안녕하세요. 나야 Kubeflow 2탄으로 돌아왔습니다. 1탄에서는 Kubeflow의 컴포넌트와 파이프라인을 생성하는 것까지만 진행되었는데요. 나머지로 남아있던 Kubeflow Pipeline 실행방법과 아직 남은 컴포넌트인 Model Training, Model Serving, AutoML에 대해서 다뤄볼려고 합니다🤗
1. Pipeline - Kubeflow Pipeline
1-1. Pipeline 실행하기 - UI
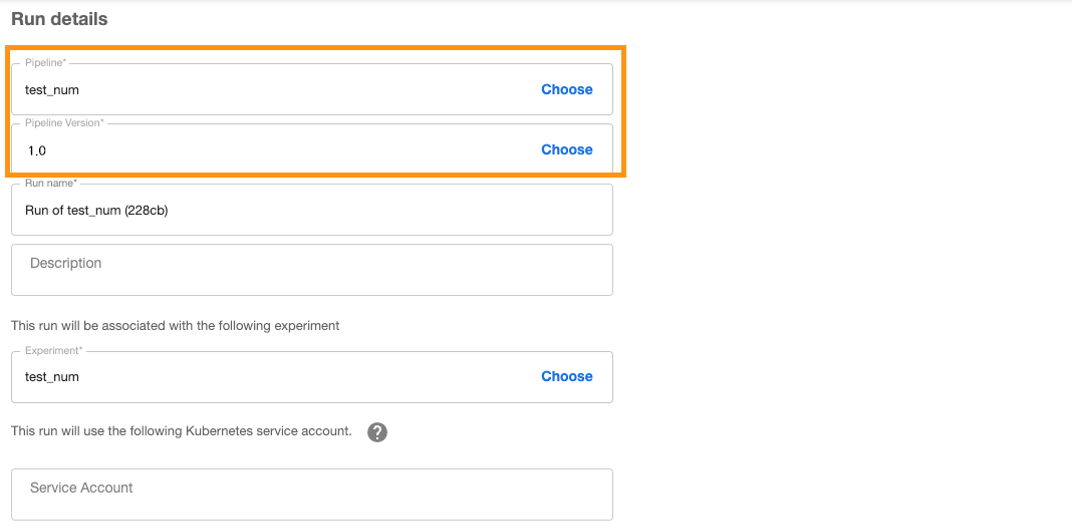
Kubeflow Pipeline 탭에 들어가서 확인하게 되면 이렇게 어떠한 파이프라인을 실행할 것인지, 1탄에서 나온 것과 같이 파이프라인의 버전 중에는 어떠한 버전을 선택할 것인지를 지정해서 진행할 수 있게 됩니다.

파이프라인 함수를 작성할 때, 1탄에서는 예시를 들어서 작성했었는데요. 만약에 기억이 안나신다면 1탄을 다시 참고하면 좋을 것 같습니다. 간단하게 정리하면 num1, num2를 받아와서 진행하는 함수였습니다. 그렇기에 파이프라인의 실행을 위해서는 num1, num2의 값을 지정해주어야 합니다. 이런식으로 UI를 이용해서 파이프라인의 실행까지 가능하게 됩니다.
1-2. Pipeline 실행하기 - Client
from kfp.client import Client
client = Client(host='<HOST_URL>')
client.create_run_from_pipeline_func(pipeline_func, arguments={'num1': 7, 'num2': 2})
다른 방법으로는 클라이언트를 사용하는 방법에 대해서도 알아보겠습니다. 클라이언트로 실행하는 방법은 Kubeflow 백엔드에 해당하는 호스트 URL을 연결해서 클라이언트를 생성하게 됩니다. 생성된 클라이언트에서 파이프라인을 생성할 수도 있고 곧장 파이프라인을 실행시키는 것도 가능합니다. 클라이언트는 파이프라인 함수뿐만 아니라 YAML 파일을 가지고도 생성할 수 있습니다. 코드에서는 클라이언트를 생성하고 이 클라이언트에 create_run_from_pipeline_func를 사용하여 파이프라인이 곧장 실행되도록 하였습니다. 파이프라인을 실행하기 위해서는 UI때와 동일하게 num1, num2를 넣어서 진행해야하기에 arguments 부분에 num1, num2를 지정해서 실행할 수 있게 됩니다.
