오늘은 Kubeflow에 대해서 설명하기 위해, 요새 유명한 나야 들기름 짤을 이용하여 나야 Kubeflow 짤로 변형해서 사용해보았습니다👨🍳 Kubeflow는 DEVOCEAN에서 진행한 Deep Dive Kubernetes 스터디를 통해서 알게 되었고, 최종적으로 DEVOCEAN 발표에서 주제로 삼았기 때문에 블로그에도 Kubeflow에 대해서 공유해드리고자 합니다!!
1. Kubeflow란 무엇인가?

Kubeflow라는 뜻은 Kubernetes의 Kube + ML Workflow의 flow 를 합쳐 Kubeflow라고 불리게 되었습니다. 합쳐진 말 그대로 Kubernetes를 이용해서 ML Workflow를 구성하는 것입니다. 정확한 뜻을 살펴보면 Kubernetes 환경에서 ML 라이프사이클의 각 단계를 다룰 수 있는 오픈소스를 의미합니다. 개발자, 데이터 사이언티스트, ML엔지니어 등 모두가 모델 구축부터 테스트, 배포까지의 ML 라이프사이클의 모든 부분을 처리할 수 있는 서비스를 제공하고 있습니다.
2. Kubeflow 구성요소
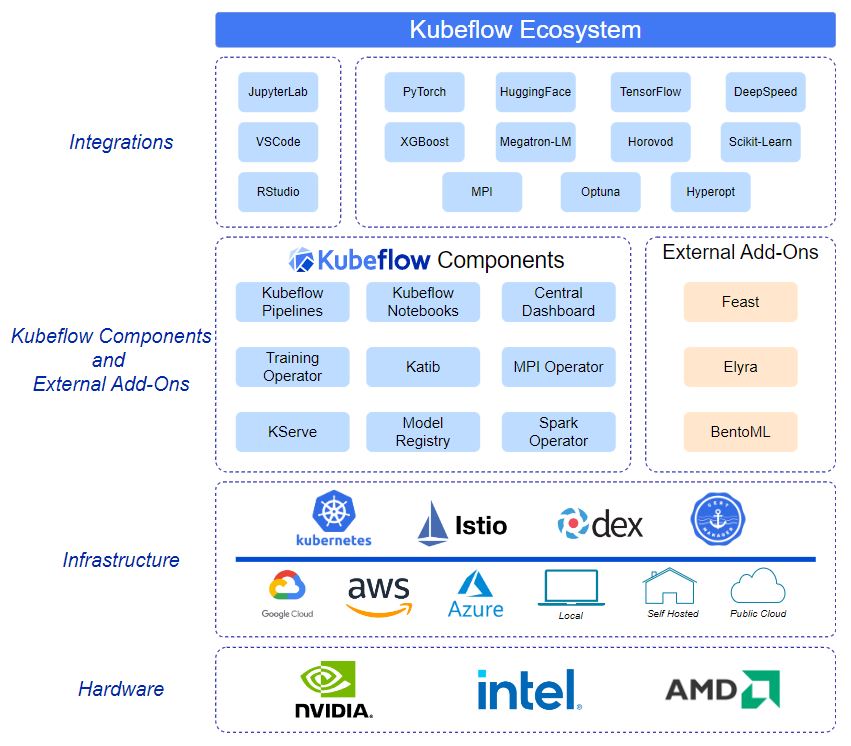
전체적인 Kubeflow 에코시스템을 나타낸 그림입니다. AWS, Google Cloud, Azure, Local 등으로 사용할 수 있고, 그 위에는 Kubeflow 컴포넌트들이 위치하게 됩니다. Kubeflow 컴포넌트들 위에는 JupterLab, VSCode, RStudio 등을 사용 가능하고 Hugging Face, PyTorch, TensorFlow 같은 내용들을 사용할 수 있습니다. 전체적인 시스템에서 Kubeflow 컴포넌트들을 자세히 살펴볼려고 합니다.
3. Kubeflow Components

총 6개의 컴포넌트들에 대해서 알아보겠습니다. 컴포넌트를 나타내는 그림 밑의 굵은 글씨는 서비스의 기능, 작은 글씨는 해당 기능을 제공하는 Kubeflow 서비스의 이름입니다. 뒤에서 하나씩 자세히 다루기전에 먼저 간단하게 하나씩 확인해보도록 하겠습니다.
Pipeline
데이터 전처리, 학습, 테스트같은 전체적인 파이프라인은 쿠브플로우 파이프라인을 통해서 구축할 수 있습니다.
Noteboks
Notebooks는 그림에서 볼 수 있듯이 JupterLab, VSCode, RStudio를 사용할 수 있습니다.
Dashboard
말 그대로 실행되는 내용들을 대시보드를 통해서 UI적으로 확인할 수 있도록 제공합니다.
AutoML
Hyperparameter Tuning을 실행할 수 있고, 이 경우에는 Katib를 이용할 수 있습니다.
Model Training
모델의 학습을 위해서 Kubeflow Training Operator를 이용해서 학습할 내용들을 관리할 수 있습니다.
Model Serving
KServe를 통해서 쉽게 모델을 배포하고 API를 이용하여 쉽게 인퍼런스를 진행할 수 있습니다.
4. Dashboard - Central Dashboard
Central Dashboard는 클러스터에서 실행되는 구성 요소의 실행 및 내용들을 확인할 수 있도록 UI를 제공합니다. 그림에서와 같이 대시보드내에서는 현재 돌아가는 파이프라인, 사용한 노트북 등의 내용들을 시각적으로 확인할 수 있습니다. 또한, 프로필을 이용하여 사용자를 추가하고 삭제할 수 있고 이러한 사용자들에게 읽고 쓰는 권한을 부여하며 관리할 수 있습니다.
