1) NOSQL의 특징
1-1) NOSQL의 특징
1-1-1) 데이터 종류
1) Small Data
- Excel 파일 1개에 저장 가능한 데이터
2) Very Large Data
- Computer 1대에 저장이 가능한 데이터
- 관계형 DB에 저장(MySQL, Oracle)
- 숫자나 문자 데이터
3) Big Data
- Computer 1대에 저장이 불가한 데이터
- 주로 비정형 데이터
1-1-2) Key/Value Store
- 대부분의 NoSQL은 Key/Value 개념을 지원한다.
- Datark Data가 여러컴퓨터에 나눠서 저장되어있으며, 빠른 검색이 중요하기에 key와 value의 형태를 가지고 있다.
- put(key,value), value := get(key) 형태 API 사용
----------------------- ---------
저장 조회
1-1-3) Ordered Key/Value Store
- 데이터가 내부적으로 Key를 순서로 정렬되어 저장된다.
- Key(P.K) 안에 (column:value) 조합으로 된 여러개의 필드를 가지는 구조이다.
- ex) Hbase, Cassandra -> NoSQL에서 Hbase를 주로 사용한다(숫자, 문자 가능)
1-1-4) Document Key/Value Store
- Key/Value Store의 확장된 형태이다.
- 복잡한 계층구조 표현이 가능하다.
- JSON,XML,YAML등을 사용한다.
1-1-5) MongoDB 특징
- Key-value와 다르게 여러 용도로 사용이 가능하며, 범용적이다.(정형데이터(숫자, 문자), 비정형데이터(이미지, 동영상)도 저장 가능)
- 스키마를 고정하지 않는 형태로 table의 컬럼이 가변적이다.
- 데이터를 구조화해서 json형태로 저정한다.
- MongoDB는 총 4개의 운영체제(Window, Mac, Linux, Linix)를 지원한다.
1-2) MongoDB 설치
MongoDB 공식 사이트(www.mongodb.com/download-center/community)에서 설치
1-2-1) 다운로드받은 압축 파일을 c:\bigdata 폴더에 압축해제하고 폴더명을 mogodb로 수정
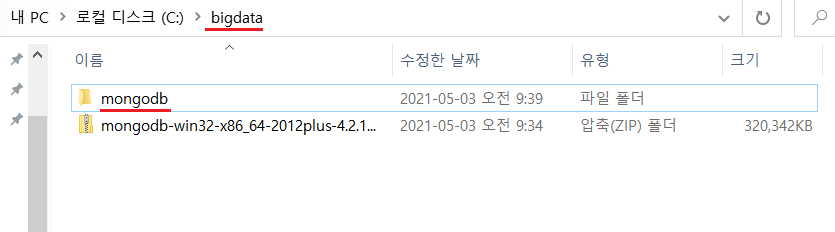
1-3) MongoDB 실행
1-3-1) MongoDB 데이터 저장 폴더 생성
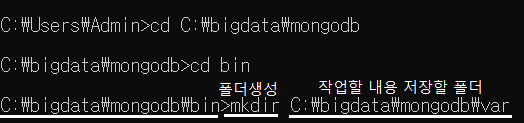
1-3-2) 작업 내용 저장할 폴더 지정

MongoDB실행 후 작업 내용들을 저장할 폴더를 지정해준다.

저런 화면에서 계속해서 뭐가 진행되고 안넘어간다면 재대로 진행되고 있는 것이다.
1-3-3) MongoDB Shell실행
진행되는 창을 냅두고 새로운 명령 프롬포트창을 띄운다.

파일 경로로 들어가서 mongo를 입력하면 MongoDB Shell이 실행된다.
1-4) MongoDB를 이용해서 텍스트 파일 저장하기
1-4-1) 텍스트 파일 만들기
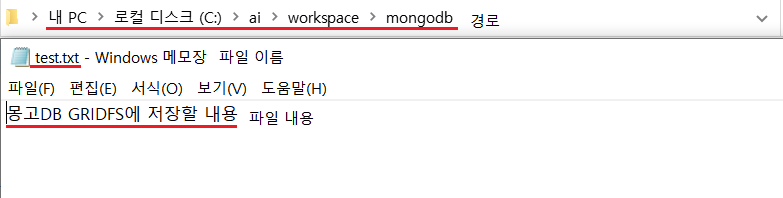
먼저 저장해 줄 텍스트를 만들어준다. 경로는 위에 설정된 경로로 없다면 폴더를 생성해서 설정해준다. test.txt라는 이름의 텍스트 파일을 경로에 맞게 저장해준다.
1-4-2) MongoDB에 파일 저장해주기

새로운 명령 프롬포트를 열어서 진행해준다.
1-4-3) 저장된 데이터를 확인하기

저장된 데이터는 현재 3개의 명령 프롬포트가 진행중인데 그중에 mongo shell을 진행한 곳을 열어서 진행한다.
show collections는 mongodb에 저장된 테이블 리스트 조회한다.
db.fs.files.find()는 mongodb에 저장된 파일의 정보를 조회한다.
db.fs.chunks.find()는 mongodb에 저장된 파일의 내용을 조회한다.
1-5) 파이썬을 이용해서 텍스트 파일 저장하기
1-5-1) 아나콘다 프롬포트에서 라이브러리 설치
아나콘다 프롬포트에 들어가서 라이브러리를 설치해주는데 우리가 DB를 생성한 C:\ai\workspace\mongodb로 들어가서 pip install pymongo 를 사용해서 설치해준다.
1-5-2) MongoDB에 접속하기
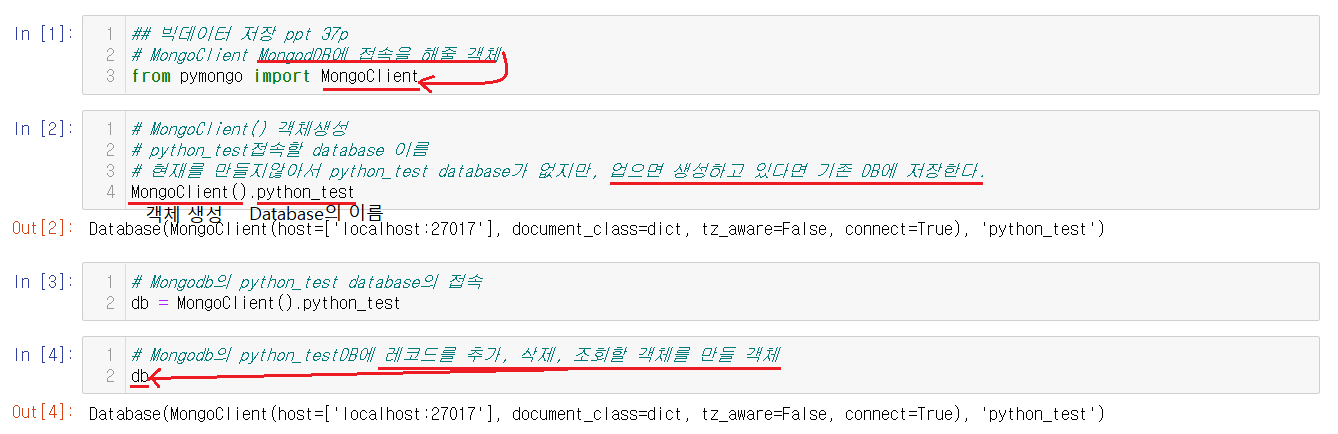
from pymongo import MongoClient 을 통해서 MongoDB에 접속을 해줄 객체를 import해준다.
MongoClient().python_test에서 MongoClient() 객체를 생성하고 python_test접속할 database 이름을 뜻한다. 이 때, python_test database가 업으면 생성하고 있다면 기존 DB에 저장한다. 변수를 설정해줘야 레코드를 추가, 삭제, 조회할 수 있음으로 변수를 db로 설정해준다.
1-5-3) MongoDB에 파일을 저장할 객체 생성

MongoDB에 파일을 저장할 객체를 생성해주는데 import만 한다고 되는 것이 아니라 객체를 지정해주어야하므로 변수에 넣어준다.
1-5-4) text파일 불러오기

with open('c:/ai/workspace/mongodb/test.txt', 'rb') as f:
를 통해서 읽어온다.
with open('읽을 파일 경로', 'rd(r: read, b: 한글을 숫자로 변환)') 식으로 사용해주면 된다. 읽어온 결과를 확인해보니 영어는 영어로 재대로 나오지만 한글은 숫자로 나오는걸 확인할 수 있다. 이는 with에서 rd에서 'd'는 한글을 숫자로 변환하는 역할을 하기 떄문이다.
1-5-5) 파일 저장하기

fs는 위의 지정했듯이 MongoDB에 파일을 저장할 객체이다. 이를 통해서 text파일을 저장한다. 저장은 put을 이용해서 가능하다. 순서도로 보면
1) f s.put -> f.read의 파일 내용을 가져와서 Mongodb에 저장한다.
2) 파일 이름 설정한다.
1-5-6) 파일 확인하기

현재는 객체가 안보이는데 객체를 확인하려면 list안에 넣으면 확인할 수 있다.

