5-2) 빅데이터 로그 생성기 실행
차량의 실시간 운행정보를 가짜로 만들기
* 가짜 운행정보를 만들어주는 DriverLogMain 실행하기
server02에서 root계정으로 실행해줄건데 server02로 하는 이유는 server01이 현재 Name Node등의 정보들을 처리하고있어서 바쁘기 때문에 server02로 설정해준거라 server01로 해도 상관은 없다.
5-2-1) 실행파일을 실행시키기
cd /home/pilot-pjt/working/
java -cp(자바의 실행 명령) bigdata.smartcar.loggen-1.0.jar(가짜 운행정보를 만드는 실행 파일) com.wikibook.bigdata.smartcar.loggen.DriverLogMain 20210422(날짜) 100(갯수)실행시키면 자동으로 압축을 풀어서 실행한다. 무한루프를 도는 프로그램이니 Ctrl + c로 루프를 빠져나와야한다.
5-2-2) 생성된 가짜 자동차 정보를 출력하기

첫번째줄은 파일을 조회할 위치로 들어가는 역할을 한다.
두번째줄은 tail -f를 써서 조회한다.
tail -f파일의 맨 끝 10줄을 조회하는데 실행후에 커서가 깜빡일텐데 이건 파일의 내용이 추가될 때까지 멈춰서 기다리는 것이다. 파일의 맨끝에 3줄이 추가되면 새로운 맨끝의 10줄이 출력된다. 이 때도 역시 Ctrl + c로 빠져나오면 된다.
사진에도 나와있지만 조회된 순서는
일시(년, 월, 일, 시, 분, 초), 차번호, 가속 단계(0~5), 브레이크 단계(0~3), 운전대, 방향지시등(R:좌, L:우, N:안킴), 속도, 지역
으로 구성되어 있다.
5-3) 실시간 데이터 생성 및 카프카 토픽 저장
5-3-1) 플럼 설정
www.server01.hadoop.com:7018 에 접속하기
Flume -> 구성 -> agent -> 이름은 건들이지말고 구성 파일을 새로 구성하기(강사님이 주신 SmartCar_Agent_Realtime복붙) -> 변경내용저장 -> Flume 옆에 돌아가는 라운드 버튼 -> 클러스터 새로고침 -> 완료 후 Flume 재시작
5-3-2) DriverLogMain 실행
위의 빅데이터 로그 생성기 실행하기와 같이 진행해준다.


6-3-3) 카프카 토픽 확인
카프카에서 가져오는 역할을 하는 것은 consumer이므로 consumer를 사용한다.


beignning을 통해서 처음부터 모든 데이터를 확인할 수 있다.
6) Apachce Spark
6-1) Apahce Spark Streaming
리눅스를 이용해서 Spark를 사용할 예정인데 Anaconda의 jupyter notebook은 돌리기에 너무 오래걸려서 Zeppelin을 이용해서 할 예정이다.
Zeppelin은 '실무로 배우는 빅데이터 기술' 책 307p, 321p를 참고해서 설치했다.
<Zeppelin 실행하기>
6-1-1) Zeppelin을 설치한 server02를 putty로 실행한다.
6-1-2) root로 들어가서 버전 확인하기
source /opt/rh/python27/enable
python --version을 입력해서 파이썬 버전도 확인하기
6-1-3) cd /home/pilot-pjt/zeppelin에서 실행하기
cd /home/pilot-pjt/zeppelin
zeppeline-daemon.sh start입력해서
Zeppelin start [OK]
출력된다면 실행된 것이다.
6-1-4) server02.hadoop.com:8081 들어가서 Zeppelin사용하기
* Lambda 표현식
- Spark를 사용하기위해서는 람다 표현식을 알아야한다.
6-1-5) 함수 만들기

x에 값에 10을 넣어주는 함수를 작성했다.
Zeppelin에는 여러가지가 사용되기때문에 밑에 무슨 언어를 쓸지에 대해서 적어주어야한다.
%spark.pyspark로 spark를 쓰겠다고 지정해준것이다.
6-1-6) 만든 함수 실행하기