5. Notebooks - Kubeflow Notebooks
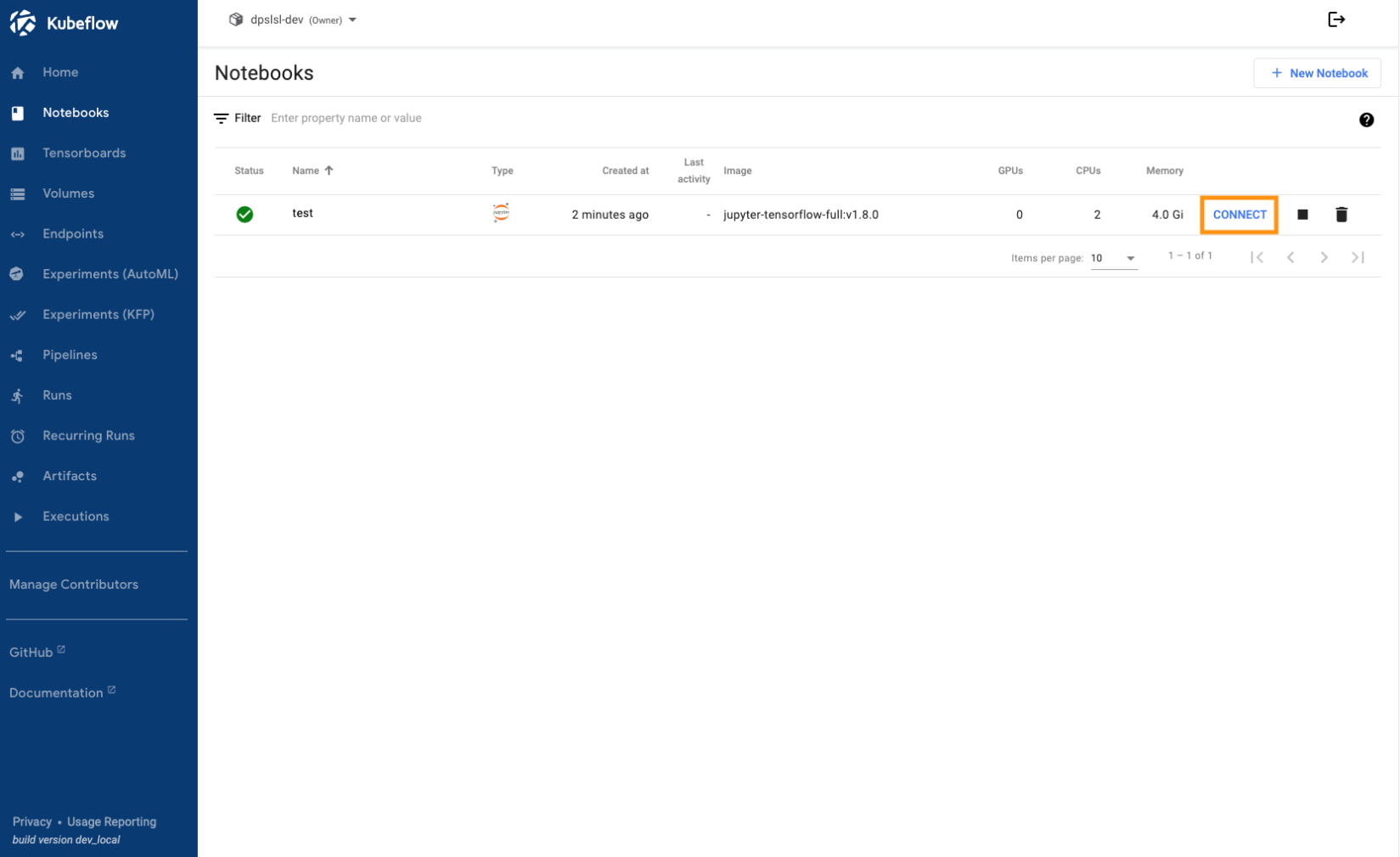
Kubeflow Notebooks는 Kubernetes 클러스터내에서 웹 기반 개발 환경을 실행할 수 있는 방법을 제공합니다.
JupterLab, VSCode, RStudio를 기본적으로 지원합니다. 그림을 확인해보면 이미지 항목에 jupyter-tensorflow라고 되어있는데 이는 Jupyter에 Tensorflow 패키지가 깔려있는것을 의미합니다. 현재 예시는 Tensorflow가 설치된 Jupyter 환경을 이용해서 구축되어있음을 알 수 있습니다. 이런식으로 유형 및 패키지를 이미지로 선택이 가능하기에 원하는 환경을 만들어서 관리할 수 있습니다. 환경이 생성되면 CONNECT 버튼을 통하여 원하는 환경에 연결하여 개발을 진행할 수 있습니다.
6. Pipeline - Kubeflow Pipeline
본격적으로 파이프라인으로 들어가보겠습니다. 파이프라인은 Kubernetes를 사용하여 이식과 확장이 가능한 ML Workflow를 구축하고 배포하는 플랫폼입니다. Kubeflow Pipeline을 줄여서 KFP 라고 말하는데요. KFP 파이썬 SDK 혹은 직접 작성한 YAML 파일로도 누구나 쉽게 파이프라인을 구축할 수 있다는 것이 특징입니다. 사용자가 커스텀할 수 있고 기존의 ML 구성 요소들을 가져와서도 다양하게 활용이 가능합니다. 대시보드를 이용하여 파이프라인을 정의하고, 실행하고, 실험하는 것을 쉽게 시각화를 통해서 관리할 수도 있습니다.
