여태까지 했던 스마트카에 대해서 실습
1) 실시간 운행 정보 저장
1-1) 실시간 운행 정보 생성
* Name Node 오류
실시간 정보를 카프카를 저장하는 실습을 하기위해서 Name Node에 들어갔는데

이런식으로 오류가 나왔는데 서버도 다 켜져있는 상태여서 강사님께 여쭤보니 크롬은 데이터를 저장해서 계속 값을 가지고 있어서 한번 오류가 나면 계속 난다고 하셨다.
* 오류 확인

service cloudera-scm-server status명령어를 통해서 현재 커져있는지 확인할 수 있었다. 난 running상태로 켜져있었고 크롬이 아닌 마이크로소프트 엣지로 진행해보니 접속이 가능했다. 크롬에 저장값이 있다고해서 크롬의 쿠키를 하루치 삭제해보니 접속이 능했다.
오류가 난다면,
1) 켜져있는 확인
2) 크롬이 아닌 다른 브라우저로 사용해보기
* 스마트카 복습 및 실습에 필요한 지식
1) 다시 실습으로 돌아와서, 저번 수업의 silver-ye.tistory.com/8 6-2) 빅데이터 로그 생성기 실행, 6-3) 실시간 데이터 생성 및 카프카 토픽 저장 부분을 오늘 날짜로면 변경하고 진행해준다.

날짜를 오늘 날짜로 변경해서 다시 데이터를 생성해준다.

출력해보면 현재 운행정보들이 오늘 날짜로 나오는 것을 확인할 수 있다.
2) Zeppelin 실행하기

이런식으로 생성한다.
3) Zeppelin 종속 데이터 만들기
3-1) time에 대해서 알아보기

처음에 어떤 언어를 사용할건지 지정하고 time을 import한다.
time의 역할은

위의 코드는 2초간 멈춰있다가 실행되는데 time.sleep을 통하여서 멈췄다가 실행되는 것이다.
3-2) 종속관계 만들기

SparkConf -> SparkContext -> StreamingContext 이루어진 종속된 관계를 만들어볼 것이다. 종속 관계는 우리가 생각하는 가족 관계도와 같이 조부모님이 계셔야 부모님이 계시고 부모님이 계셔야 자식이 있듯이 먼저 생성할 것은 SparkConf이다.
3-2-1) 조부모(SparkConf) 생성

3-2-2) 부모(SparkContext) 생성

3-2-3) 자식(StreamingContext) 생성

3-3) 연결하기

3-4) kvs 지정

3-5) 출력할 라인을 지정해주기

3-6) scc 일시키기

scc가 일을 시작하면서 받아온 라인들을 출력시킨다.
3-7) 운행정보 생성 지우기
라인들을 출력하는건 용량을 많이 차지하기에, 용량이 적어서 힘들어하는 컴퓨터를 위해서 지워주어야한다.
3-7-1) 지워야 할 파일을 찾기

ps -ef | grep 찾아야할 파일에 포함된 이름
3-7-2) kill이용해서 지우기
지우기를 실행하면

grep을 통해서 나온것들중에 지울 파일들의 root뒤의 번호를 기억해야한다. root의 뒷번호는 다 다르니 본인이 원하는 파일의 번호를 복사해야한다.
kill -9 root뒷번호를 입력하면 삭제되는데 이 때의 -9는 곧장 지운다는 의미이다.
4) splict 알아보기
4-1) 문자열
파이썬에서 문자열은 글자가 들어있는 리스트이다.

4-2) 문자열을 특정 글자를 기준으로 분리해서 리스트에 담아서 리턴하기(split)

split을 이용해서 기준을 정하고 그 기준을 통해서 문자열이 나뉘어서 리스트에 들어가게된다. 이 때에 리스트를 받을 변수를 지정해줄수도 있다.

4-3) 위의 만든 lst1를 이용해서 문자를 뽑아내기

Good의 3번째 인덱스를 lst1[1][3]으로 뽑아내기도 가능하다.
2) 실시간 운행 정보 실습
2-1) 가상환경 메모리, 저장용량 증가
2-1-1) Virtual Box server 끄기

2-2-2) server01 메모리 설정하기

설정 -> 시스템 -> 기본메모리 -> 7168MB
2-2-3) server02 메모리 설정하기

설정 -> 시스템 -> 기본메모리 -> 5120MB
2-2-4) server01 저장용량 증가

파일 -> 가상 미디어 관리자-> server01 -> 크기 45GB -> 적용
2-2-5) server02 저장용량 증가

파일 -> 가상 미디어 관리자-> server02 -> 크기 45GB -> 적용
2-2-6) server01을 putty로 시작해서 설정
server01을 키고
저장해놓은 server01을 load해서 open으로 실행해준다.
2-2-7) server01 설정



reboot로 인해서 server01이 다시 실행되니 실행될 때까지 기다리다가 다시 putty로 접속한다.

