1-9) 이미지 MongoDB 저장
1-9-1) MongoDB 시작하기

먼저 첫번째 프롬포트에 경로를 설정하고 dbpath를 진행해준다. 저번과 같이 계속해서 돌아간다면 진행되고 있는 것이다.

진행중인 프롬포트를 끄면 종료되니 계속해서 진행되게 냅두고 새로운 프롬포트에 들어가서 Mongo Shell을 실행시켜준다.
1-9-2) 등록된 이미지 삭제하기

fs.file : 업로드한 파일 정보(파일명, 사이즈, 업로드일시, 등)
fs.chunk : 업로드한 파일 내용(256kb씩 나눠서 저장)use를 통해서 삭제한 파일이 있는 DataBase에 들어간다. 조회할 때, 사용했던 db.fs.files와 db.fs.chunk뒤에 remove({})을 사용해서 전체를 지운다. {}안에 조건이 업다면 모두 삭제된다.
1-9-3) url 받아오기

저번에 만든 고양이 링크 리스트를 MongoDB에 저장하기 위해서 link1이라는 변수에 넣어준다.
1-9-4) url 받아오기

많은 데이터를 처리하기전에 먼저 하나의 데이터를 통해서 알아본다. link1에서 인덱스를 이용해서 링크를 받아와보고 이 링크를 변수에 저장해준다.
1-9-5) 이미지 내용 불러오기

urllib을 이용해서 url의 접속하고 이미지 내용을 가져오고 이미지 내용이 잘 불러와져있는지 확인한다.
1-9-6) 이미지 내용 확인하기

이미지를 처리하는 라이브러리들을 import해서 들어온 이미지 내용을 이미지로 출력해서 확인한다.
1-9-7) 파일 확장자 알아내기
1-9-7-1) 파일 이름 찾기

파일 확장자는 파일의 이름의 뒤에 위치하고 있다. 그렇기에 먼저 파일의 확장자를 찾기위해서는 파일의 이름을 찾아내야한다. 파일의 이름을 나눠주기위해서 split('/')을 통해 /으로 url을 분리해서 마지막에 위치한 이름을 알아낼 수 있다.
이름이 없고 ?로 되어있을 경우에는, find()는 문자열을 찾아서 인덱스를 리턴해주는데 위의 예시와 같이 찾고자하는 문자열을 찾은 후 그 인덱스를 리턴해준다.

하지만, 찾고자하는 문자열이 없는 경우도 발생한다. 그럴 때는 -1을 리턴해준다. 이러한 find의 성질을 이용해서

조건문을 사용해서 ?가 존재할 때에는 split을 하고 그 안에 존재하고있는 이름을 찾겠다라고 지정할 수 있다.
1-9-7-2) 확장자 찾기

파일의 이름을 확인해보니 확장자는 파일의 맨 뒤에 위치하고있다. .(점)이 확장자 앞에 있으니 .(점)을 사용해서 split할 수 있음을 알 수 있다. split을 한 뒤, 맨 뒤에 있는 확장자를 [-1]로 인덱싱해주면 확장자를 얻을 수 있다.
1-9-8) MongoDB 저장하기

저장할 MongoDB를 import하고 저장할 Database를 지정해준다. GridFS를 통해서 파일을 저장할 객체를 생성한다.

저장할 이미지의 정보가 많아서 Bucket을 사용해서 Bucket안에 넣어서 저장해준다.
Bucket = 이미지 파일명, contentType{image/jpg, cat} 이런식으로 내용이 담겨진다. 파일을 다 저장했다면 잊지말고 MongoDB를 닫아주어야한다.
1-10) 고양이와 강아지 이미지 MongoDB에 저장하기
1-10-1) 고양이 저장하기

위에서 했던 것들을 되짚어서 본다면 어떤 구조인지 알 수 있다.
1) 고양이 이미지 링크(link1)를 지정해서 for문으로 넣기
2) 이미지 이름을 지정하기(split('/') 혹은 split('?) 사용) - 1-9-7-1) 파일 이름 찾기 참고
3) 이미지 확장자 지정하기(기본값 혹은 split('.) 사용) - 1-9-7-2) 확장자 찾기 참고
4) Bucket에 넣어서 저장하기('type':'cat) - 1-9-8) MongoDB 저장하기 참고
5) 이미지 저장 종료 알려주기
6) try, except를 사용하기(가끔 불러왔던 링크가 삭제되어 사라지는 경우도 발생한다.)
1-10-2) 강아지 저장하기

먼저, 고양이처럼 강아지의 링크들을 link2라는 변수에 지정해준다.