실행하기전에 server01.hadoop.com:7180/에서 spark를 다시 재시작해준다.
실행을 확인해보면 255값에 10이 더해진 값이 return된다.
6-1-7) 람다 표현식으로 함수 만들기

리턴값이 딱 한줄인 애들은 Lambda 표현식으로 변경할 수 있다.
위의 def함수랑 똑같은 결과를 가지는 Lambda 표현식이 생성되었다.
Lambda 표현식에서 변수를 선언하거나 리턴값이 하나가 아니라면 에러가 나기때문에 조심해야한다.
* Map, Apply 사용
6-1-8) 리스트 실행하기

우리가 파이썬에서 사용하는 리스트를 사용할 수 있다.
반복문안에 조건, 반복문들이 계속 반복되다보면 들여쓰는 것들이 헷갈릴때가 있는데 그럴때는 리스트안에 있는 것들을 옆으로 길게 쓸 때 사용하는 것은 map이나 apply를 사용하면 된다. R에서 Map과 같은 Apply를 사용해서 파이썬에도 Apply가 생겼다. 둘 중 어느걸 사용해도 되지만 map으로 만들어볼려고 한다.
6-1-9) Map으로 실행하기

Map에서는 이렇게 실행되는데 list의 값들을 마지막 데이터까지 순서대로 1개씩 꺼내서 실행한다.
6-1-10) 람다 표현식으로 Map 사용해보기

사진과 같이 위와 같은 결과값을 가질 수 있다.
6-1-11) Map을 이용해서 조건문 사용하기

평소에 쓰던 문법들과는 다르게 True문 if 조건문 else False문으로 사용한다. elif는 사용할 수 없고 :도 사용할 수 없으니 조심해야한다. elif대신 조건문을 이어쓰면 된다.
6-1-12) Map을 이용한 2개의 조건문

이런식으로 옆으로 이어서 조건문을 붙여주면 된다.
6-1-13) 함수로 조건문들을 합쳐주기
위처럼 함수들을 길게 나열하는게 힘드니 함수를 사용해서 같은 값을 얻을수도 있다.

6-1-14) 여러리스트를 사용해서 조건문 써보기

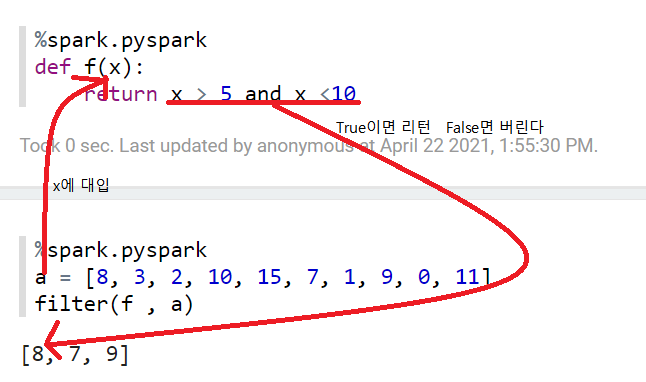
* Filter 사용하기
리스트를 쑥 뽑아서 함수를 실행한다.
6-2) 파이썬을 이용한 Hbase 사용
put, scan등의 명령어를 직접 입력하기가 힘드니깐 python에게 시킬 수 있다.
* Spark 개발환경 실행
6-2-1) Hbase 테이블 생성
먼저 server01.hadoop.com:7180/에서 Hbase를 재시작한다.
server02에서 테이블 생성하기