6-1. Pipeline 구축하기
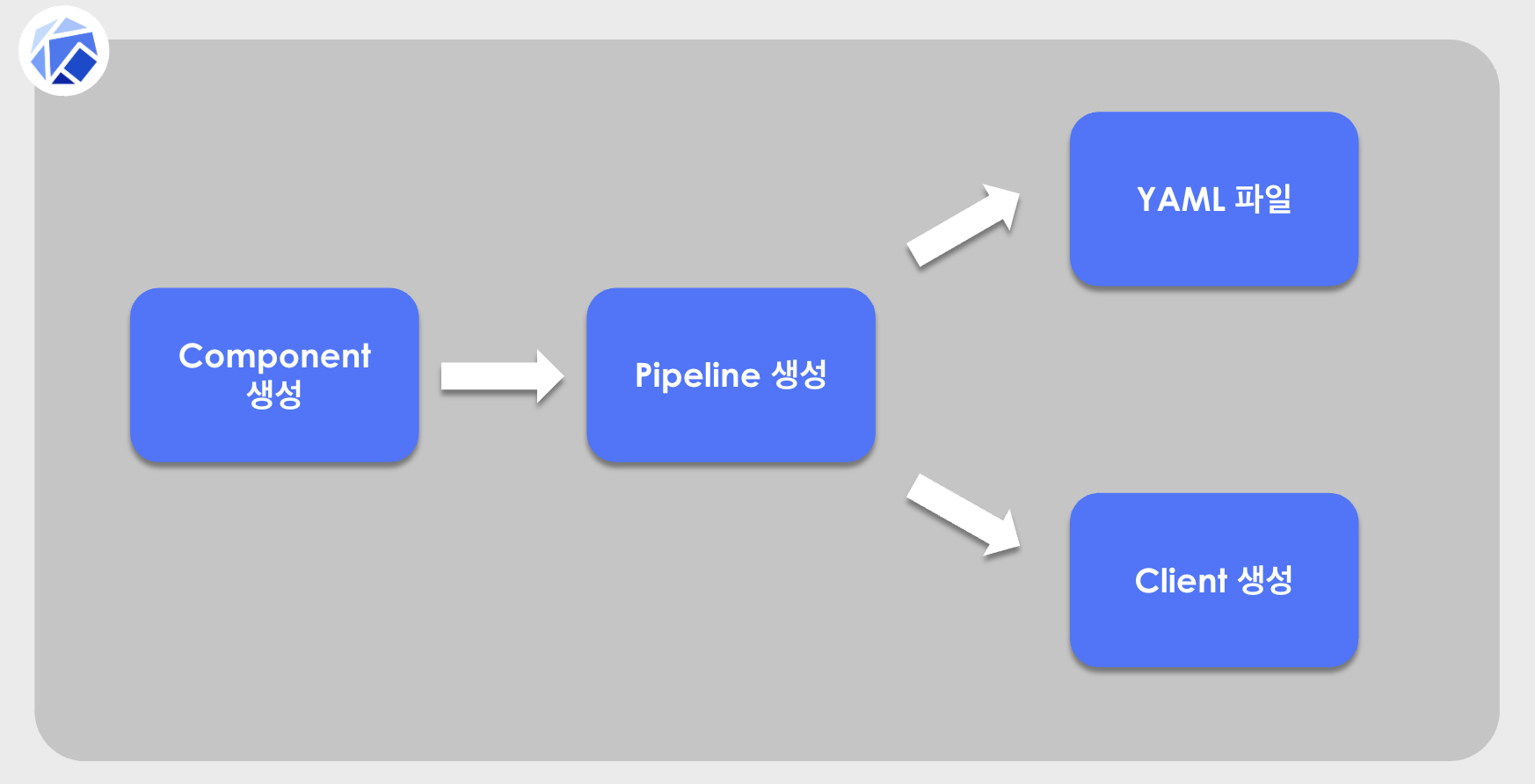
먼저 파이프라인을 구축하는 방법을 나타내면 보시는 그림과 동일합니다. 처음에는 컴포넌트를 생성하고 이러한 컴포넌트들을 엮기위해서 파이프라인을 생성합니다. 이렇게 생성된 파이프라인은 YAML 파일로 생성하거나 다른 방법으로는 Client를 생성해서 처리하는 것도 가능합니다. 이렇게 그림으로 보는 것보다는 예시를 들어서 이해하는게 조금 더 쉬울거라고 생각합니다.
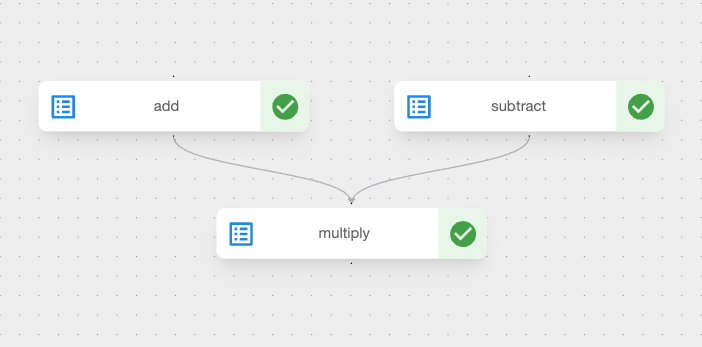
예시로 만들어볼 파이프라인을 가져왔습니다. 파이프라인을 확인해보면 add, subtract, multiply 총 3가지의 컴포넌트들로 구성되어있습니다. add, subtract의 화살표가 나중에는 multiply로 향해있습니다. 이는 add, subtract의 output을 multiply의 input으로 넘겨준다는 것을 의미합니다.