1-3. Pipeline 확인하기
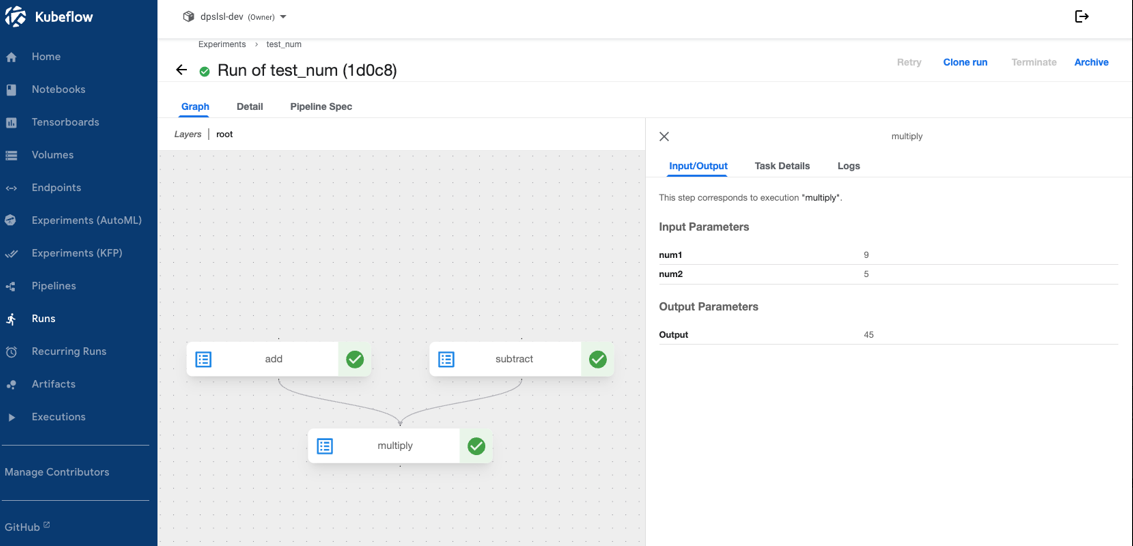
파이프라인을 실행하고 완료된 파이프라인을 클릭하게 되면 이렇게 확인할 수 있습니다. 확인해보면 저희가 예시로 넣어놓은 add, subtract, multiply 총 3개의 컴포넌트가 잘 생성되었다는 것을 확인할 수 있습니다. 각 컴포넌트의 오른쪽에는 실행이 완료되어 초록색 체크 표시가 나타나있는 것을 알 수 있습니다. 해당 컴포넌트를 클릭하면 input, output, log까지 볼 수 있습니다. 사진에서는 최종 컴포넌트인 multiply를 클릭해서 나온 input, output을 나타내고 있습니다. multiply에서 num1은 add의 output, num2는 subtract의 아웃풋으로 되어있는 것을 그림으로도 체크할 수 있습니다.
| add | subtract | multiply | |
| num1 | 7 | 7 | 9 |
| num2 | 2 | 2 | 5 |
| output | 9 | 5 | 45 |
처음에 파이프라인을 시작할 때, num1에는 7을 num2에는 2를 주면서 진행했기에 add 함수 7 + 2 = 9의 output값이 num1으로 들어가있고 subtract 함수 7 - 2 =5의 output값이 num2에 재대로 들어와 있는 것도 확인할 수 있습니다. 최종적인 multiply 함수에서 둘을 곱해서 output이 정확하게 45로 나온 것까지의 전체적으로 파이프라인이 잘 돌아갔는지를 알 수 있었습니다.