1) 강아지 이미지 링크(link2)를 지정해서 for문으로 넣기
2) 이미지 이름을 지정하기(split('/') 혹은 split('?) 사용) - 1-9-7-1) 파일 이름 찾기 참고
3) 이미지 확장자 지정하기(기본값 혹은 split('.) 사용) - 1-9-7-2) 확장자 찾기 참고
4) Bucket에 넣어서 저장하기('type':'dog) - 1-9-8) MongoDB 저장하기 참고
5) 이미지 저장 종료 알려주기
6) try, except를 사용하기(가끔 불러왔던 링크가 삭제되어 사라지는 경우도 발생한다.)
1-10-3) 확인하기

db.fs.files.find({'metadata.type' : 'cat'}) 를 이용해서 type이 cat이면 조회한다.

db.fs.files.find({'metadata.type' : 'dog'}) 를 사용해서 type이 dog이면 조회한다.

db.fs.files.find({'metadata.type' : 'dog'}).count()를 사용해서 맞는 정보의 데이터를 확인할 수도 있다.
db.fs.files.find({'metadata.contentType' : 'image/png'}).count() : contentType이 png인 것만 갯수 세기
db.fs.files.find({'metadata.contentType' : {$regex:'image'}}).count() : $regex는 포함문으로 image가 포함된 것을 세기
db.fs.files.find({'metadata.contentType' : {$regex:'jpeg'}}).count() : jpeg인 파일을 세기
db.fs.files.find({'metadata.contentType' : {$regex:'video'}}).count() : 비디오인 파일을 세기1-11) MongoDB에 저장된 이미지를 머신러닝해보기
1-11-1) 저장한 파일을 설정
1-11-1-1) 저장한 파일들을 조회하기

그냥 실행하면 객체가 안보이기때문에 list안에 넣어서 진행해주어야한다.
1-11-1-2) 이미지 불러오기

머신러닝에 돌리기위해서는 이미지의 크기가 동일해야지 가능하다. 하지만 현재는 각각 다른 크기를 가지고 있음을 확인할 수 있다. 전체를 변환하기전에 먼저 크기가 큰 이미지를 통해서 알아본다. 크기가 큰 이미지를 선택해준다. detail를 통해서 딕셔너리로 이루어져있음을 알 수 있다.

위에 사용했던 것과 같이 내용들을 가져온다.

이미지 내용을 받았으니, 출력을 해준다.

이미지 처리를 import해서 이미지를 출력해서 이미지를 확인할 수 있다.
1-11-1-3) 흑백처리하고 사이즈 조절하기

컬러로 된 사진을 사용하면 복잡해지므로, 먼저 흑백으로 변경해서 사용해본다. 흑백으로 변경을 위해서 사진에 conver('L')을 사용하면 된다.

머신러닝에서 사용하기 위해서는 사이즈가 동일해야하니, resize를 통해서 사이즈를 변경해주어야한다. 지금은 200,200으로 진행해보려고한다. 이미지 크기가 작아진 것을 확인할 수 있다.
1-11-2) 머신러닝에 사용해보기
1-11-2-1) 이미지를 숫자로 변경하기