Mongo Shell에서도 확인이 가능하다.

MongoDB를 이용해서 저장한 파일 1개, 파이썬을 이용해서 저장한 파일 1개를 확인할 수 있다.
1-5-7) 파일 출력하기
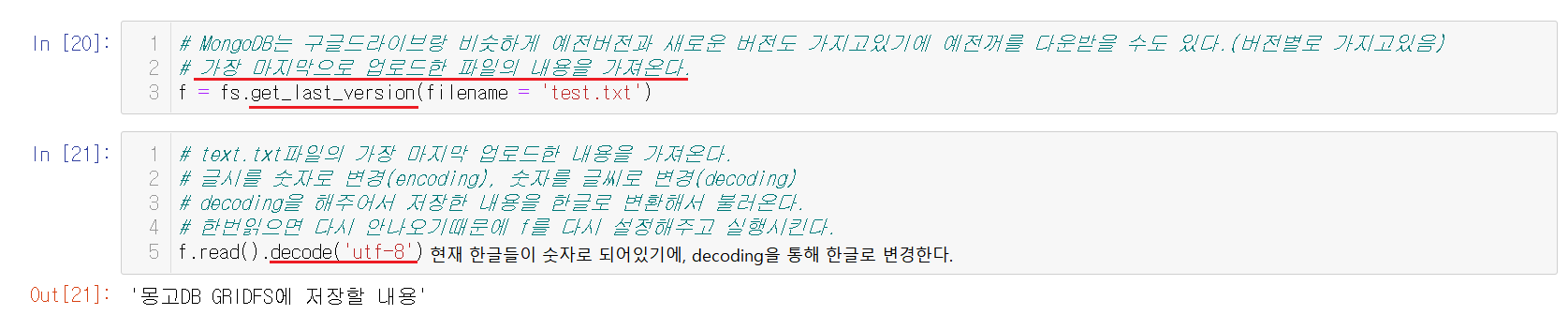
맨 처음에 파일을 불러올 때, 'rd'를 사용해서 한글을 숫자화했다. 파일이 재대로 올라갔는지 확인하기 위해서 decoding으로 숫자들을 다시 한글로 변경해서 출력해준다.
1-6) 이미지를 MongoDB에 저장하기
1-6-1) MongoDB - python_test Database의 접속하기

import를 통해서 MongoDB에 접속할 객체를 생성하고 그 안에 python_test Database의 접속한다.
1-6-2) 이미지 내용 불러오기
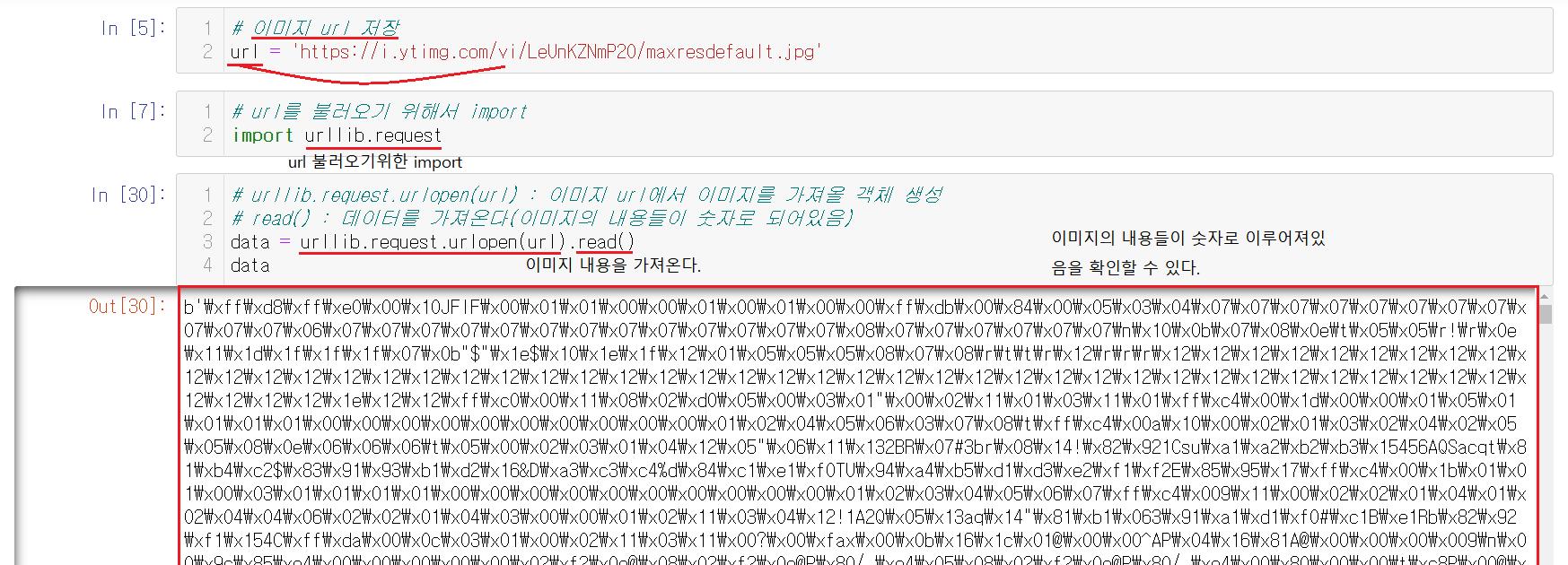
url변수에 이미지 url를 넣어준다. url을 불러오기위해서 저번에 사용했던 urllib.request를 import해준다.
urllib.request.urlopen(url)로 이미지 url에서 이미지 내용을 가져올 객체를 만들고 그 객체를 read()를 통해서 읽어준다. 읽어준 결과를 확인해보면 현재 이미지의 내용들이 숫자로 이루어져있음을 확인할 수 있다.
1-6-3) 이미지 라이브러리 불러오기
! pip install image
! pip install pillow
from io import BytesIO
from PIL import Image이미지를 불러오고 처리하기위해서 필요한 라이브러리들을 설치해준다.
1-6-4) 이미지 불러오기

Image.open(BytesIO(data)) 를 사용하는데 현재 data안에는 이미지 내용이 들어있다. 이 내용을 BytesIO를 통해서 읽어올 객체를 생성하는 것이다.
1-6-5) MongoDB로 파일을 업로드할 객체 생성
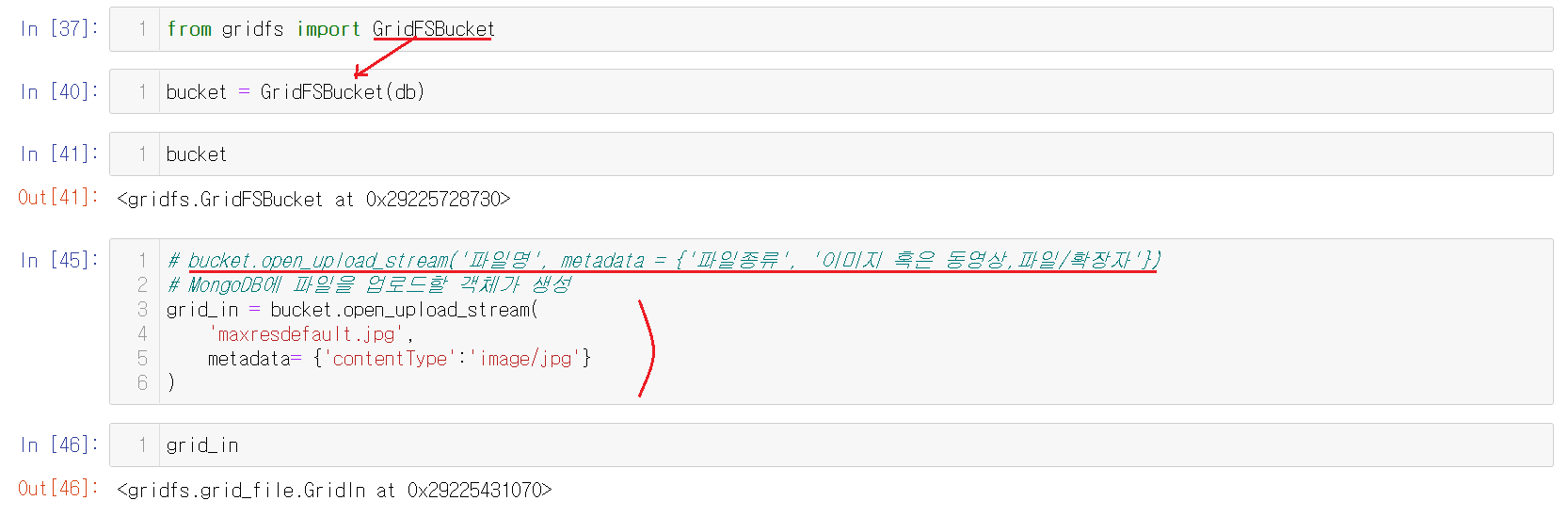
업로드할 객체를 생성해주는데 이 객체의 내용은
bucket.open_upload_stream('파일명', metadata = {'파일종류', '이미지 혹은 동영상,파일/확장자'})으로 구분되어있다. 확장자 파일은 다 다르니 이미지에 혹은 파일에 맞는 확장자를 적어주어야한다.
1-6-6) 파일 업로드하기

