1) Hive
1-1) Hive소개
- Hive는 Hadoop의 HDFS에 저장되어 있는 파일을 SQL Query로 처리하기 위한 환경을 제공하기 위한 오픈소스이다.
현업에서는 보통 Hive를 많이 사용한다.
- 검색, Join을 하기위해서 제공된 오프소스이다.
- 근본적으로 Hive로 Data Warehouse(보고서)를 구죽하기 위한 목적으로 만들어졌다.
- SQL Query 형식의 질의언어를 이용한 데이터 처리 지원한다.(집계:group by)
- MapReduce 방식에 비해서 편리하다는 장점이 있지만 데이터가 MySQL과는 다르게 여러군데에 분산되어 있다보니 처리속도가 느리다.
1-2) 실습환경 만들기
1-2-1) data폴더가 들어있는지 확인하기
강사님이 만들어두신 data폴더가 실습을 위해 현재 server02에 위치해 있는지 확인해야한다.

데이터 폴더안에 파일들이 들어가있음을 확인할 수 있다.
1-2-2) 서비스 재시작: HDFS, Hive, Yam, Zookeeper 재시작, 나머지 서비스 중지

어떤 오류가 생길지 모르니 재시작해준다. 용량이 부족하므로 사용하지않는 나머지들은 정지시킨다.
1-2-3) 내 컴퓨터의 data 폴더의 names.csv를 HDFS에 업로드

csv 파일을 이동해주어야한다.
- 먼저 디렉토리를 data로 이동해주어야한다.
- Hadoop에 /user/hdfs/names 폴더를 생성해주는데 -p는 중간에 없는 폴더라고 생성해준다.
- names.csv를 Hadoop의 /user/hdfs/names 폴더에 업로드해준다. 현재는 내컴퓨터에 있으니 server02로 옮긴다.
- -ls를 이용해서 디렉토리를 조회한다.
다시 한번 데이터 구조에 대해서 적어보자면

이런식으로 구성되어있다고 보면 된다.
1-2-4) Hive 실행
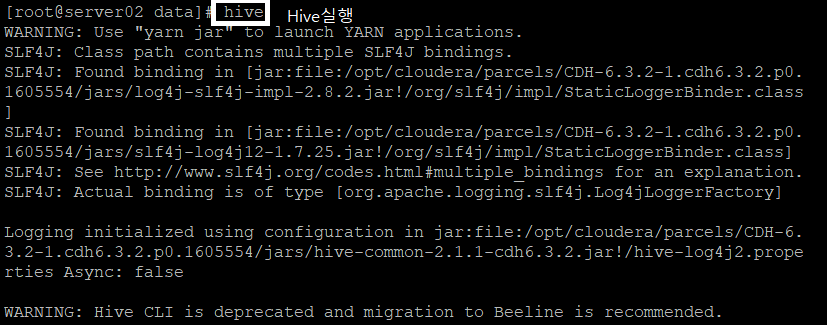
hive를 입력해서 Hive를 실행한다.
1-2-5) 테이블 생성

테이블을 생성해주는데 위에 적힌 CREATE EXTERNAL TABLE IF NOT EXISTS Names_text의 의미는 Names_text파일이 존재하지 않을때, HDFS, NO SQL의 데이터를 분석할 Table(아직 분석은 안됨)을 생성한다는 뜻이다. MySQL처럼 대소문자를 구별하지않는다. MySQL과 같이 대소문자를 구분하지않는다.
1-2-6) 테이블 조회

Select를 통해서 저장된 데이터를 조회하면 데이터가 현재 들어있는 것을 확인할 수 있다.
2) Hive를 이용한 상품평 분석
저번에도 그랬듯이 이번에도 server01.hadoop.com:7180 접속접속해서 HDFS, Hive, Yam, Zookeeper재시작, 나머지 서비스는 정지하기
2-1) HDFS에 csv파일 업로드할 폴더 생성

장부를 저장할 /user/cloudera 폴더를 생성한다. Name Node안 /user/cloudera/에 만든다.
2-2) 평점이 낮은 물건 조회하고 평점에서 가장 많이 나오는 단어 조회
2-2-1) 분석할 파일을 HDFS 업로드할 폴더 생성