현재 우리가 볼 수 있는건 im의 이미지이다. 머신러닝을 돌리기위해서는 숫자로 변경해주어야한다. 숫자로 변경하기 위해서 numpy를 사용한다. numpy를 이용해서 변경하면, 0 ~ 255사이의 숫자들이 나오는데 이것은 색을 나타낸다.
흰색: 0
회색: 0 < 회색 < 255
검정: 255
흑백임으로 저 사이의 숫자들로 이루어져있다. 머신러닝은 정수들로도 사용할 수 있지만, 0 ~ 1사이에 실수로 변환해주면 더 정확해진다. 그렇기에 0 ~ 1사이의 실수로 변환해주기위해서 255을 나눈다. 255를 나누는 이유는 최소 숫자인 0을 255로 나누면 0이 나오고 최고 숫자인 255를 255로 나누면 1이 나오므로 그 안의 숫자들은 0 ~ 1사이의 실수가 되기 댸문이다. 이제 머신러닝이 좋아하는 숫자로 변경 되었다.
1-11-2-2) 배열 변경하기

shape를 통해서 현재 몇칸과 몇줄로 이루어져있는지 확인할 수 있다.

Support Vector Machine 알고리즘(SVM)을 사용할 예정이다. 알고리즘마다 필요한 칸과 줄의 수가 다른데 SVM은 무조건 한 줄이어야한다. 그렇기에 먼저 한줄로 변경해주어야한다. 현재 im은 shape를 통해서 알아봤지만, 200줄 200칸으로 이루어져있다. 변경하는 방법은 flatten()을 사용하면 된다.
flatten()을 사용해서 한 줄로 변경할 수 있다. 200줄 200칸을 변경한 것으로 한 줄에 40000칸이 들어있다.
타입을 확인해보면 머신러닝은 float타입으로 이루어져있으면 더 정확한 값을 얻을 수 있다. 물론 현재 상태에서도 머신러닝에 돌리는 것도 가능하지만, 정확한 값을 위해서 double로 이루어진 im을 astype으로 변경해준다.
1-11-3) 전체 데이터로 머신러닝해보기
1-11-3-1) 저장된 이미지들을 불러오기

1-11-3-2) 저장한 파일들을 조회하기 참고
python_test Database에 들어있는 이미지들을 불러와서 image_list에 넣어준다.
1-11-3-3) 변경값과 리스트 생성

가로와 세로의 길이를 변경해주어야하기에 먼저 변경값을 지정해준다. 리스트를 생성해주는데 이는 이미지들을 읽어서 저장할 리스트 1개, 고양이면 1, 강아지면 0을 저장할 리스트 1개를 만들어준다.
1-11-3-4) 머신러닝을 위해 설정해주기

1) 파일명을 조회하고 일치하는 마지막 버전의 파일의 내용을 가져와서 data에 저장 - 1-11-1-1) 저장한 파일들을 조회하기 참고
2) 내용이 들어있다면 if문을 써주고 이미지로 변환해서 머신러닝을 사용하기 위해서 값들을 처리해주기 - 1-11-1-2) 이미지 불러오기, 1-11-1-3) 흑백처리하고 사이즈 조절하기, 1-11-2-1) 이미지를 숫자로 변경하기 참고
3) 변경한 이미지들을 위에 생성한 리스트안에 넣어주기
4) label은 이미지를 저장하면서 지정한 ['type':'cat']에서 cat이 맞다면 1을, 아니면 0을 반환하는데 현재는 고양이랑 강아지 이미지뿐이니 0은 강아지가 된다.
5) label을 labels 리스트안에 넣어주기