2. Model Training - Kubeflow Training Operator
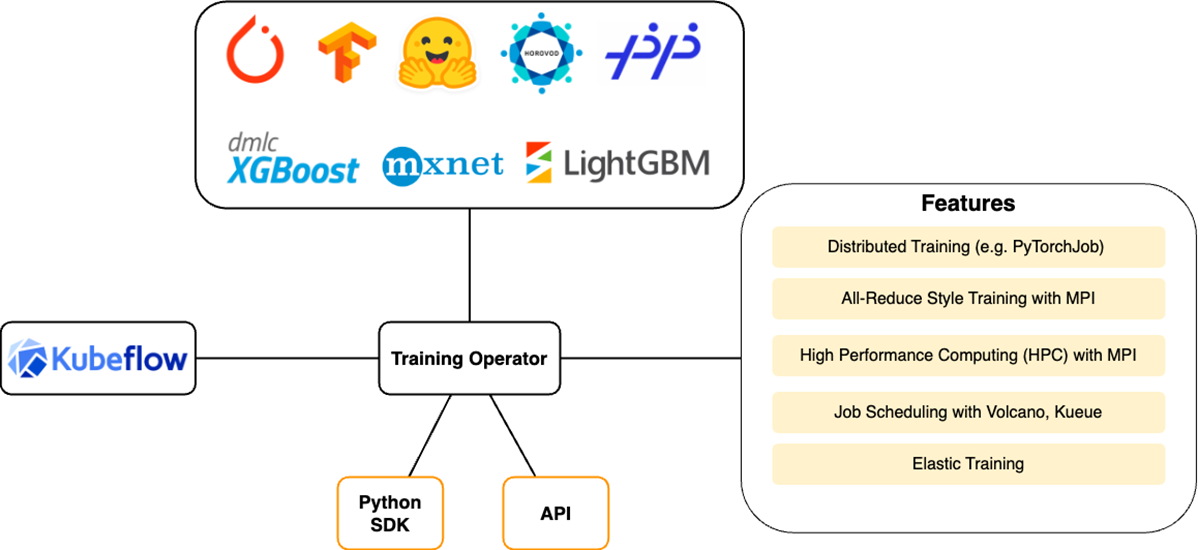
이번에는 training operator에 대해서 살펴볼려고 합니다. PyTorch, TensorFlow, XGBoost 등 다양한 ML 프레임워크를 사용하여 만든 모델의 미세 조정 및 분산 학습을 위한 Kubernetes 기반 프로젝트입니다. 그림과 같이 HuggingFace, DeepSpeed와 같은 다른 ML 라이브러리를 Training Operator와 통합하여 Kubernetes에서 ML 학습이 가능합니다. Training Operator Python SDK, API를 이용해서 구성이 가능합니다. PyTorchJob, TensorFlowJob을 이용해서 학습이 가능하고 Job 스케쥴링도 진행할 수 있습니다.
3. AutoML - Katib

Katib는 AutoML을 위한 Kubernetes 기반 프로젝트입니다. 그림의 오른쪽에서 확인이 가능하듯이 HyperParameter Tuning, Early Stopping, Neural Architecture Serarch 등을 지원합니다. Bayesian optimization, Tree of Parzen Estimators, Random 등의 다양한 AutoML 알고리즘을 지원합니다. HyperParameter Tuning에는 최적화할 parameter, algorithm, early stopping point, 사용할 metrix, 최대 몇번을 시도할지를 나타내는 maxTrialCount , 최대 몇번의 실패를 허용할 것인지 maxFailedTrialCount 등을 통하여 조정이 가능합니다.
3-1. HyperParameter Tuning
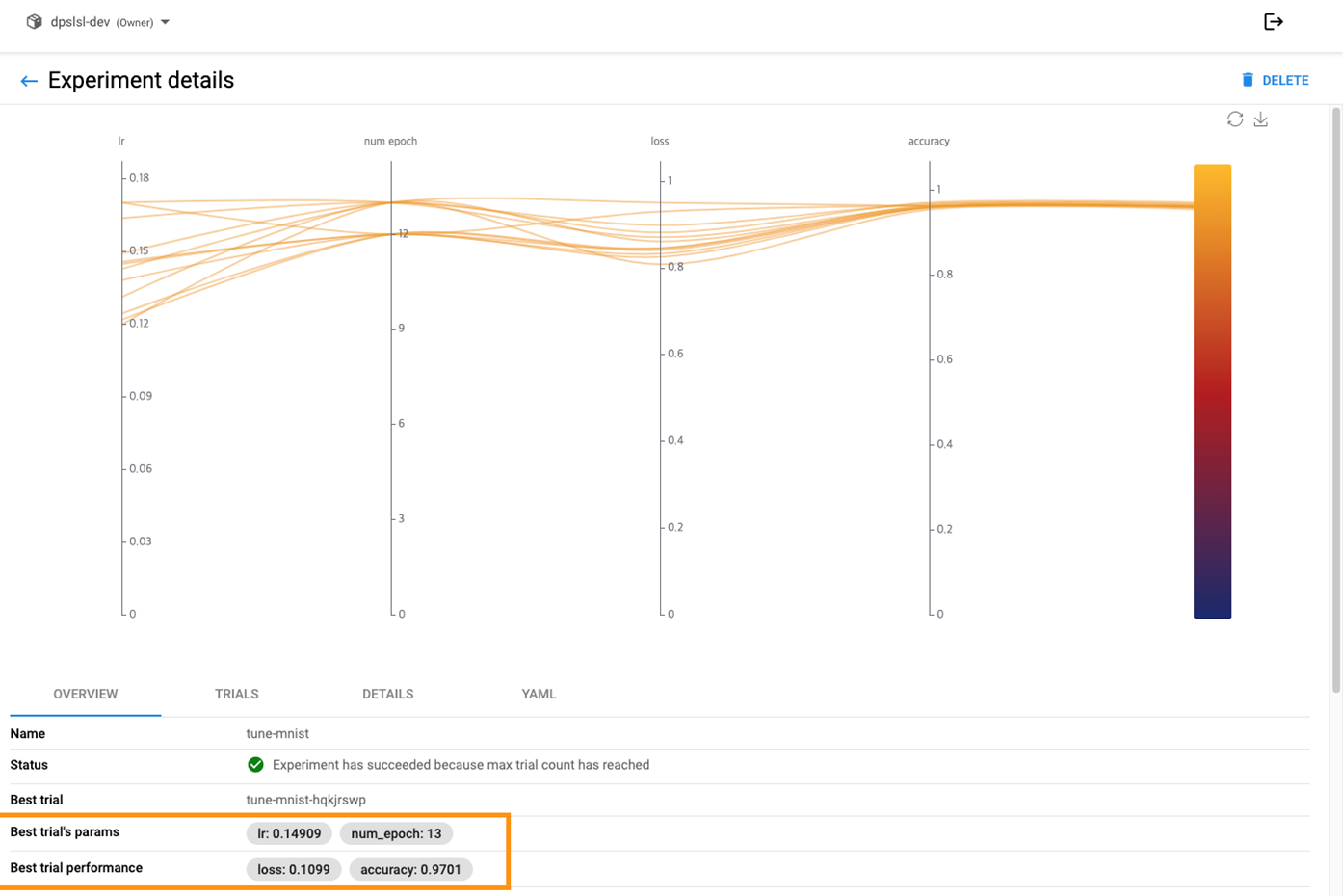
