수집2 (1) | 2021.04.28 |
| [수업] 빅데이터 수집1 (0) | 2021.04.27 |