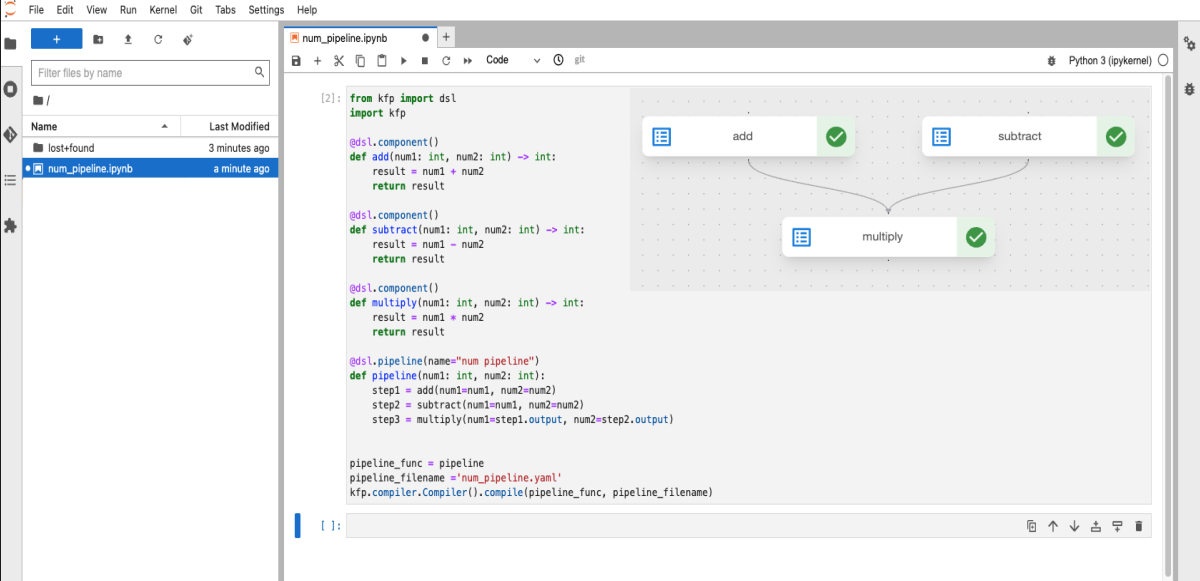
앞서 나왔던 노트북스에서 CONNECT 버튼을 통해서 들어온 JupyterLab 환경입니다. 노트북스를 이용해서 JupyterLab에서 간단하게 예시를 작성했습니다. 전체적인 코드는 이렇게 구성되어있습니다. 하나씩 살펴보도록 하겠습니다.
6-1-1) Componets 생성하기
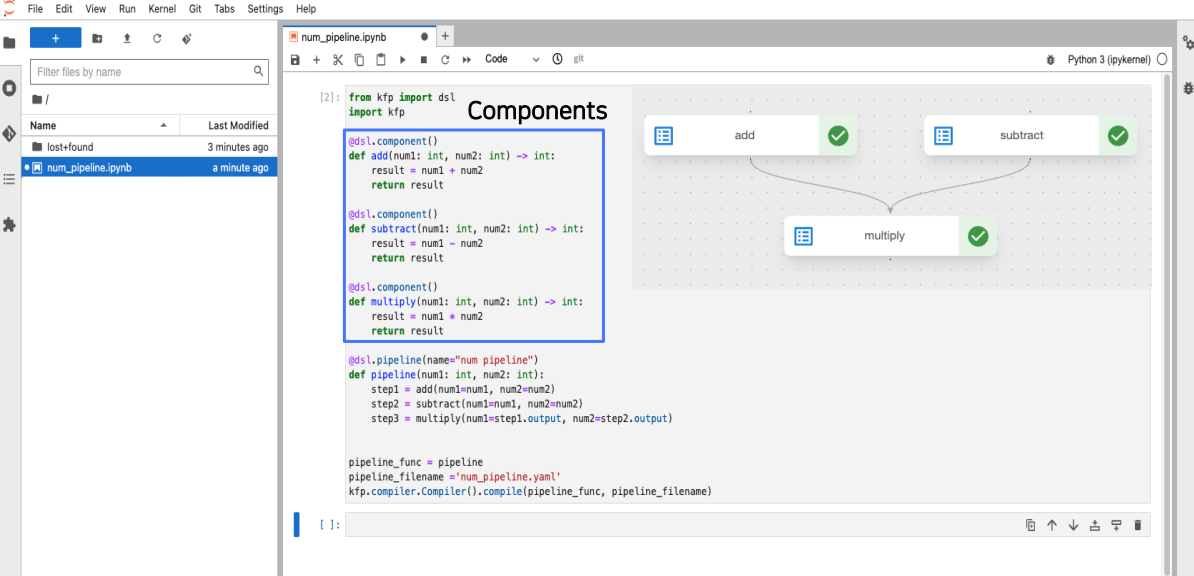
from kfp import dsl
import kfp
@dsl.component()
def add(num1: int, num2: int) -> int:
result = num1 + num2
return result
@dsl.component()
def substract(num1: int, num2: int) -> int:
result = num1 - num2
return result
@dsl.component()
def multiply(num1: int, num2: int) -> int:
result = num1 * num2
return result
@dsl.pipeline(name="client num pipeline")
def pipeline(num1: int, num2: int):
step1 = add(num1=num1, num2=num2)
step2 = substract(num1=num1, num2=num2)
step3 = multiply(num1=step1.output, num2=step2.output)
pipeline_func = pipeline
pipeline_filename ="num_pipeline.yaml"
kfp.compiler.Compiler().compile(pipeline_func, pipeline_filename)컴포넌트들의 코드는 여기에 위치하고 있습니다. 예시는 총 3개의 add, subtract, multiply 컴포넌트로 구성되어있었는데요.