업로드할 객체를 write를 사용해서 MongoDB로 업로드해주었다. 작업이 끝이 났다면 항상 끝이 났다고 지정해주어야한다. 끝났다는걸 지정할 때는 close()를 사용해준다.
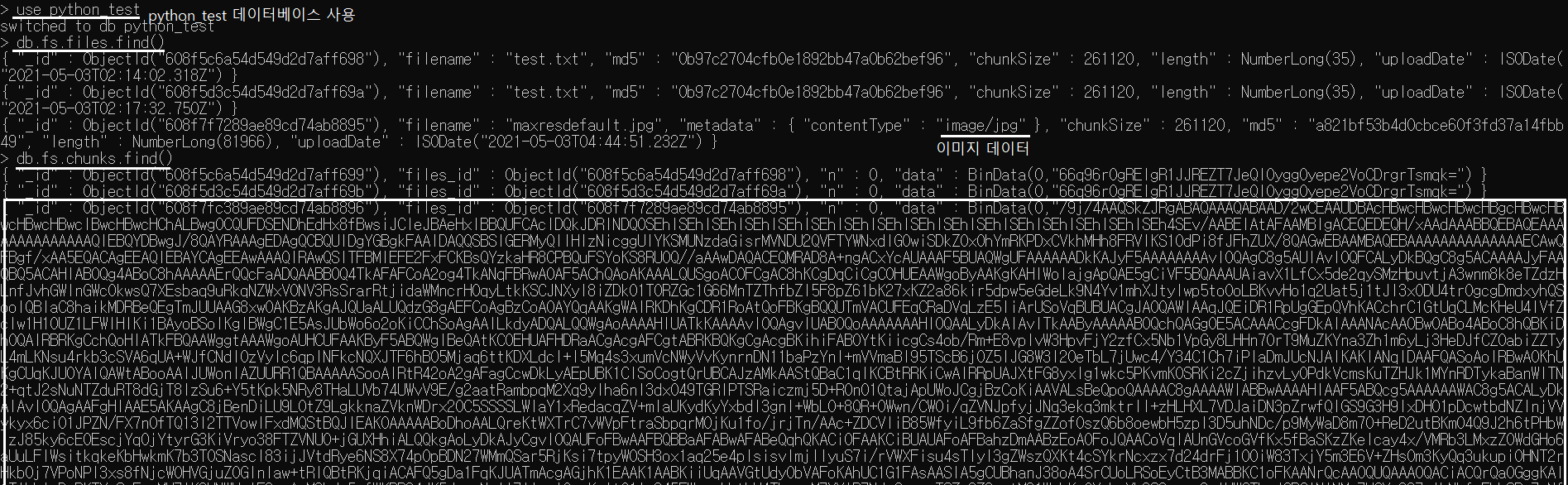
use python_test
db.fs.files.find()
db.fs.chunks.find()Mongo Shell을 통해서 업로드가 되었는지 확인이 가능하다. 현재 DB에는 총 3개가 있지만, 위에서부터 따라했다면 현재 이미지파일까지 2개가 생성되어있는것이 맞다.
1-7) Python 이용해서 MongoDB에 저장한 이미지 불러오기
1-7-1) 라이브러리 불러오기
MongoDB에서 이미지를 불러오기 때문에, 이미지 처리와 Mongo 관련한 라이브러리들을 불러온다.
1-7-2) 이미지 파일 확인하기
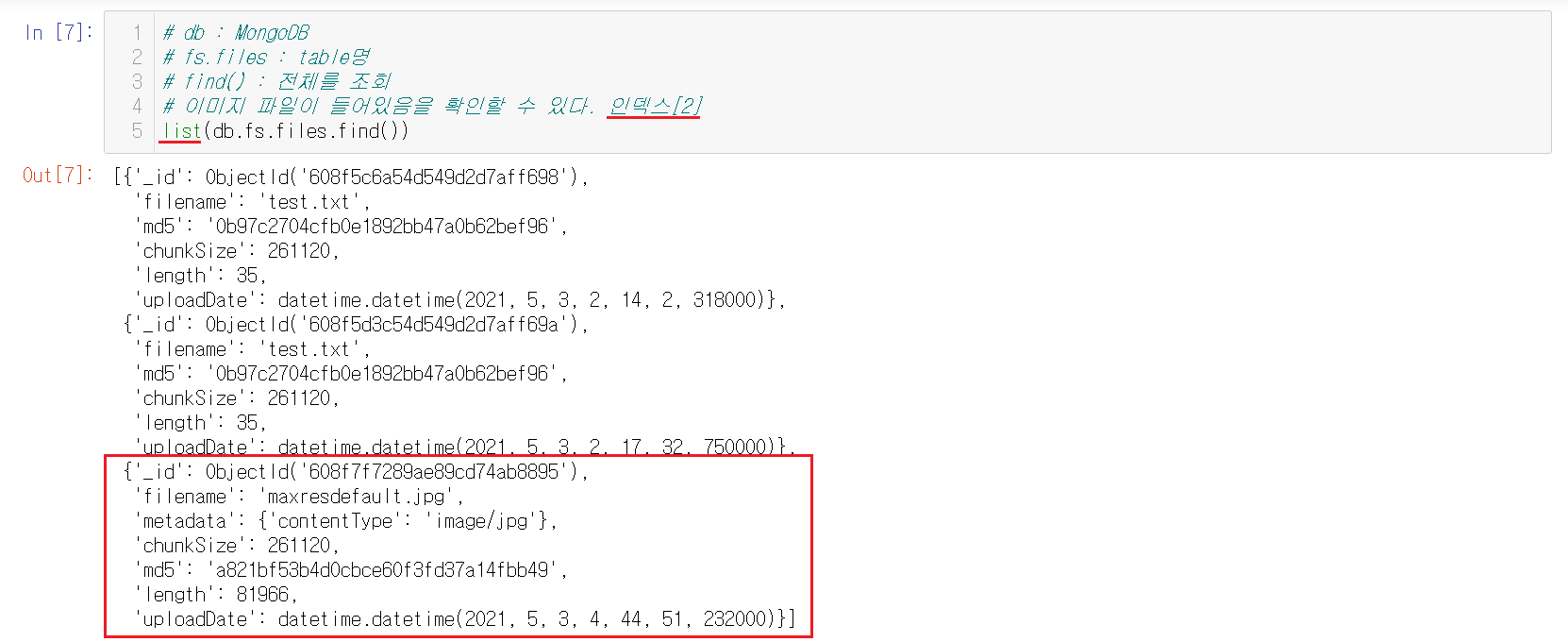
이미지 파일을 확인해보는데 객체를 그냥 실행하면 보이지않기때문에 list()에 넣어서 실행해야 확인할 수 있다. 확인을 해보니 인덱스[2]안에 저장한 이미지가 들어있다. 각 자의 인덱스가 다를 수 있기에, 본인이 저장한 이미지가 어디에 위치하는지 확인해야한다.
1-7-3) 이미지 파일만 조회하기