-mkdir을 통해서 장부를 저장할 폴더를 만든다.
2-2-2) 파일을 업로드하고 조회하기

내 컴퓨터의 위치한 ratings_2013.txt를 HDFS의 경로에 옮겨준다. 옮긴 후 -ls를 통해서 저장된 리스트를 조회한다.
2-2-3) HDFS에서 조회하기

옮겨줬으니 재대로 옮겨졌는지를 HDFS에서 확인한다.
2-2-4) Hive 실행

2-2-5) Hive에서 테이블 생성
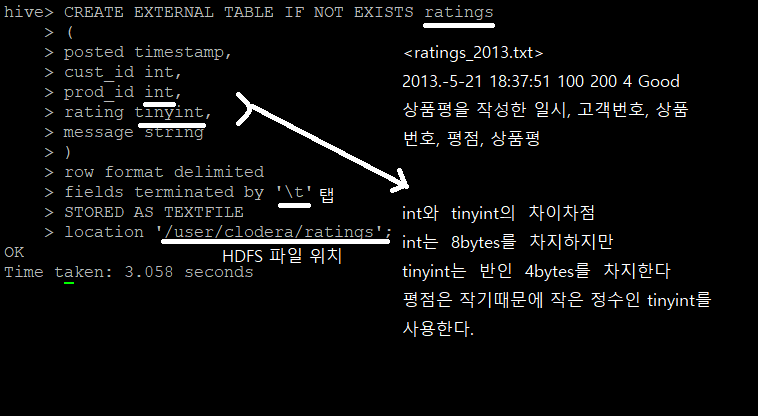
ratings_2013.txt에서
1) 평점이 제일 낮은 것
2) comment에서 제일 많이 사용한 단어를 검색하기 위해서 테이블을 만든다.
2-2-6) 테이블을 조회

테이블을 생성했으니 테이블을 조회해야한다. limit 10은 10개를 조회한다는 의미로 들어갔는지 빠르게 확인하기위해서 사용한다.
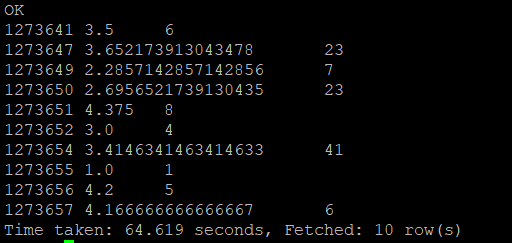
2-2-7) 물건 번호로 그룹을 묶어서 제품을 조회하기
MySQL에서 사용하던 명령어들을 다 사용할 수 있으며, 특수한 MySQL의 기능을 제외하고는 사용가능하다.

2-2-8) 게시물의 개수가 50건 이상인 조건으로 조회

함수를 조건할 때에는 where이 아니라 having을 사용한다.

2-2-9) 평균평점을 별칭 부여해주기
- select 명령 실행시 테이블의 컬럼명이 조회되도록 설정
set hive.cli.print.header=true;


2-2-10) 게시물의 평점 평균이 낮은 순으로 정렬

order by를 사용해서 정렬해준다.
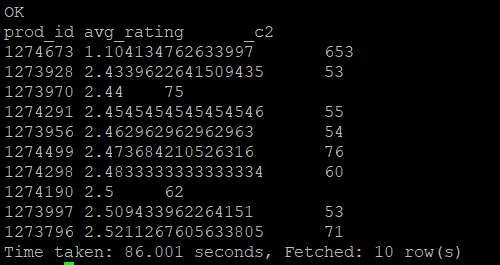
2-2-11) 평점이 가장 낮은 1줄을 조회

limit를 통해서 1개를 지정해주고 조회한다.