한번 확인해보도록 하겠습니다.
add 함수
from kfp import dsl
import kfp
@dsl.component()
def add(num1: int, num2: int) -> int:
result = num1 + num2
return result먼저 처음으로 add와 subtract의 output이 multiply의 input으로 진행되기 위해서는 먼저 실행되어야합니다.
add 컴포넌트를 먼저 확인해보겠습니다. KFP를 import하고 dsl.component() 데코레이터를 사용해서 컴포넌트를 정의해줍니다.
dsl은 Domain Specific Language의 약자입니다. 이렇게 컴포넌트의 데코레이터를 작성하고 밑에는 add함수를 정의합니다.
add함수는 말 그대로 num1, num2를 받아와서 둘을 더하고 값을 반환해주게 됩니다.
subtract 함수
@dsl.component()
def substract(num1: int, num2: int) -> int:
result = num1 - num2
return result2번째 컴포넌트인 subtract도 동일하게 컴포넌트 데코레이터를 사용합니다. subtract은 num1, num2를 받아와서 빼기를 진행하고 값을 반환합니다.
multiply 함수
@dsl.component()
def multiply(num1: int, num2: int) -> int:
result = num1 * num2
return result마지막 컴포넌트인 multiply에서도 이제 익숙한 컴포넌트 데코레이터를 사용합니다. num1, num2값을 받아서 곱하고 값을 반환해주는 간단한 함수로 이루어져있습니다.
6-1-2) Pipeline 생성하기
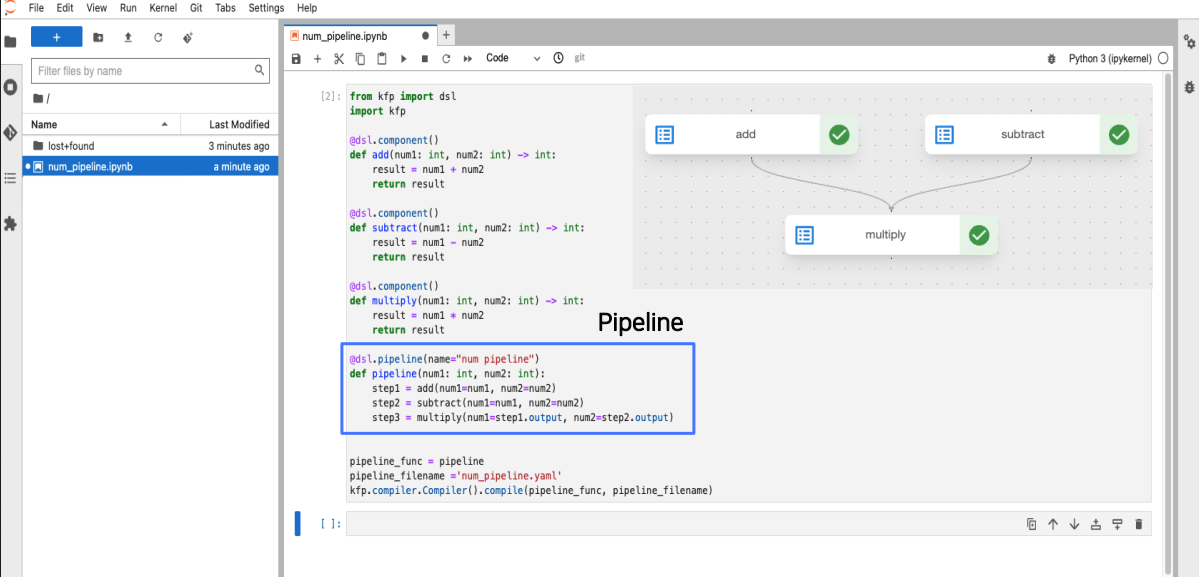
@dsl.pipeline(name="client num pipeline")
def pipeline(num1: int, num2: int):
step1 = add(num1=num1, num2=num2)
step2 = substract(num1=num1, num2=num2)
step3 = multiply(num1=step1.output, num2=step2.output)3개의 컴포넌트를 생성하는 것은 마무리되었고 이렇게 따로 정의된 컴포넌트들을 엮어주기위해서 파이프라인을 작성해야합니다.
파이프라인은 dsl의 데코레이터를 사용합니다. 파이프라인이라고 정의를 진행하고 파이프라인의 이름 지정도 가능합니다. 파이프라인을 살펴보면 num1, num2를 받아들이고 그 뒤에 정의했던 컴포넌트들이 실행됩니다.
step1은 add, step2는 subtract, step3는 multiply로 진행됩니다. 다른점은 multiply에서의 input이 step1인 add의 output, step2인 subtract의 output으로 이루어져있다는 겁니다. 이렇게 처음의 그림 예시와 동일하게 파이프라인을 구성해보았습니다.