HyperParameter Tuning을 돌린 값을 대시보드로 확인한 결과입니다. 밑에 주황색 박스를 보시면 Best trial's params, Best trial performance가 있습니다. Best trial's params는 지정한 최적화할 파라미터의 최적의 값을 의미하며, Best trial performace는 사용한 metrix의 값을 의미합니다. 이렇게 지정한 metrix의 값을 이용해서 최적화된 파라미터의 값을 뱉어주며, 이를 UI적으로 그래프로도 확인할 수 있습니다. 또한 최적화된 값은 클라이언트을 이용하여 값을 가져와서 다시 학습하는데 연결해서 사용할 수 있습니다.
4. Model Serving - KServe

마지막 컴포넌트는 Model Serving을 위해서 사용하는 KServe입니다. Scikit-Learn, XGBoost, TensorFlow, PyTorch와 같은 ML 프레임워크와 사용자 정의 모델을 사용하여 CPU, GPU에서 모델 추론이 가능한 서버리스 배포를 제공합니다. 자동 확장, 네트워킹이 살아있는지 상태 검사, 사용하지않으면 Zero로 관리하는 Scale To Zero와 Canary Rollouts 등의 기능들을 ML 배포시에 제공합니다. 그림을 확인하면 모델 인퍼런스 옆에 작게 모델 스토리지가 있는 것을 확인할 수 있습니다. 만들어진 모델을 가져와서 사용해야하기에 지원하는 스토리지가 있는데 스토리지는 Google GCS, AWS S3, Azure Blob Storage, 로컬 컨테이너 파일시스템, PVC 형식 등으로 전반적인 것은 모두 지원되고 있다고 보시면 됩니다. 스토리지의 모델 URL만 지정해서 모델을 올릴 수 있어서 매우 쉽게 올릴 수 있다는 장점이 있습니다.
4-1. Model Inference

KServe의 호스팅된 모델로부터 inference를 가지고 오고 싶다면, inference 서비스의 인스턴스를 호출하면됩니다. POST 요청으로 예측값과 예측값에 대한 설명을 받아올 수 있습니다. GET을 통해서는 모델의 목록, 모델의 상태도 확인할 수 있습니다. 현재 보여드리는 것은 V1이고 V2에서는 이외에 추가적으로 확인할 수 있는 내용들이 추가되었지만, 모델 예측값에 대한 설명은 지원되지않는다고하니 참고하셔서 필요에 따라서 버전을 선택해서 사용하시기 바랍니다. 이렇게 전체적인 Kubeflow의 컴포넌트들을 살펴보았습니다.