이미지 파일이 인덱스로 2번째 위치한다는걸 알았으니, 이미지 파일만 조회하기가 가능해진다. find()다음에 인덱스 번호를 줘서 이미지 파일만 조회했다. 뒤에 이미지파일안에 있는 'filename' 추가해서 파일명만 조회하기도 가능하는 것을 알 수 있다.
1-7-4) 파일의 내용 읽어오기
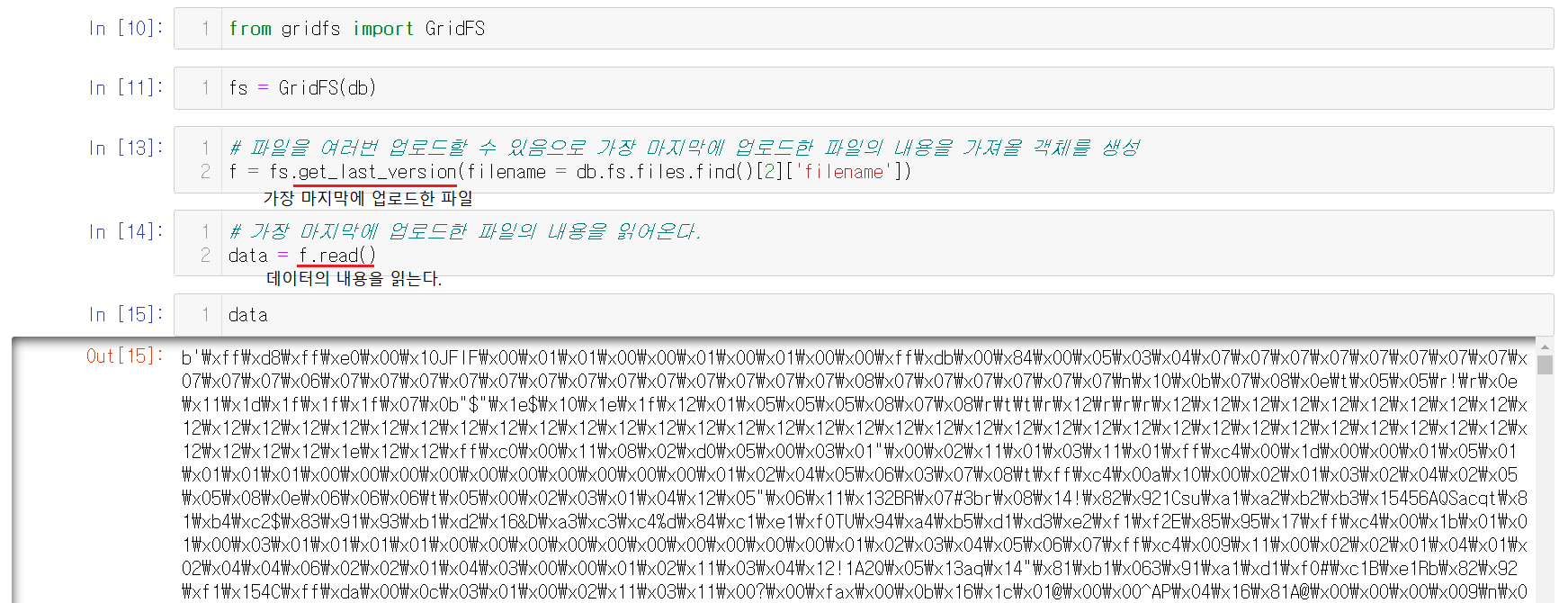
파일의 내용을 읽어오기전에 객체를 생성해준다. 객체를 생성 후, get_last_version을 사용하는데 이미지파일도 계속해서 업로드가 가능하기에 제일 마지막에 업로드된 파일을 가져온다. 현재 1개만 올렸으니 1개 올린 파일이 last_version파일이 된다. 이미지 내용은 저번과 같이 숫자로 되어있기에 이를 변환해주어서 출력해야한다.
1-7-5) 이미지 출력하기
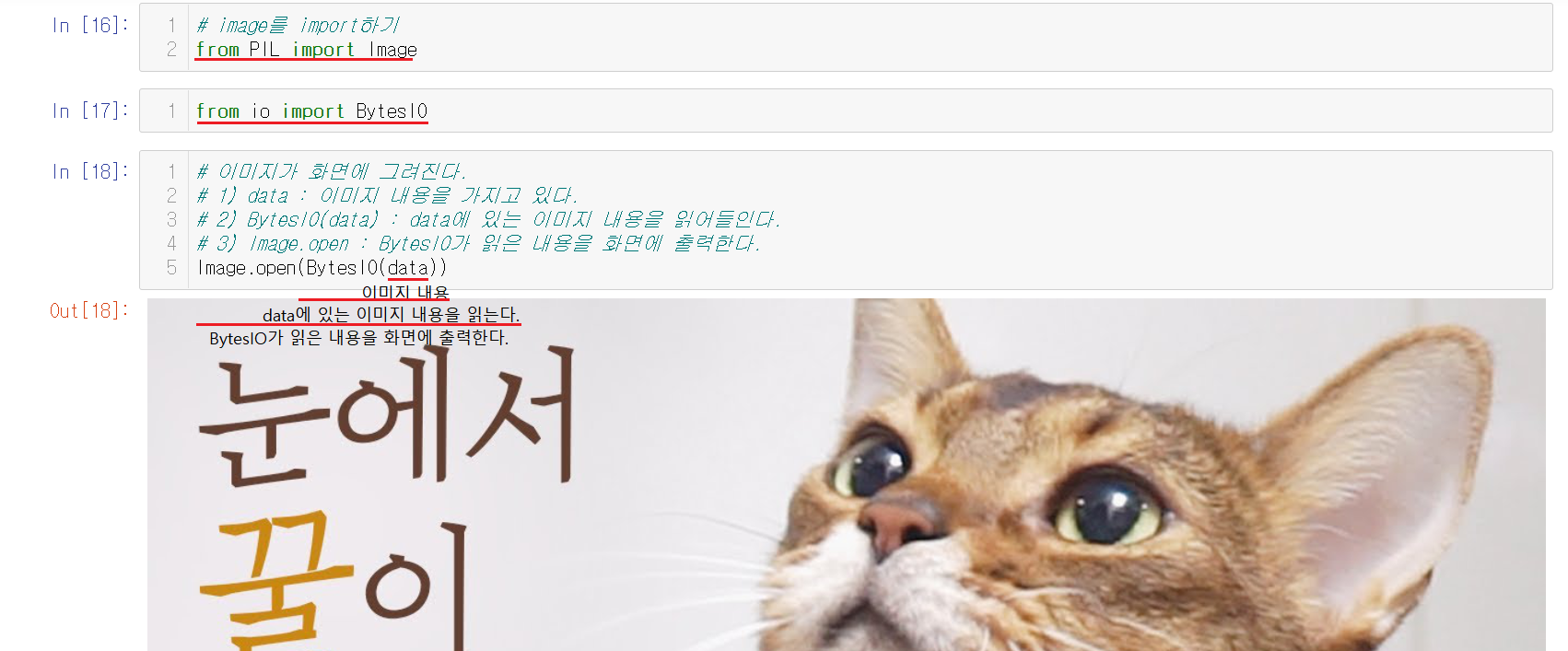
이미지 처리를 위해서 사용했던 라이브러리들을 불러온다.
1) data : 이미지 내용을 가지고 있다.
2) BytesIO(data) : data에 있는 이미지 내용을 읽어들인다.
3) image.open : BytesIO가 읽은 내용을 화면에 출력한다.
Image.open(BytesIO(data))를 통해서 이미지를 출력한다.
1-8) 네이버 API 이용해서 이미지 1000개 URL 검색
1-8-1) 네이버 API 들어가기
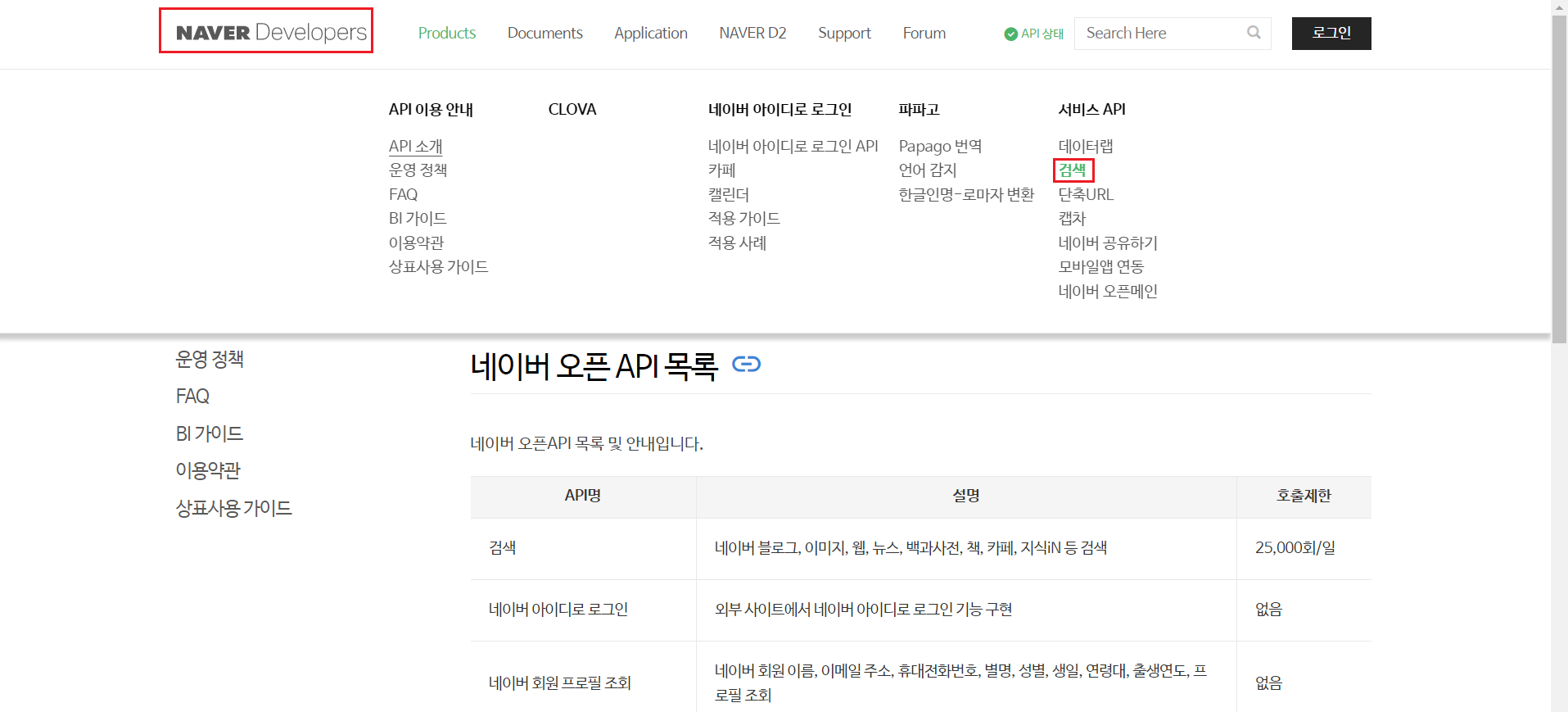
네이버api검색 -> 네이버개발사센터 -> product에서 검색을 들어간다.
1-8-2) 이미지 API 들어가기