6-1-3) YAML 생성
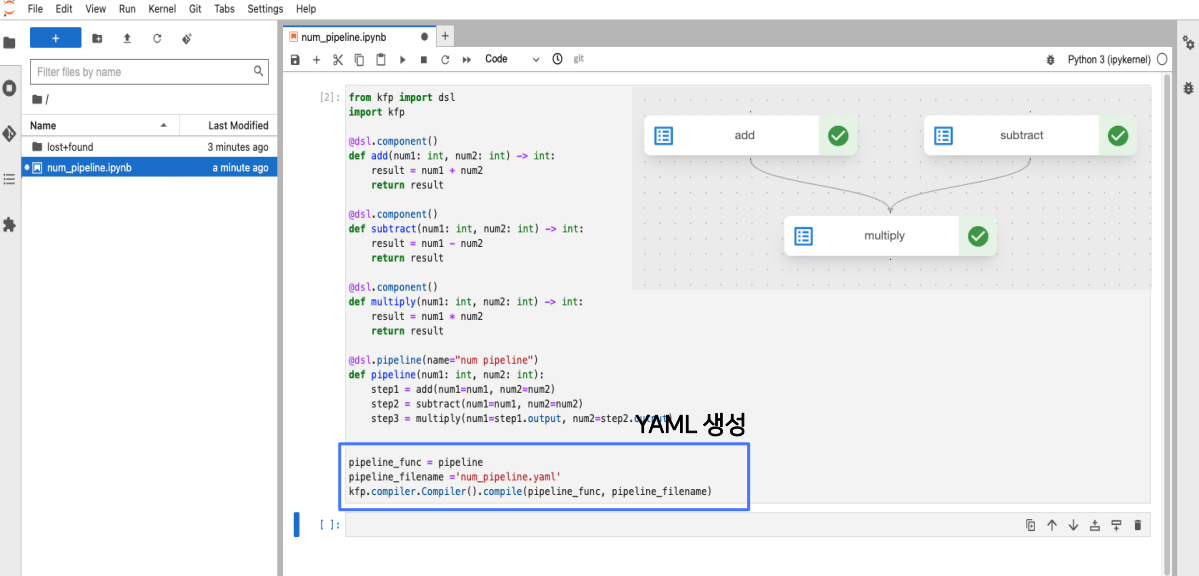
pipeline_func = pipeline
pipeline_filename ="num_pipeline.yaml"
kfp.compiler.Compiler().compile(pipeline_func, pipeline_filename)파이프라인을 생성하고 2가지의 갈래로 나누어졌는데요. YAML 파일을 사용하는 것과 Client를 사용하는 것이었습니다. 먼저 YAML 파일을 사용하는 것에 대해서 알아보겠습니다.
compiler 함수를 이용해서 YAML 파일을 생성할 수 있습니다. 파이프라인의 함수와 야물파일의 이름을 지정해서 생성합니다. 예시에서의 야물 파일의 이름은 num_pipeline.yaml입니다.
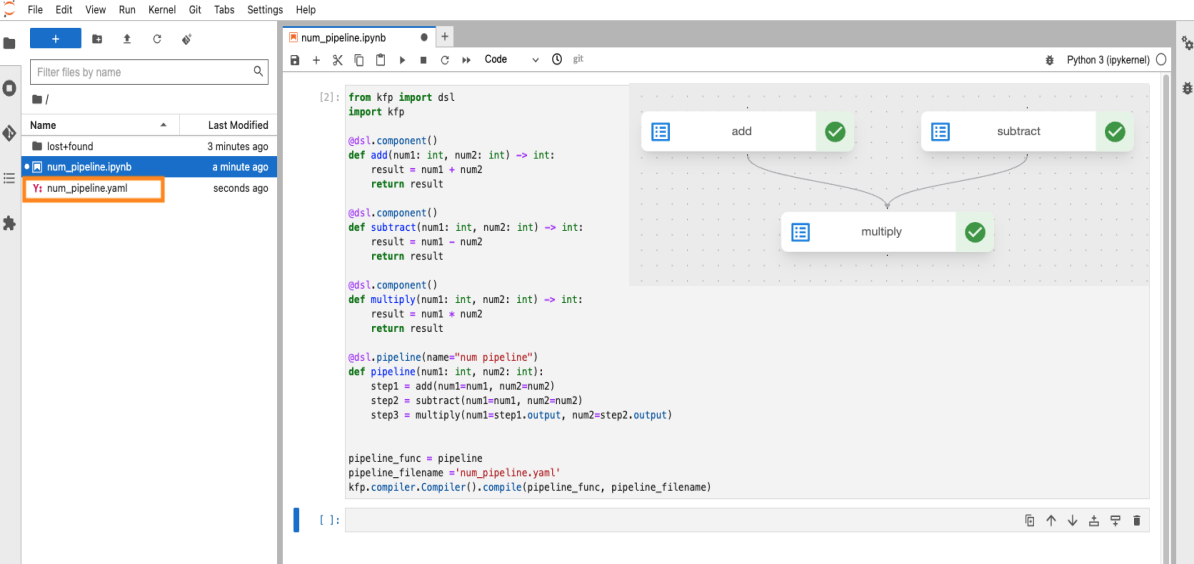
실행해보면, 지정한 이름대로 num_pipeline.yaml파일이 생성된 것을 확인할 수 있습니다.