2-2-12) 평점이 가장 낮은 prod_id = 1274673의 메세지를 조회

select 다음에 message로 변경해서 message를 조회한다.
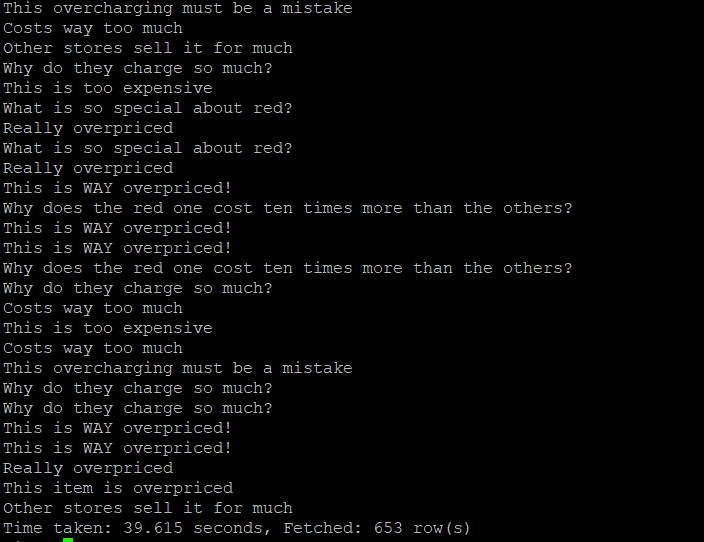
653줄의 상품평들이 조회되는데 많아서 보기가 어렵다.
2-2-13) 메세지를 소문자로 변환해서 조회
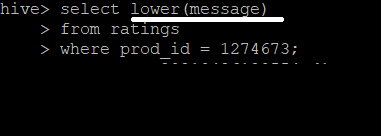
lower을 통해서 소문자로 변경할 수 있다.

2-2-14) 메세지를 단어 단위로 분리
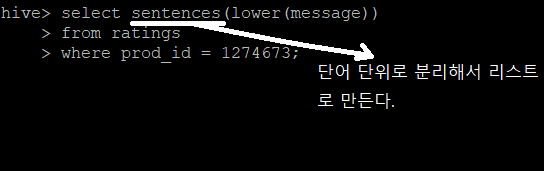
sentence를 사용해서 단어 단위로 분리해서 리스트에 넣을 수 있다.
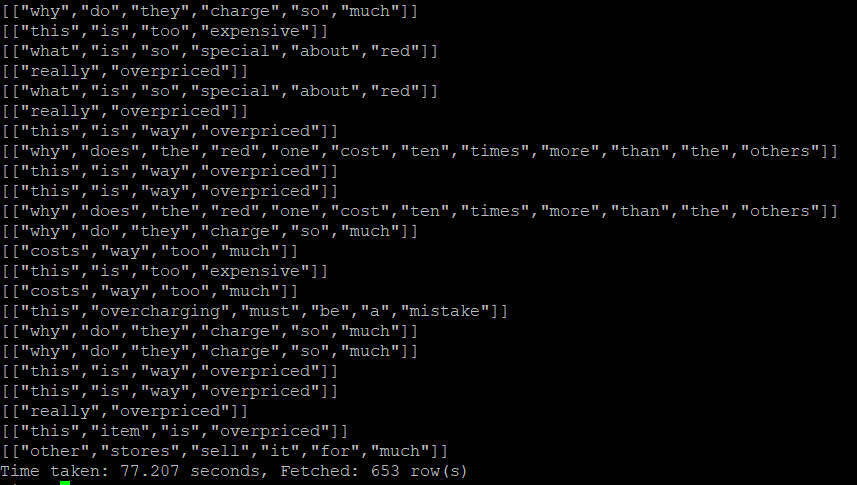
2-2-15) 연속된 3개의 단어 중에서 가장 많이 나온 단어 5개 조회

ngrams을 사용해서 조회할 수 있는데 3은 연속된 3개의 단어를 5는 가장 많이 나온 단어 5개를 의미한다.