개발 가이드를 들어가서 확인할 수 있다. 오픈 API를 이용하기 위해서는 ID와 Password가 필요한데 없다면 옆에 버튼인 오픈 API 이용 신청에 들어가서 신청할 수 있다.
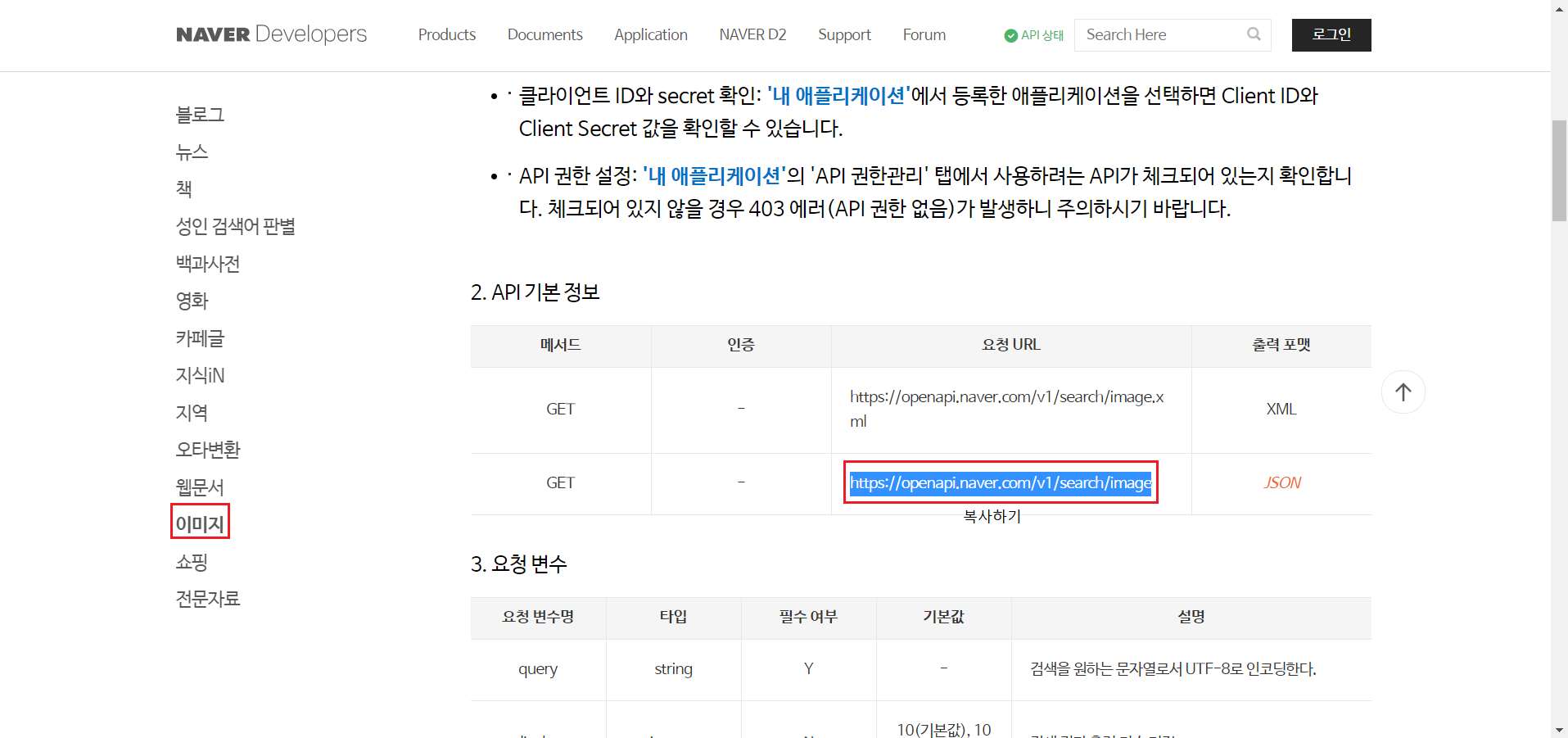
개발 가이드 보기 -> 이미지 -> API 기본 정보 -> JSON url을 복사해준다. 그전에 사용할 url에 대해서도 확인할 수 있다.
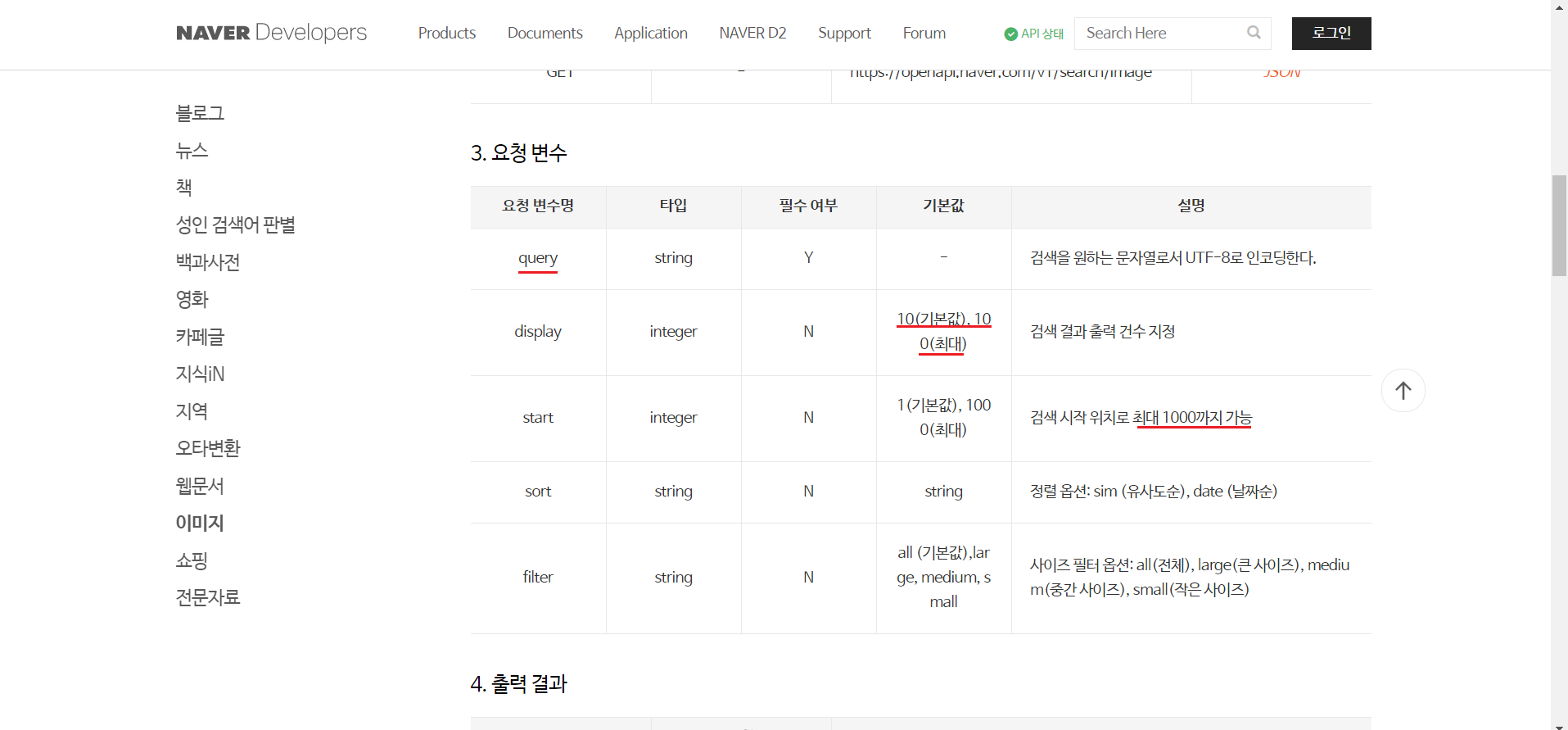
복사한 url밑에 요청변수라는 표가 있다. 요청변수를 확인해보니 검색할 때에 기본값은 10이고 최대는 100이라는 것을 확인할 수 있다.
1-8-3) 오픈 API URL 실행
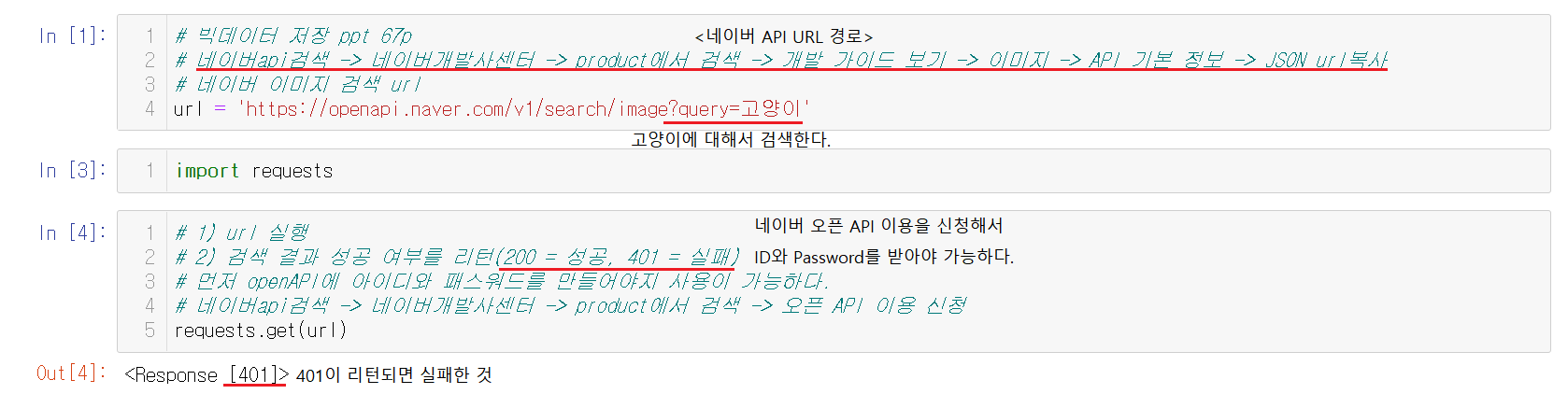
복사한 url을 url변수에 넣어준다. url을 실행시켜보면 현재는 401로 리턴되서 실패하는 것을 볼 수 있다. 오픈 API 이용 신청을 완료하고 ID와 Password를 받아야 실행이 가능하다.
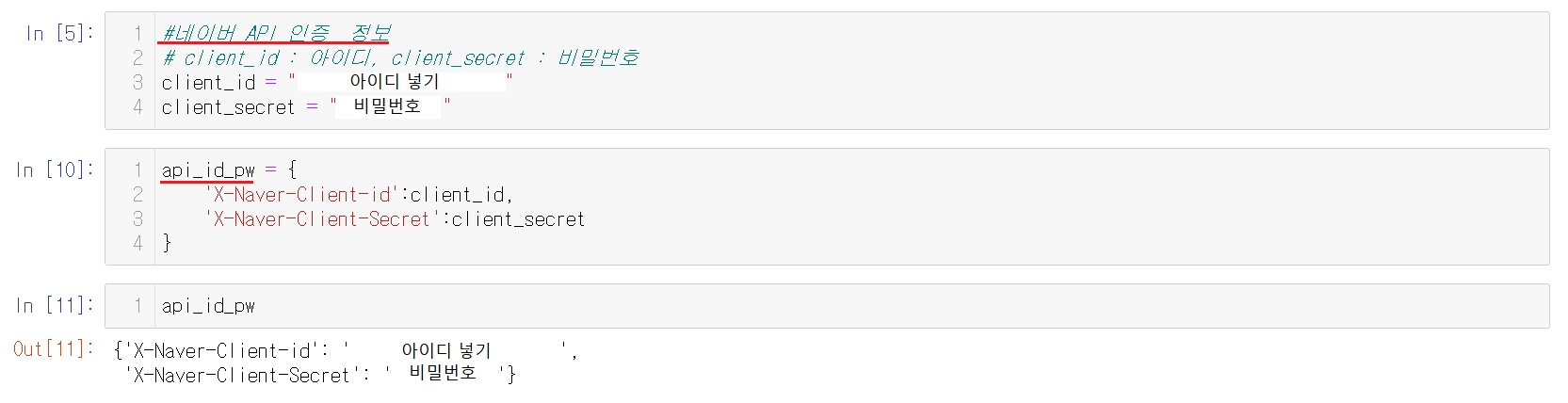
오픈 API를 신청해서 ID와 Password를 받았다면 client_id : 아이디, client_secret : 비밀번호를 넣어서 설정해준다.