1-11-3-5) 리스트들을 배열로 변경하기
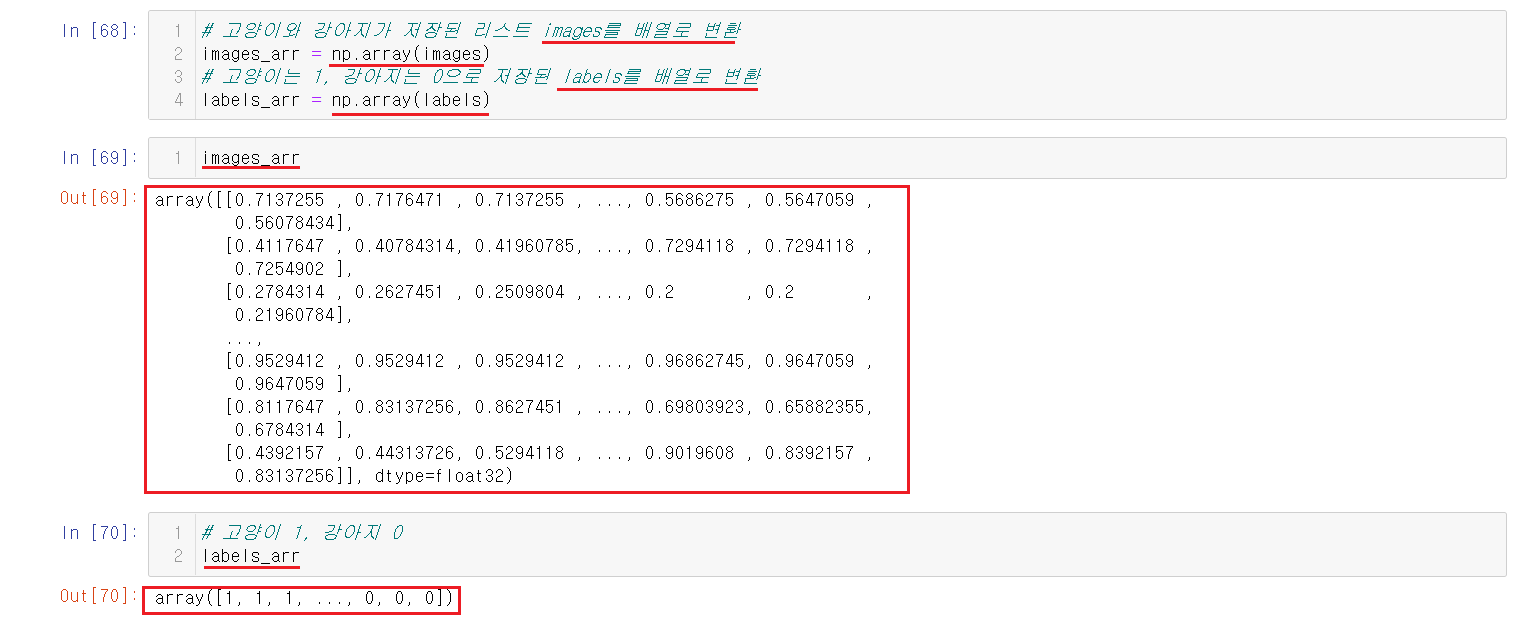
넣어준 리스트들을 머신러닝에 사용하기위해서 배열로 변경해준다.
1-11-3-5) train, test 데이터 나눠주기

확인하기위해서 train데이터와 test데이터로 이미지를 배열로 가지고있는 images_arr와 label을 배열로 가지고있는 labels_arr를 75%, 25%로 나누어서 사용한다.



1-11-4) SVM(Support Vector Machine)을 이용한 학습
1-11-4-1) SVM 개념
- 머신러닝으로 하는 일 : 회귀(값 예측) ex) 내일 삼성전자 주식 가격 예측
분류(그룹) ex) 내일 삼성전자 주식이 오른 주식 그룹, 내린 주식 그룹에 속하는지
- SVM은 둘 다 가능하지만, 분류가 좀 더 정확하다.
- 집단을 나누는 선을 찾는게 학습이다.
*선을 나누기
- Classification이 최우선으로 잘못 분류된게 없는게 먼저이다.
1) 잘못 분류된 것(오분류)이 적은 것
2) 잘못 분류한게 같다면 더 많이씩 분류할 수 있는걸 선택
- 잘못 분류된 것이 없다면 Marign : 각 각의 그룹에서 가장 먼 선으로 설정한다.
1-11-4-2) 2개 예측해보기