6-1-4) YAML 가지고 UI를 활용하여 생성하기
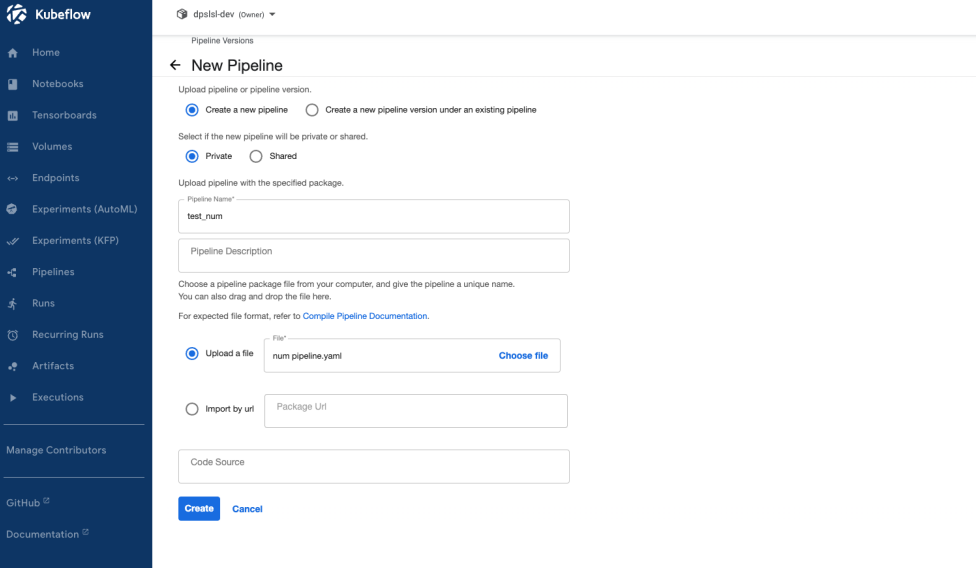
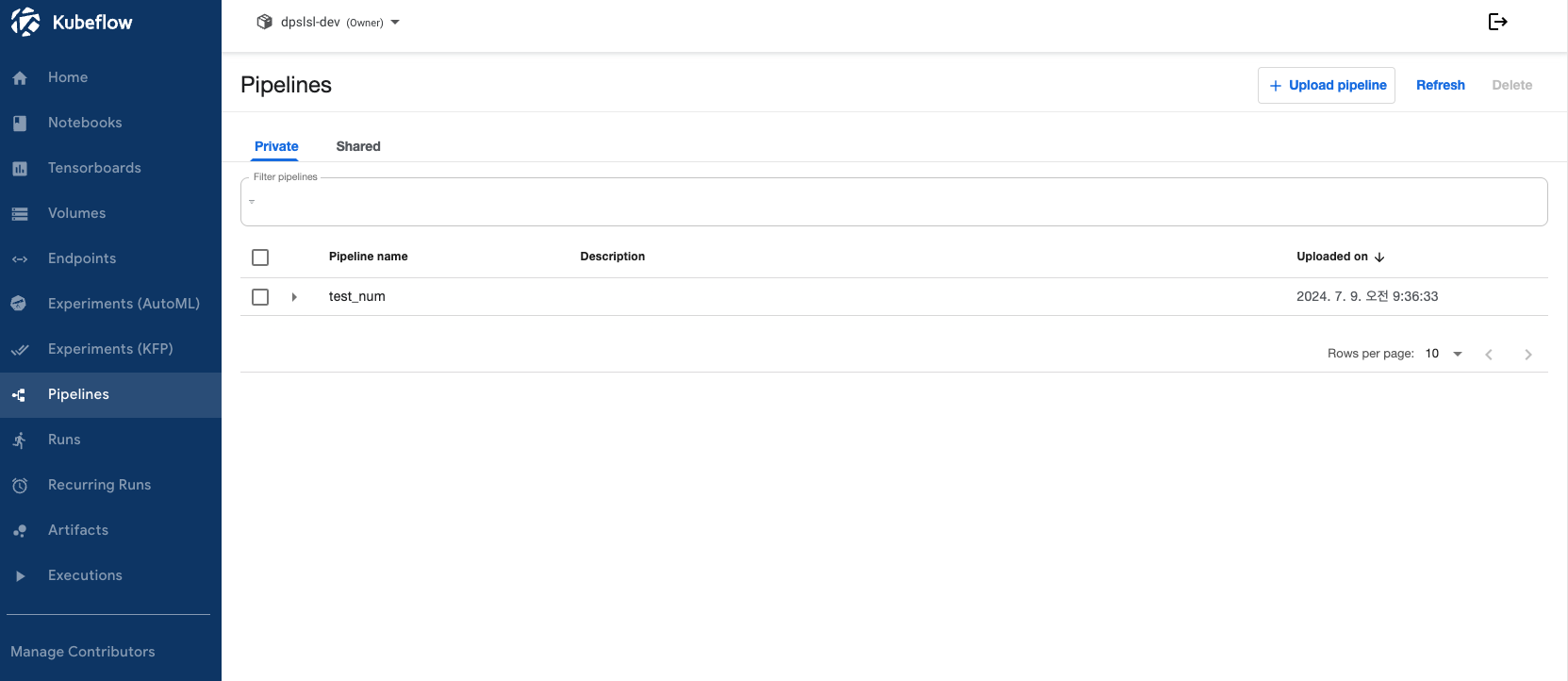
생성된 YAML 파일을 가지고 UI를 이용해서 파이프라인을 생성해보도록 하겠습니다. UI는 대시보드를 이용하여 Pipelines -> New Pipeline을 통하여 생성할 수 있습니다. 파이프라인의 이름을 명시하고 추가적으로 파이프라인에 대한 설명을 작성할 수 있습니다. 파이프라인의 이름을 test_num이라고 명시하겠습니다. Upload a file 을 클릭하여 YAML 파일을 선택하여 업로드를 진행해주면 파이프라인이 생성됩니다.