header에 지정한 저장해놓은 API의 ID와 Password를 주면 200을 리턴해줌으로 성공했음을 확인할 수 있다.
1-8-4) 검색 결과 출력하기
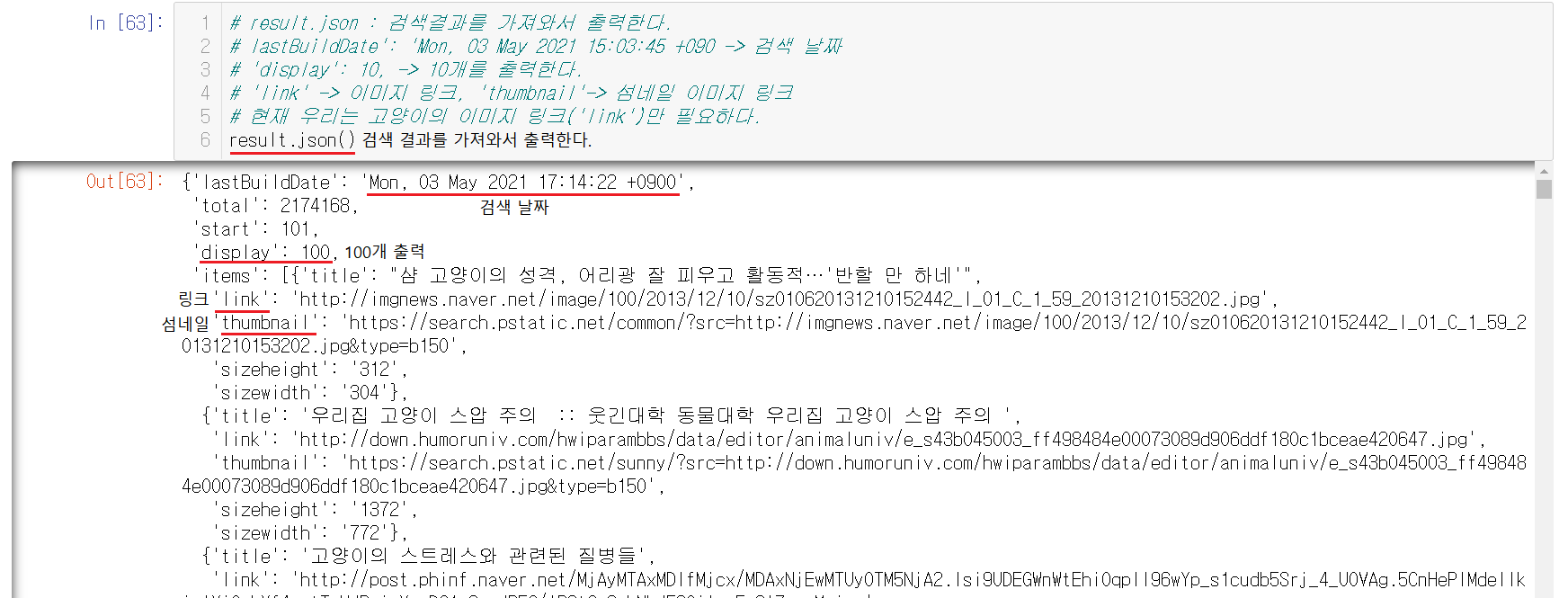
result.json()으로 검색 결과를 출력할 수 있다.
- lastBuildDate: 검색 일시
display: 출력 갯수
link: 이미지 링크
thumbnail: 섬네일 링크
이런식으로 이루어졌는데 현재 우리는 링크만을 알고 싶은데 링크는 items안에 위치해 있음을 알 수 있다.
1-8-5) items 확인하기
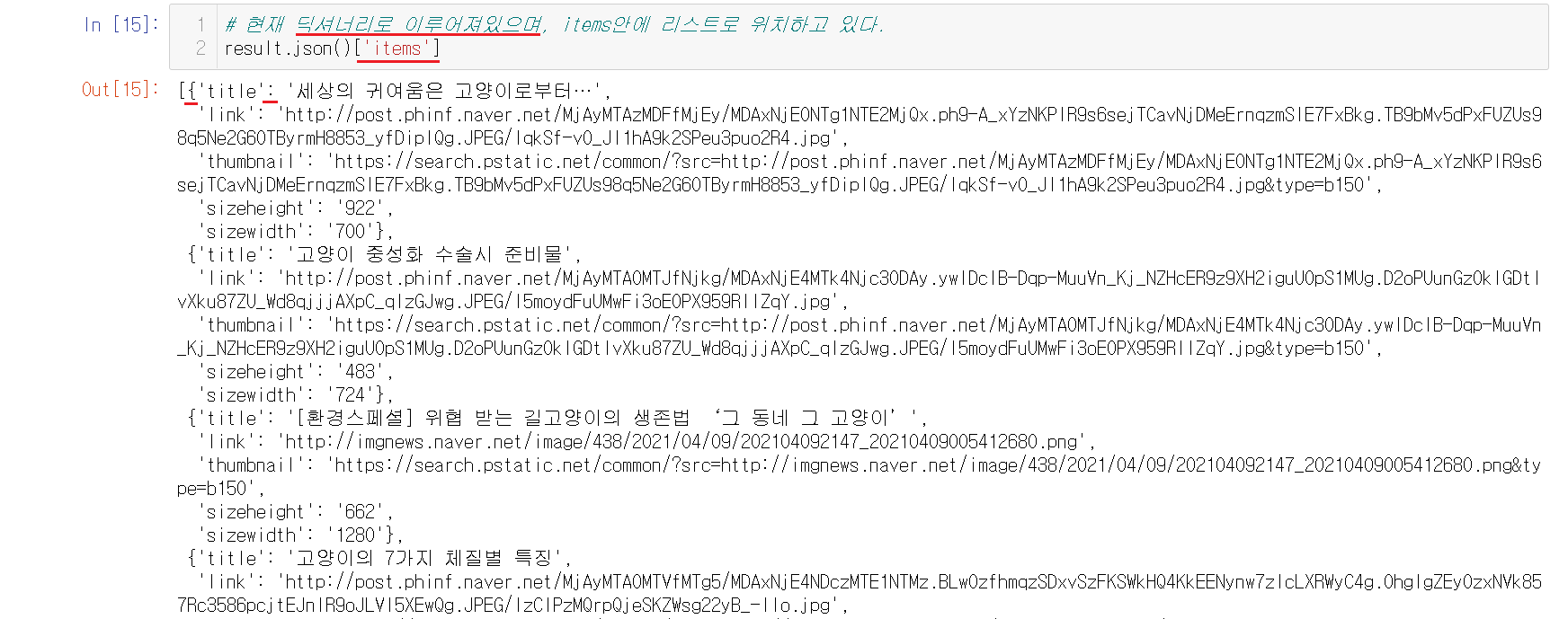
링크가 들어있는 items를 확인해보니 딕셔너리 구조안에 링크가 들어있음을 알 수 있다.
1-8-6) 링크 출력하기
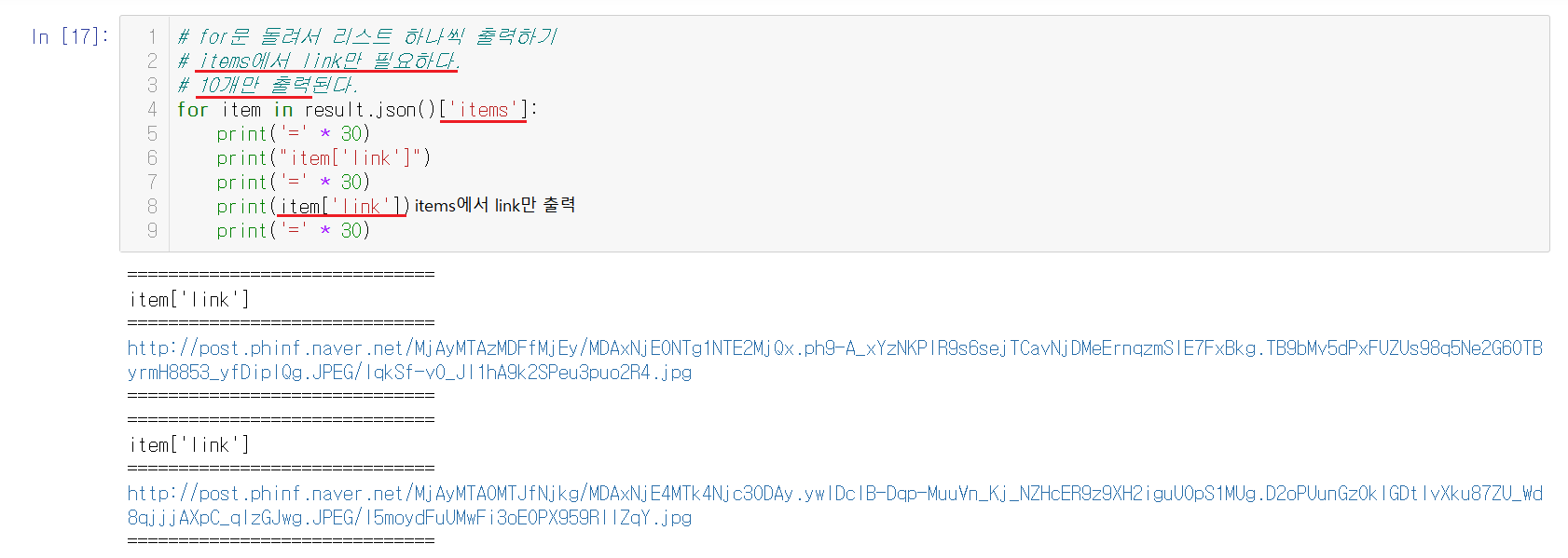
for문을 통해서 찾고자했던 link만을 출력할 수 있다. items를 하나씩 돌려서 link만을 출력하면 되는데 이 때 요청변수에서 봤던 것과 같이 기본값인 10개만 출력된다.
1-8-7) 100개 출력하기