SVM = svm.SVC().fit(X_train, y_train)X_train에서 y_train이 0인 애들, X_train에 y_train이 1인 애들을 나누는 초평면을 만든다. 현재 차원이 40000차원으로 시간이 좀 걸린다.
초평면을 통해서 예측이 가능한데 먼저 text데이터에서 2개만 뽑아서 확인을 해본다.
SVM.predict(X_test[0:2]) -> 예측값
y_test[0:2] -> 진짜값서로 비교해보니 값이 1개만 맞고 다름을 확인할 수 있다. 예측이 되는 것을 확인했으니 전체 데이터를 넣어서 확인해본다.
1-11-4-3) 전체 예측해보기

SVM.predict(X_test)를 사용해서 모든 전체의 X_test값을 예측한다. 예측값은 위에서 생성한 초평면을 기반으로 나눠지기에 다시한다고 값이 변하지는 않는다.
1-11-4-4) 진짜값을 확인하기

y_test안에 들어있는 진짜값을 y_test를 호출해서 확인할 수 있다.
1-11-4-5) 값을 비교하기
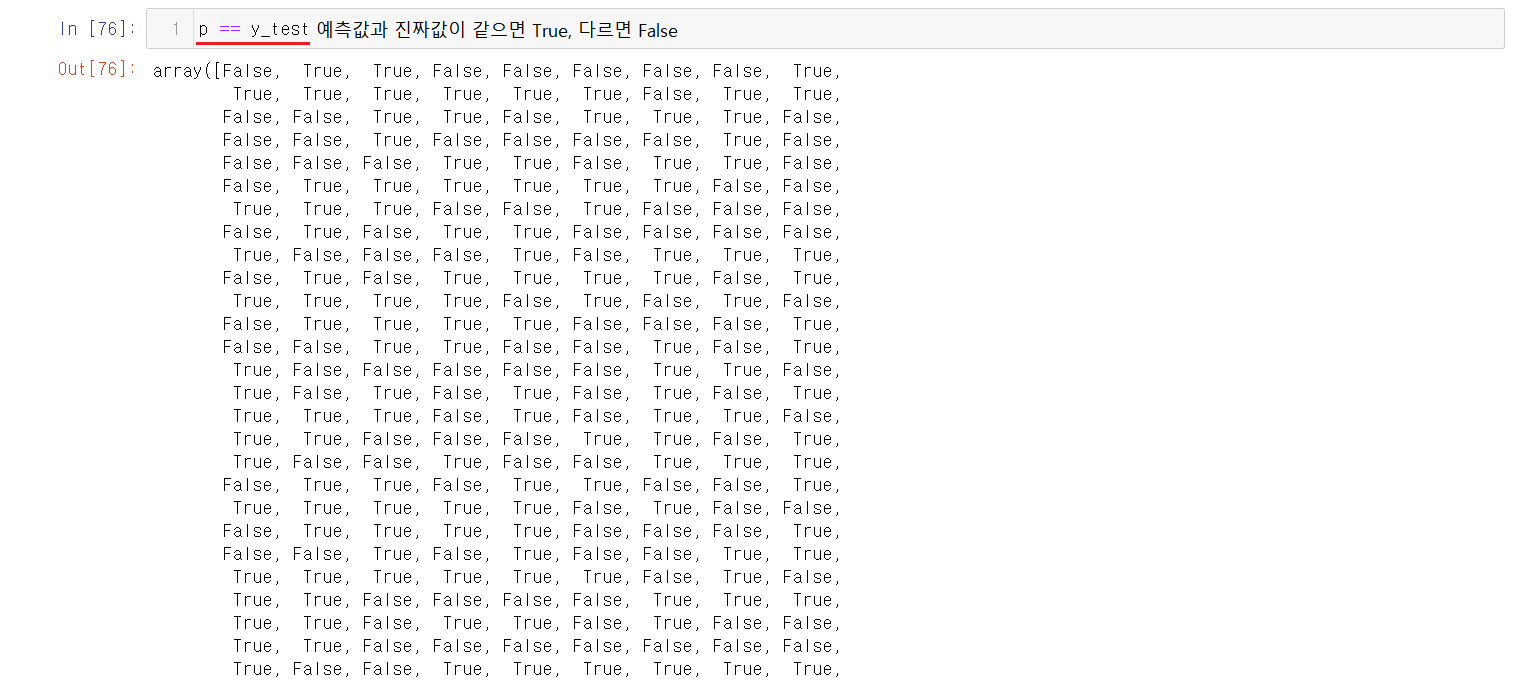
p == y_test를 사용하면 예측값과 진짜값을 비교하며, 값이 같으면 True를 다르면 False를 반환해준다.