6-2-2) happybase 설치하기

happybase란 라이브러리를 설치하는데 파이선에서 Hbase에서 데이버를 수정, 삭제 할 수 있게 한다.
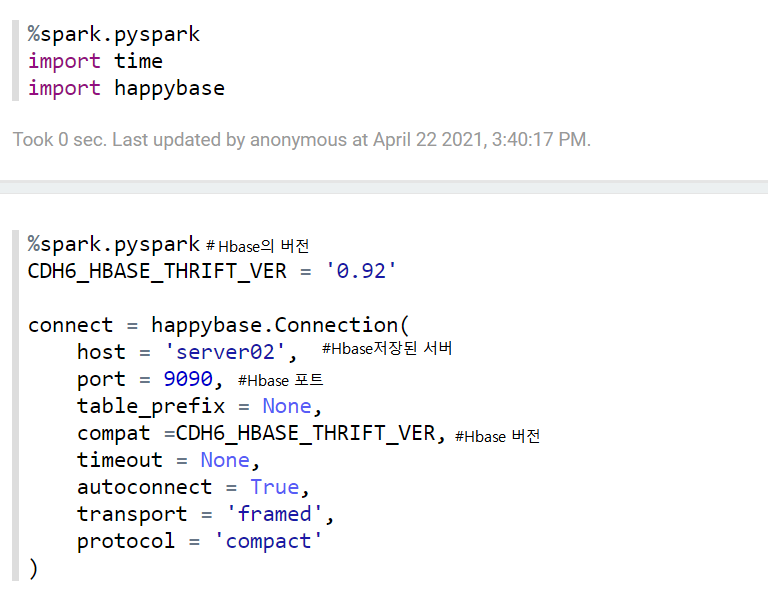
6-2-3) 새로운 파일 생성

6-2-4) happybase 가져오기

spark를 쓰겠다고 위에서 선언하고 import를 통해서 happybase를 가져온다.
* Thrift 서버

Thrift서버는 Master 대신에 python의 요청을 접수하고 Master가 한가해지면 요청을 전달하는 역할을 한다.
※ Thrift서버의 위치 확인하기
Name node(server01.hadoop.com:7180/)-> hbase -> 인스턴스 -> HBase Thrift Server 확인 가능

용량을 너무 많이 차지하니 Flume, HDFS, Kafka, Spark, Yarn, Zookeeper 만 시작하고 나머지 서비스는 중지하기
6-3) Hbase 접속 Spark 프로그래밍
6-3-1) Zepplin에서 새 파일을 만들기

6-3-2) Hbase Thrift 서버 접속하기

조회되는지도 확인해본다.
6-3-3) Hbase stock 테이블에 데이터 추가

Hbase stcoks에 테이블을 추가하기전에 먼저 접속을 해줘야한다.

접속 후 테이블을 입력해준다. put을 이용해서 입력해주는데 PK, 컬럼패밀리, 컬럼명, 컬럼값을 입력해줘야한다.
6-3-4-1) Scan을 이용한 테이블 추가 확인하기

Hbase명령어를 실행하기전에 hbase shell을 입력을 먼저해주고 scan을 이용해서 stocks 테이블을 조회한다.
6-3-4-2) Spark를 이용한 Hbase 테이블 레코드 조회

Hbase에서 for문으로 돌려서 테이블을 조회할 수 있다.
※ 만약에 오류가 난다면
1) 처음부터 하나씩 실행하면 오류가 없어진다.
2) 혹은 Name Node(server01.hadoop.com:7180/)를 들어가서 작동하고 있는지 확인해야한다.
※ 나중에 스파트 스트림을 사용할 때, 스트림은 백그라운드 작업으로 무한루프를 돌면서 계속 옮기기때문에 강제 종료해줘야한다.

interpreter -> spark -> restart 입력해서 종료하기
'PBL 빅데이터 > 빅데이터 플랫폼' 카테고리의 다른 글
| [수업] 빅데이터 플랫폼5 (0) | 2021.04.26 |
|---|---|
| [수업] 빅데이터 플랫폼4 (0) | 2021.04.23 |
| [수업] 빅데이터 플랫폼2 (0) | 2021.04.21 |
| [수업] 빅데이터 플랫폼1 (0) | 2021.04.20 |