다시 한번 reboot를 해주면 끝난다.
2-2-8) server02 설정

위의 server01 설정과 같은 방법으로 server02를 putty로 시작해서 진행하면 된다.
2-2-9) 확인

디스크 사용량과 물리적 메모리가 늘어난것을 확인할 수 있다.
2-2) 재시작
server01.hadoop.com:7180->Flume, Hbase, HDFS, Kafka, Spark, Yam, zookeeper 재시작
-> 나머지 서비스는 켜져있으면 종료
2-3) Kafka 데이터 Hbase 저장
2-3-1) DriverLogMain 실행하기

가짜 운행 정보를 생성하고 그 실행 정보를 조회한다. 두번째 명령어에서 &를 쓰면 10개만이 아닌 좌르륵하고 다 나오게 되니 Ctrl + c를 통해서 빠져나와야한다.
2-3-2) Kafka 토픽 확인

가짜로 생성한 운행 정보가 카프카의 메세지를 저장하고 창고 토픽에 저장되어있는지 확인한다.
2-3-3) Kafka 토픽에 저장된 데이터 읽어오기

Python version이 2.7이상인지 확인해야한다. 안하면 오류가 날 수 있으니 주의하고 진행해야한다. 그 후에 Zeppelin을 실행시킨다.
2-3-4) Zeppelin 파일 만들기

현재 이미지는 이미 생성되어있지만 kafka_read_hbase_write_01 파일을 생성해준다.
2-3-5) Spark로 Hbase 연결하기

어제 설명한 종속 관계를 똑같이 사용한다. 현재 conf가 2개라서 헷갈릴 수 있지만 conf = conf에서 앞의 conf는 변수명을 뒤의 conf는 변수값을 받는거니 주의해야한다.

어디에 연결해야하는지를 알려줘야해서 설정해준다.

line_split_col로 ,(콤마)로 split한 데이터를 받아서 리스트로 넣어준다. 원래 line은 하나의 문자열로 이루어져있다.

ssc.stop()은 원래는 없었지만, 현재 메모리가 부족해서 설정해준거라서 넘겨서 보면된다.
※ 오류가 또 등장했다...
마지막이 내용이 없이 진행되어서 당황스러웠다.

1) ps -ef | grep smartcar로 실행중인 것들을 찾았을때 지금 검색한 grep만 하고 있는걸로 보아서 java파일이 실행되지않음을 확인해서 찾아보았다.
2) 위에 명령들을 확인해서 찾아보니 java실행에서 &을 쓰지않았던것을 찾았다. 사소한 것들도 잘 확인해야겠다는 교훈을 얻었다.
이렇게 흘러가나했더니 중간에 또 오류가 처음부터 나서 당황했는데 Zeppelin과 Spark도 다시 실행해보았더니 진행되었다. 중간에 멈출수도 있으니 확인하는게 중요하다.
2-3-6) 결과
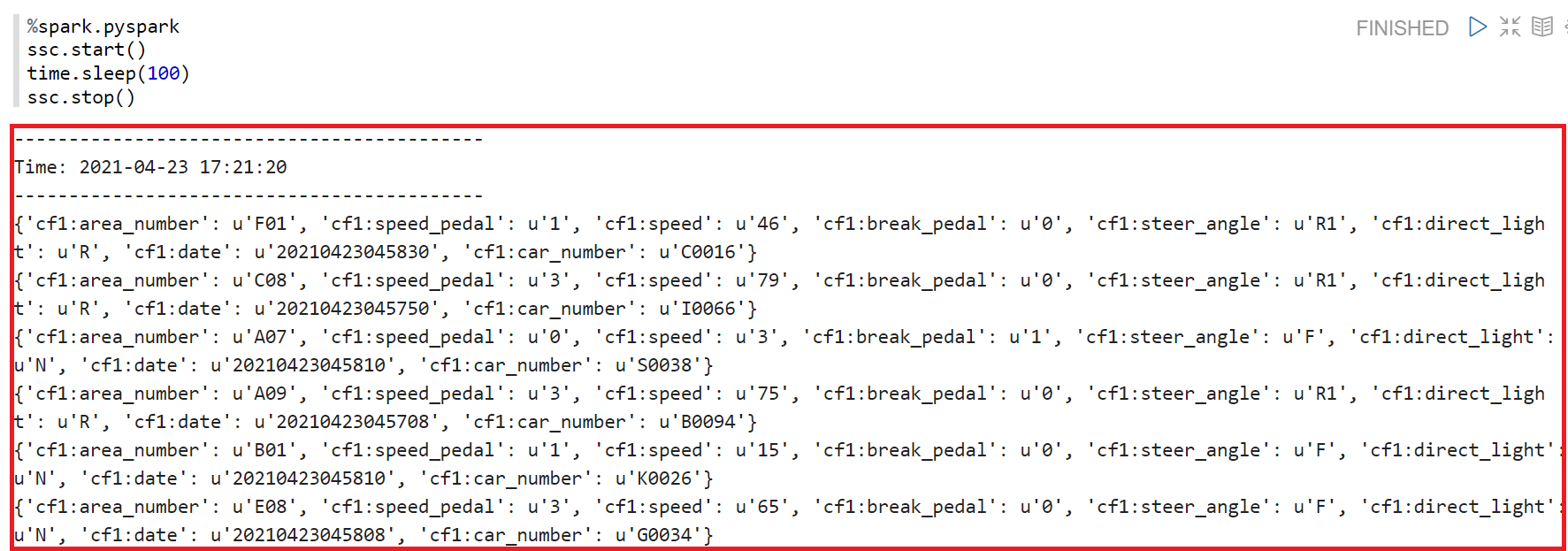
결과값이 이렇게 나와야 맞게 진행되는 것이다.
2-3-7) 삭제
위에 있는 3-7) 운행 정보 생성 지우기와 같이 진행하면 된다.

이렇게 하면 Kafka 데이터 Hbase 저장, 조회, 삭제까지 완료되었다.
'PBL 빅데이터 > 빅데이터 플랫폼' 카테고리의 다른 글
| [수업] 빅데이터 플랫폼5 (0) | 2021.04.26 |
|---|---|
| [수업] 빅데이터 플랫폼3 (0) | 2021.04.22 |
| [수업] 빅데이터 플랫폼2 (0) | 2021.04.21 |
| [수업] 빅데이터 플랫폼1 (0) | 2021.04.20 |