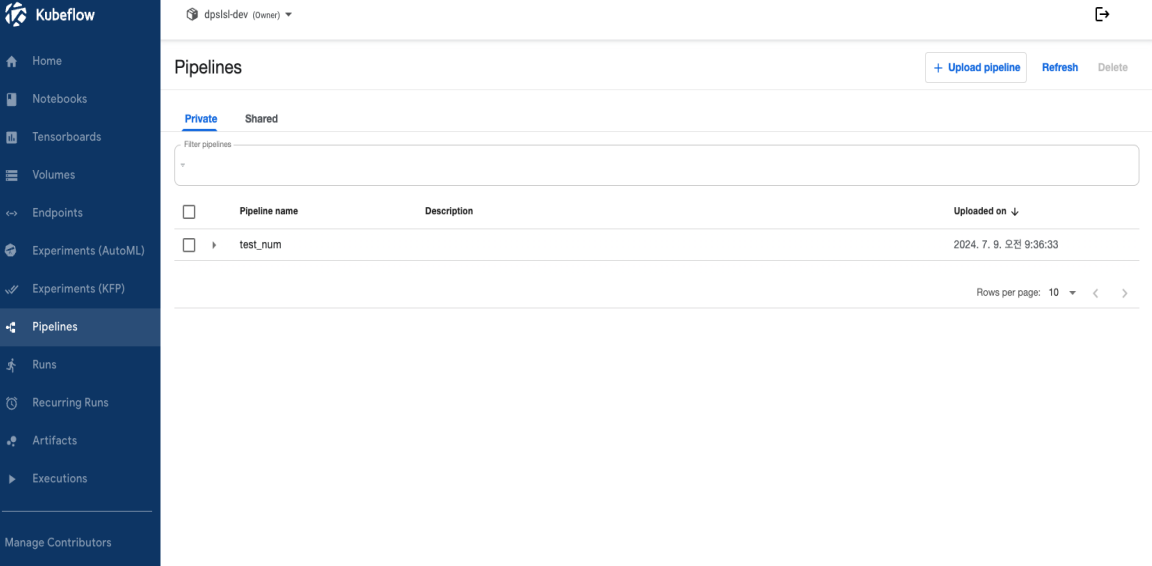
대시보드에 들어가서 확인하면 test_num이라는 명시했던 그대로의 이름으로 파이프라인이 생성된 것을 확인할 수 있습니다.
6-2) Pipeline 버전 관리
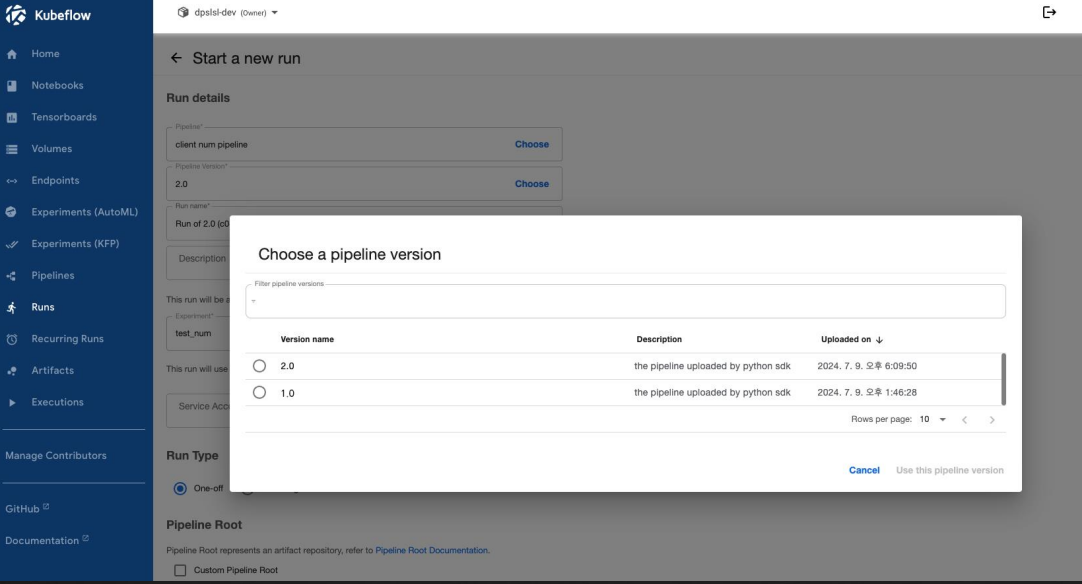
파이프라인의 내용이 수정되는 경우도 존재하는데요. 이럴 때는 파이프라인의 버전 기능을 사용할 수 있습니다. 파이프라인에 버전을 명시해서 버전별로 실험을 생성하고 실행하며 버전 관리가 가능하게 됩니다.
여기까지 파이프라인의 생성 과정이었고 아직 생성한 파이프라인을 실행하여 그 안의 프로세스들이 잘 돌아가는지는 확인하지 않았습니다. Kubeflow에 컴포넌트에 대해서 하나씩 설명하다보니 길어져서 다음 Kubeflow 알아보기 2탄에서 Kubeflow Pipeline 실행방법과 아직 남은 컴포넌트인 Model Training, Model Serving, AutoML에 대해서 다뤄볼 예정입니다. 2탄에서 만나요👋
'챱챱' 카테고리의 다른 글
| [Kubeflow] 나야 Kubeflow 2탄 (feat. Kubeflow 알아보기2) (3) | 2024.11.08 |
|---|---|
| [글또] 글또 10기를 바라보며 다짐하는 것들 (1) | 2024.10.10 |
| [글또] 삶의 지도 (6) | 2024.09.21 |
| 🧿 [MariaDB] CSV import 하기 (0) | 2024.01.21 |
| 🎈 [Ubuntu] Yarn 설치 (0) | 2023.11.10 |



