HDFS에 들어있는 csv파일을 불러와서 pyspark로 전처리를 진행하려고한다.
1) Pyspark 불러오기
import pyspark
2) SparkSession 설정하기
# pyspark 불러오기
from pyspark.sql import SparkSession
# appName은 아무렇게나 원하는대로 설정이 가능하다.
sparkSession = SparkSession.builder.appName("SparkSession").getOrCreate()
sparkSession
# output의 UI에 들어가서 진행되는 작업들에 대해서 확인할 수 있다.
3) CSV파일 읽기
# import 하기
from pyspark.sql import SparkSession, SQLContext
from pyspark.sql.types import *
from pyspark.sql import functions as F
from pyspark.sql.types import StructType, StructField, StringType
# schema 설정하기
schema = StructType([
StructField("Date", StringType(), True),
StructField("Category", StringType(), True),
StructField("News Name", StringType(), True),
StructField("Title", StringType(), True),
StructField("Article", StringType(), True),
StructField("Url", StringType(), True)])
# hdfs ip를 넣어주고 namenode의 위치를 지정하고 csv파일 불러오기
# header가 없음으로 header=False로 진행하기
# 인코딩이 필요하면 encoding = 'utf-8' 이런식으로 사용하기
# 지정한 schema로 데이터 타입과 header가 될 수 있다.
df_130128 = sparkSession.read.csv("hdfs://192.168.56.104:8020/test_1/Article_경제 일반_20130128.csv", header=False, schema=schema)
df_130128.show()
현재는 Nifi에서 character set을 변경해주어서 utf-8으로 변환되서 한글이 깨지지않고 나타나게 됨으로 따로 인코딩이 필요하지않다.
4) 기사 내용 전처리하기
4-1) 중복되지 않는 언론사 확인하기
# 언론사중에 유니크한 값들만 뽑아보기
df_130128.select("News Name").distinct().show()
c = df_130128.select("News Name").distinct()기사를 전처리하는 과정에서 기사 내용에 언론사 이름과 기자 이름이 기재되는 경우가 있다. 언론사의 이름은 중요한 정보가 아님으로 들어있는 언론사 이름을 뽑아서 기사 내용에서 제거하려고 한다.
4-2) 제거할 언론사를 list로 담기
# 유니크한 언론사들을 list로 변경하기
news_name= c.agg(F.collect_list(F.col("News Name"))).collect()[0][0]
# 리스트 확인하기
news_name
리스트안에 언론사가 담겨있음을 확인 가능하다.
4-3) 제거할 단어 리스트 만들기
# 제거할 단어들 리스트를 만들고 언론사랑도 합쳐주기
other_list = ['image0', 'photo', '제공', '이미지', '투데이', '자료사진', 'SUB', 'TITLE', 'START', '앵커', '포토', '기자', '사진', '집중취재', '뉴스데스크', '구독신청', '재배포', '출처', '여러분의', '제보를', '기다립니다', '나의', '운세s', '만화', '보기', 'fnRASST']
# 제거할 언론사랑 합치기
del_list = news_name + other_list
del_list기사 내용에서 제거할 단어들의 리스트를 만들어주었다.
5) 제거하기
# 해당되는 단어들을 공백으로 변경하기
for word in del_list:
print(word)
df_130128 = df_130128.withColumn('Article', F.regexp_replace('Article', word, ''))
df_130128.filter(df_130128.article.like(word)).show()for문을 돌려서 해당되는 단어들을 찾아서 그 단어들을 공백으로 변경해주는 과정을 진행한다. 한 단어에 대한 작업이 끝나면 그 단어가 더 이상 존재하지 않는지 확인하기 위해서 like를 사용해서 확인하는 과정도 들어있다.

제거된 단어가 위에 표시되고 밑에는 like를 이용해서 검색한 결과가 나타난다. 현재 확인해보면, 결과에 아무것도 나타나지 않음으로 단어가 잘 제거되었다.
6) 특수 문자 제거하기
# 한글, 영어만 남기고 제거하기
df_130128 = df_130128.withColumn('Article', F.regexp_replace('Article', '[^a-zA-Z가-힣]', ' '))
df_130128.show()한글과 영어 이외의 문자들을 제거해주었다. 기사에 사용된 특수 문자들은 의미가 없음으로 제거해준다. 주가에 영향을 주는 단어들을 찾는 것으로 숫자는 상관이 없음으로 숫자들도 제거해준다. 회사 이름중에서 LG전자 등의 영어로 이루어진 이름도 존재함으로 영어는 남겨둔다.