url에서 start와 display로 출력을 정할 수 있다. start를 통해서 1부터 display를 통해서 100까지를 지정해주었다. url를 사용하기위해서 API 설정한 값도 넣어주고 위에 사용한 for문을 넣어서 링크 100개가 출력 가능하다.
1-8-8) 101부터 100개 출력하기
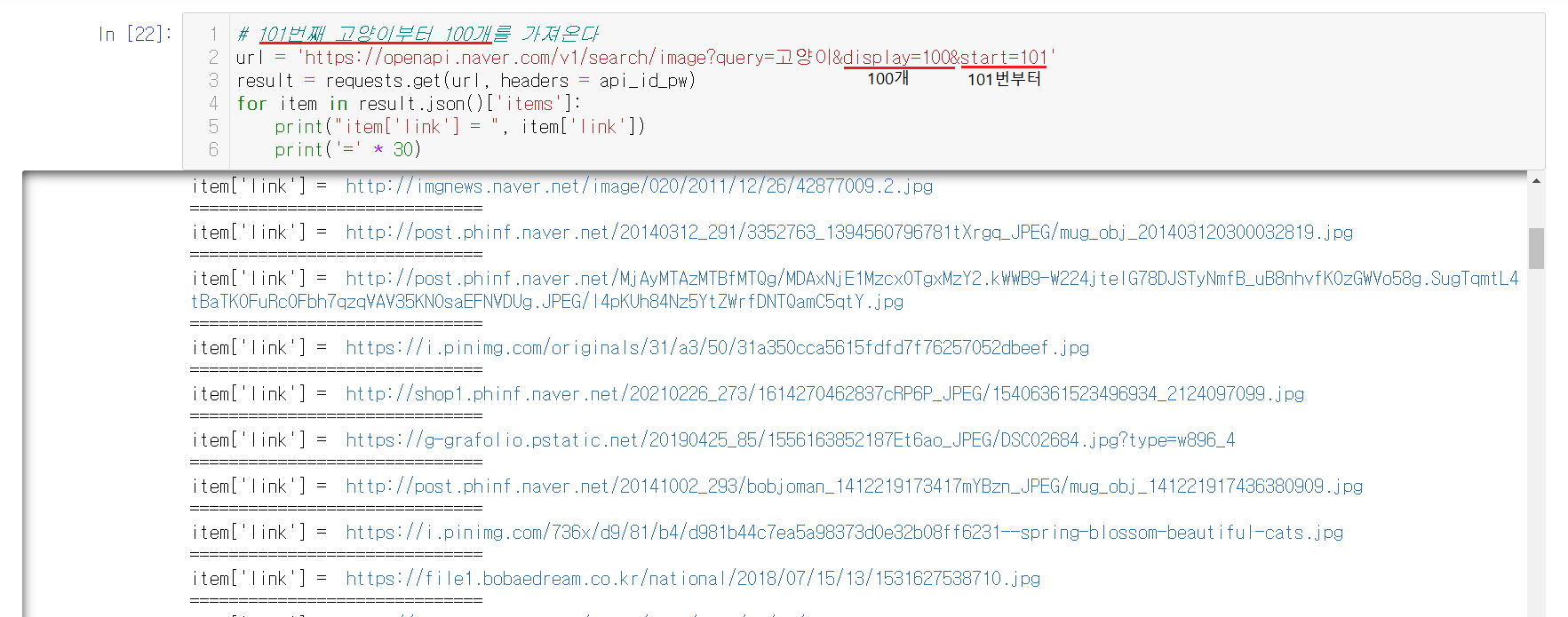
100개를 출력한 후, 다음을 출력할 때는 start를 101로 지정해서 101부터 시작해서 display로 출력할 갯수를 설정해주면 된다.
1-8-9) 검색어와 갯수를 지정하는 함수 만들기