5. MLOps
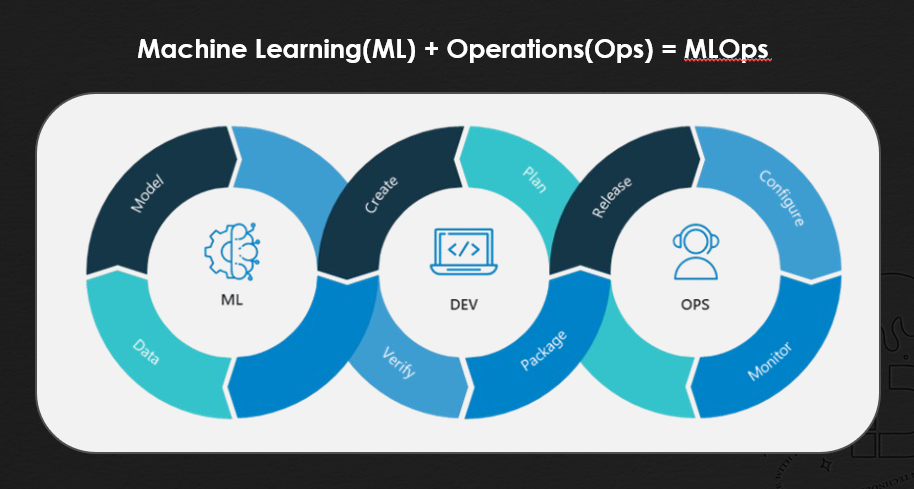
이렇게 전체적인 Kubeflow의 컴포넌트들을 살펴보았습니다. 이제 이러한 Kubeflow가 왜 ML 특화인가에 대해서 좀 더 살펴보고자 합니다. MLOps란 Machine Learing의 ML과 Operations의 OPs가 합쳐져서 MLOps라고 불립니다. 전체적으로 ML은 데이터 수집, 전처리, 모델 구축, 학습, 평가를 진행하게되고 Ops의 부분에서는 모델 배포, 모니터링, 테스트를 진행하게됩니다.

여태까지 얘기했던 Kubeflow의 컴포넌트들과 연결지어서 생각해볼 수 있습니다. 데이터를 수집하고 전처리하고 모델을 만들고 학습하는 과정을 파이프라인을 만들어서 관리할 수 있고 학습 과정에서는 Training Operator를 사용할 수 있었습니다. HyperParameter Tuning을 진행하는 부분에서는 Katib을 사용해서 모델을 평가할 수 있었으며, 마지막 Ops의 모델을 배포하고 모니터링하는 부분도 대시보드로 모니터링할 수 있고 KServe를 이용해서 간단하게 올리고 POST 요청으로 값을 가져오고 KServe에는 Canary Rollouts등의 기능도 있어 배포할 수 있었습니다. 전체적인 MLOps의 기능을 Kubeflow안에서 진행이 가능하다는 것을 확인할 수 있습니다.
6. 마무리

전체적인 부분이 아니더라도 모델을 만들고 KServe을 이용해서 배포만 한다던지 HyperParameter Tuning 진행을 Kubeflow에서만 진행한다던지 부분적으로 각자의 개발 환경에 맞게 사용할 수 있습니다. 처음에 Kubefloe Ecosystem에서 확인했듯이 여러 클라우드 서비스에서도 활용과 확장이 가능합니다. Kubeflow의 제일 큰 목적인 ML 엔지니어와 데이터 사이언티스트가 나누어 개인의 작업만 진행하고 서로의 작업의 관여할 수 없는 것이 아닌 서로의 부분을 확인하고 쉽게 활용할 수 있다는 부분이 여러분에게 잘 전달되었기를 바랍니다. 이번 기회를 통해서 쿠브플로우를 직접 사용해보고자하는 계기가 되셨기를 바랍니다. 이상 쿠브플로우 알아보기였습니다👋
'챱챱' 카테고리의 다른 글
| [서평] 데이터 엔지니어를 위한 97가지 조언 (2) | 2025.01.05 |
|---|---|
| [챱챱] ML엔지니어 -> 데이터 엔지니어로 Change (0) | 2024.11.24 |
| [글또] 글또 10기를 바라보며 다짐하는 것들 (1) | 2024.10.10 |
| [Kubeflow] 나야 Kubeflow(feat. Kubeflow 알아보기) (0) | 2024.10.03 |
| [글또] 삶의 지도 (6) | 2024.09.21 |