- 제거 전
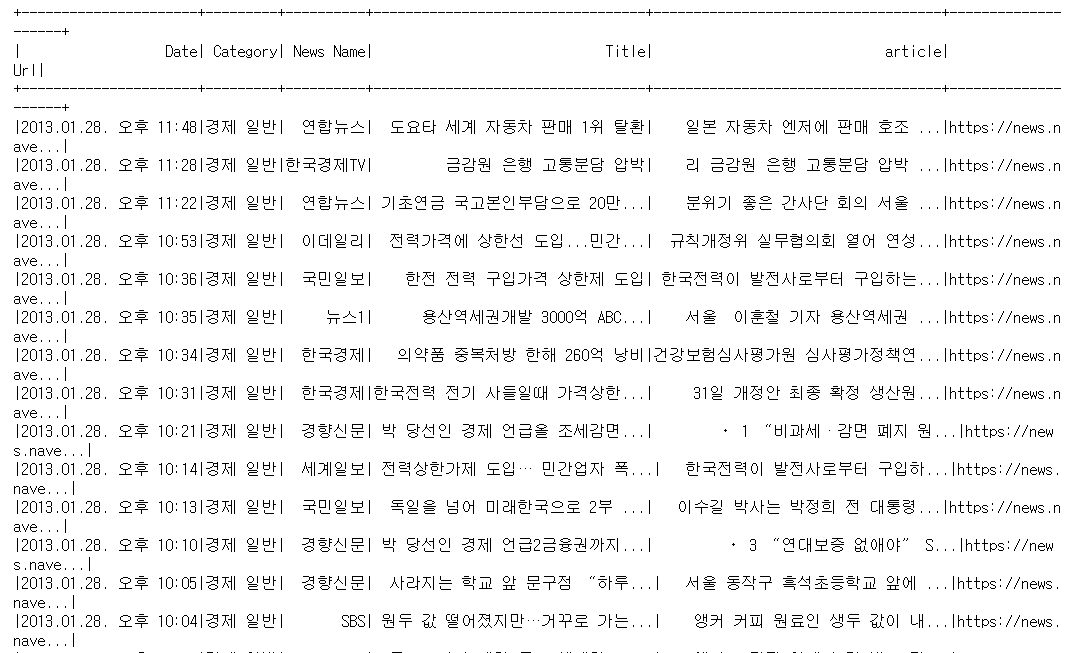
- 제거 후(한글, 영어 제외하고 제거)
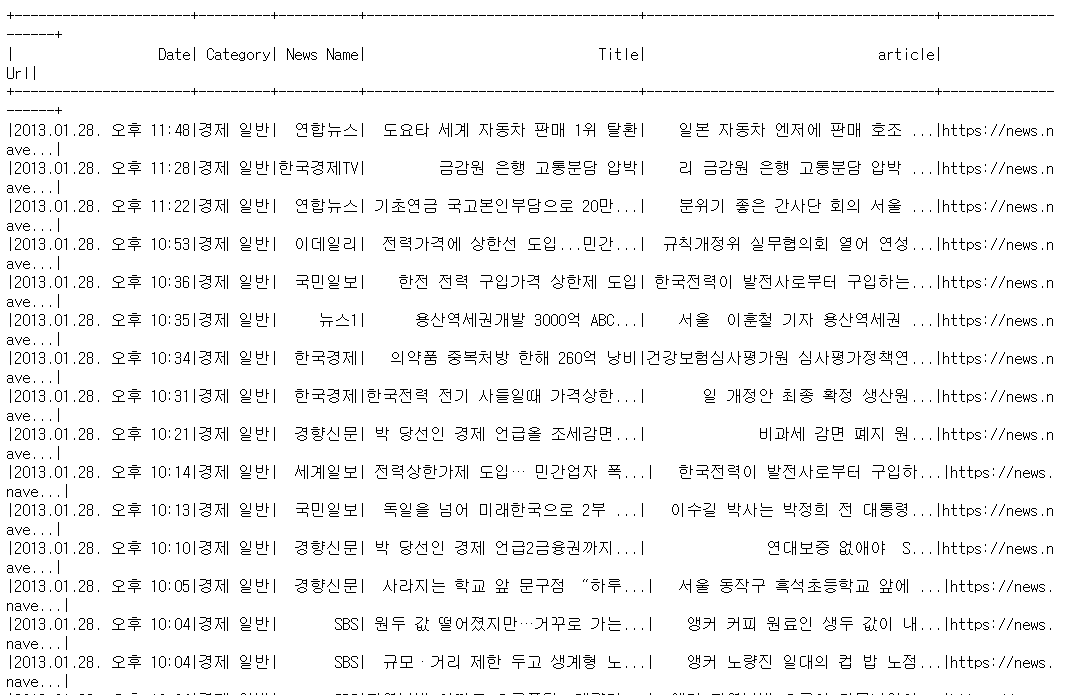
한글과 영어를 제외하고 다른 문자들이 제거되었음을 확인이 가능하다.
'PBL 빅데이터 > 산학프로젝트' 카테고리의 다른 글
| [산학프로젝트] MobaXterm 사용하기 (1) | 2021.08.30 |
|---|---|
| [산학프로젝트] Nifi 한글 인코딩 변경하기 (0) | 2021.08.30 |
| [산학프로젝트] Nifi Java version 오류 해결하기 (0) | 2021.08.30 |
| [산학프로젝트] Cloudera QuickStart VM 설치하기 (0) | 2021.08.30 |
| [산학프로젝트] Happybase 설치하기 (0) | 2021.08.30 |