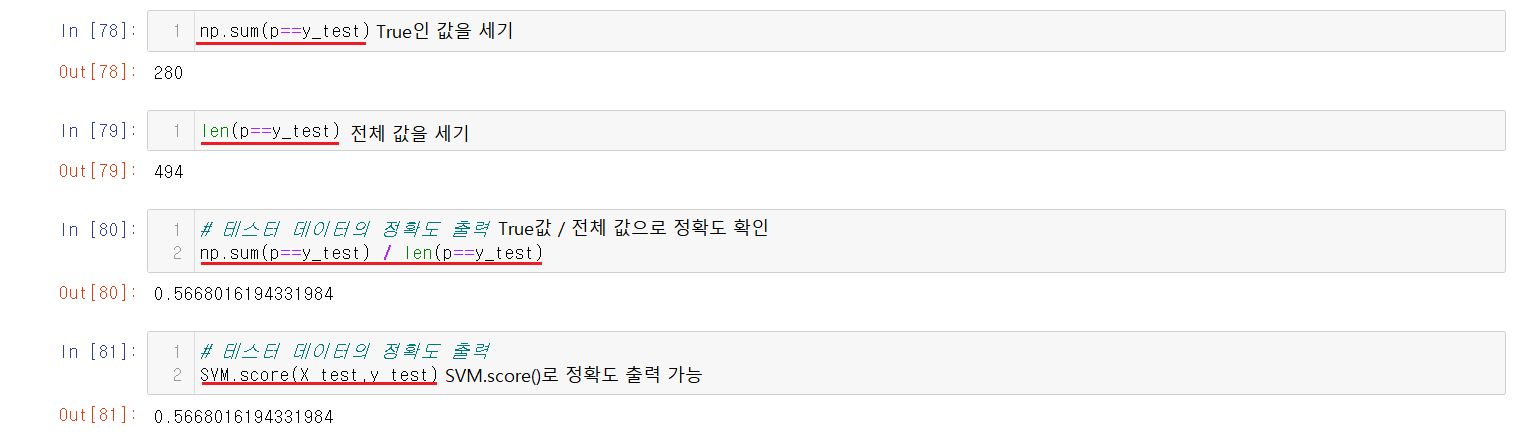
반환된 값에서 True인 값만을 받아서 전체 값과 나누어주면 정확도를 구할 수 있다.
1) np.sum(p == y_test) / len(p == y_test)
2) SVM.score(X_test,y_test)혹은 SVM.score(X_test,y_test)을 사용해서도 구할 수 있다. 정확도는 약 57%이다.
1-11-5) 새로운 이미지로 예측하기
1-11-5-1) 새로운 이미지 설정하기

새로운 이미지를 불러오고 위에서 했던 SVM을 실행시키기위해 설정했던 것을 그대로 실행해준다. 실행 후, 배열로 변경하고 그 배열을 predict에 넣어서 예측을 해보니 값이 1(고양이)가 나왔다.
1-11-5-2) 새로운 이미지 예측값을 그래프로 그리기

예측된 값을 넣어서 그래프에 고양이, 강아지로 표현시키는 그래프를 그리고 그림도 출력시킨다.

결과를 확인해보면 강아지 사진을 cat으로 분류했음을 알 수 있다. 위에서 확인했듯이 현재 정확도는 57%이기에 타당한 결과이다.
'PBL 빅데이터 > 빅데이터 저장' 카테고리의 다른 글
| [수업] 빅데이터 저장1 (3) | 2021.05.03 |
|---|