하나 하나 지정하지말고 여러 키워드를 넣어서 검색할 수 있도로 함수를 만든다. 키워드와, 출력할 갯수, 시작하는 부분을 위에서 url을 통해서 지정한 것 처럼 받아서 지정해주도록 함수를 만들어준다.
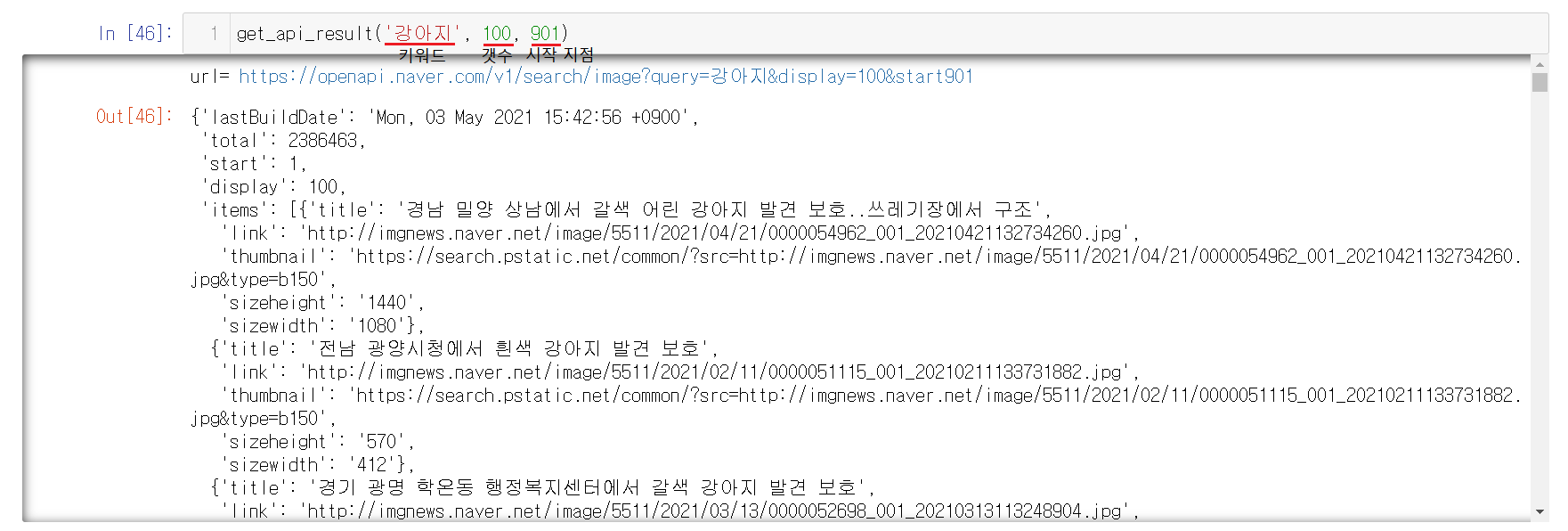
함수를 실행키셔보니 강아지 키워드로 설정되어서 나오는 것을 확인할 수 있으니, 함수가 잘 실행된다는 걸 알 수 있다. 하지만 링크뿐만이 아닌 모든 정보가 나오게 된다.
1-8-10) 링크로만 출력되는 함수 만들기
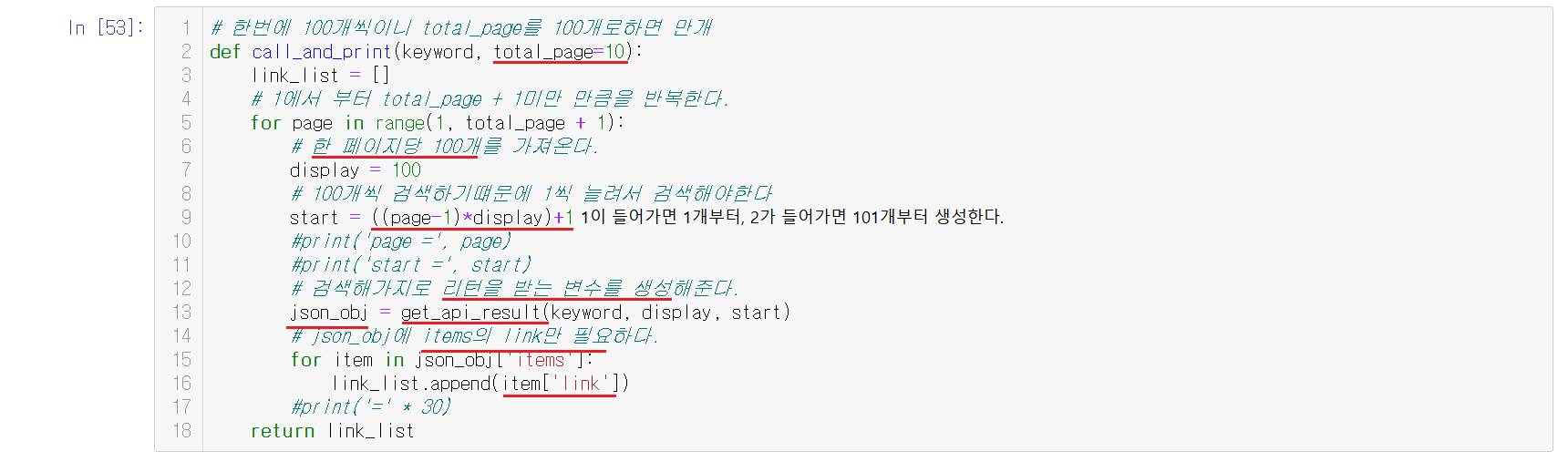
위의 만든 함수를 참고하여서 모든 정보가 아닌 링크를 출력할 함수를 만든다. total_page를 통해서 검색할 페이지를 지정해준다. 1번 실행할 때마다, 100개씩이 최대로 100개씩 출력하기로 한다. startstart = ((page-1)*display)+1 를 확인해보면 1, 101, 201 등의 1로 시작되도록 설정되어있다. 검색을 했다면 리턴을 받아야하는데 그 함수는 위에 지정한 함수를 사용해준다. 위의 함수로 검색한 페이지들의 내용을 받는다. 이제 우리가 필요한거는 items중에 link이다. link를 받아오기 위해서 for문을 사용해서 출력해주면 키워드만 넣으면 link들을 출력해주는 함수를 만들 수 있다.
결과를 확인해보면 키워드를 지정해서 링크만 받아와지는 것을 확인할 수 있다.
'PBL 빅데이터 > 빅데이터 저장' 카테고리의 다른 글
| [수업] 빅데이터 저장2 (0) | 2021.05.04 |
|---|