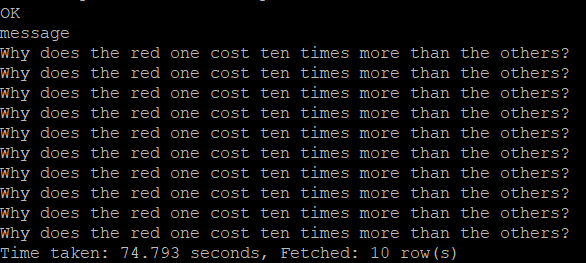
2-2-16) ten times more이라는 단어를 포함하는 메세지 조회

평점이 제일 낮은 물건 메세지안에서 ten times more이라는 단어를 포함하는 메세지를 조회한다.
2-2-17) 중복을 제거하고 조회하기
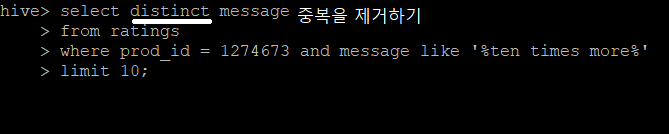
distinct을 사용해서 중복을 제거한다.

빨간색이 10배 더 비싸다는 상품평이 있는데 이에 대해서 빨간색에 대한 조회가 필요하다.
2-2-18) red가 들어간 메세지를 조회


빨간색 제품에 대해서 안좋은 메세지들을 확인할 수 있다. 문제가 있음을 확인하였으므로, 빨간색 제품에 대해서 정보 조회가 필요하다.
2-3) 평점이 낮은 물건의 가격 정보 조회
2-3-1) 하이브를 종료하고 하둡에 제품 정보 로드
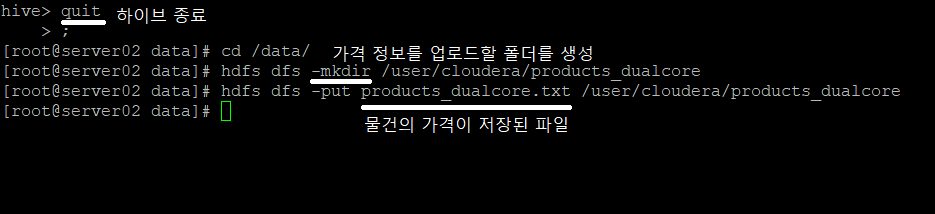
2-3-2) 테이블 생성
테이블생성은 다시 Hive에 들어가서 해줘야한다.

2-3-3) 테이블 조회
테이블을 위에 했던 것과 같이 limit를 사용하여 조회한다.
2-3-4) 127463의 정보 조회


2-3-5) Orion사의 다른 제품들도 조회하기

Orion사의 다른 제품들에게 문제가 있는지 확인해보기 위해서 조회해본다.
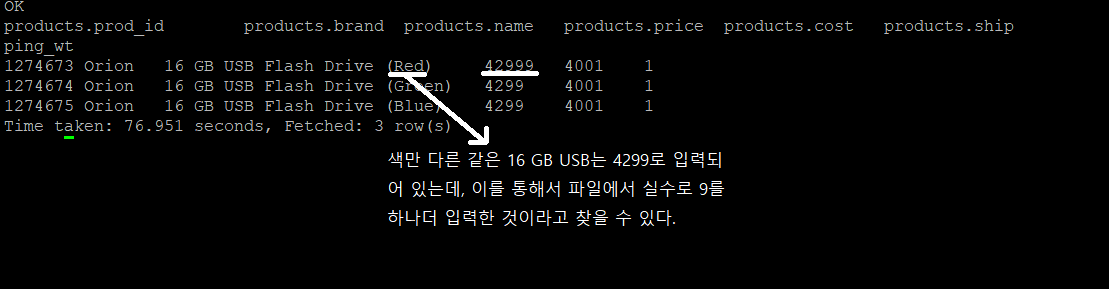
색만 다른 같은 물품들이 4299 가격인 것을 알 수 있다. 색만 다른거라서 파일에서 입력할 때, 실수로 9를 하나 더 입력한 것이라는 것을 알 수 있다.
이를 통해서 평점이 낮은 물건과 왜 평점이 낮은지에 대해서 알 수 있었다.
'PBL 빅데이터 > 빅데이터 플랫폼' 카테고리의 다른 글
| [수업] 빅데이터 플랫폼4 (0) | 2021.04.23 |
|---|---|
| [수업] 빅데이터 플랫폼3 (0) | 2021.04.22 |
| [수업] 빅데이터 플랫폼2 (1) | 2021.04.21 |
| [수업] 빅데이터 플랫폼1 (0) | 2021.04.20 |



