2-5) Spark Decision Tree
* Spark DataFrame 분할
- 줄, 칸이 블럭으로 나눠져있다.
- 눈에는 하나지만 다 따로 따로 분리되어있는 데이터이다.
1) 직접 나눌 수 있음(만들 때, repartitioning 으로도 나중에 변경 가능)
2) Spark에서 자동으로 분리(줄,칸이 증가하면)
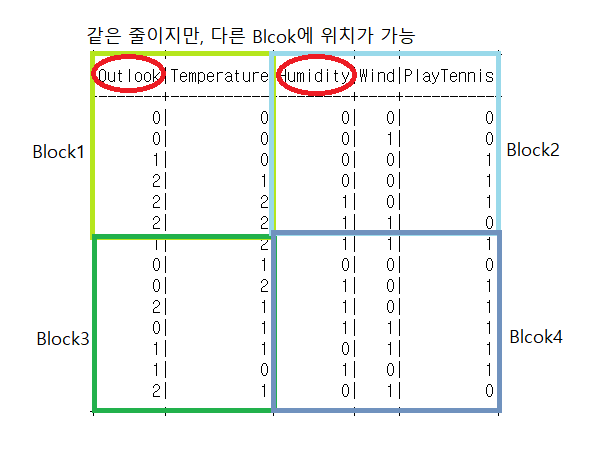
예를 들어보자면, 그림처럼 나뉘어서 Block에 들어가서 저장될 수도 있다. 만들 때 혹은 repartitioning으로도 나중에 직접 나누기가 가능하다. 다른 방법으로는 Spark가 자동으로 분리하기도한다. Spark의 줄과 칸은 Block에 나뉘어있기에 같은 줄에 있어도 다른 Block에 위치할 수도 있다. Spark DataFrame에서 withColumn 함수를 사용하면 나누어진 모든 Block들이 동시에 실행된다. 동시에 실행하기에 빠르며 빅데이터 처리에 용이하다.
2-5-4) Decision Tree 실행하기
2-5-4-1) 데이터 확인하기

Decision Tree를 생성하기전에 먼저 데이터들을 확인해준다.
2-5-4-2) 독립변수를 모아주기
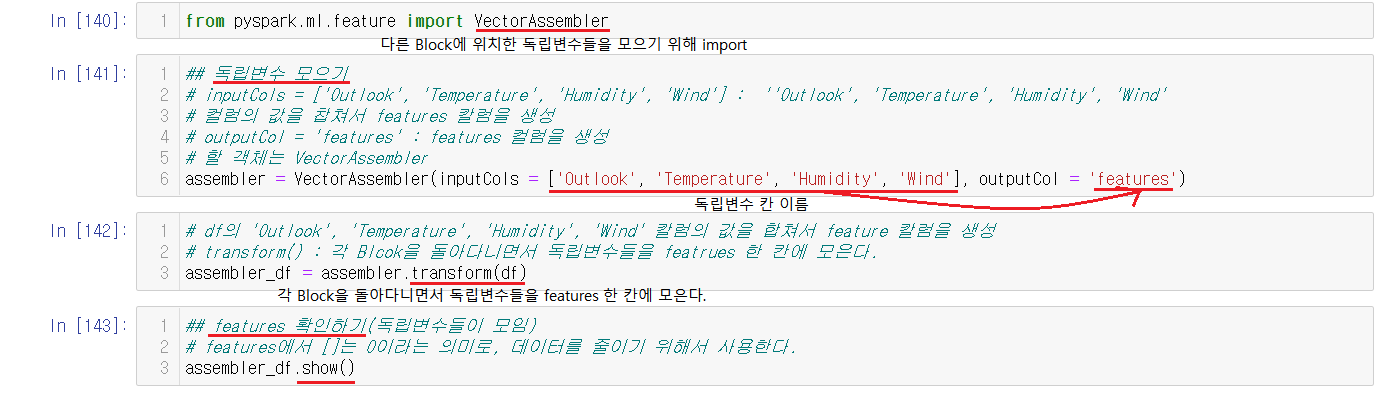
위에했던 설명과 같이 Spark DataFrame은 같은 줄이라도 다른 Block으로 나누어져있을 수 있다. 그렇기때문에 이렇게 같은 줄의 위치한 독립변수들은 한 대의 컴퓨터안에 한 Blcok에 위치하도록 나눠진 독립변수들을 모아주는 절차가 필요하다.
VectorAssembler는 흩어져있는 독립변수들을 같은 Block으로 모아주는 역할을 한다. 모으기 이전에 먼저 import로 진행해준다.
assembler = VectorAssembler(inputCols = ['Outlook', 'Temperature', 'Humidity', 'Wind'], outputCol = 'features')여기서 assembler는 독립변수를 모을 객체로 아직은 모아지지않은 객체이다.
VectorAssemble(inputCols = ['독립변수 칸 이름], outputCol = '모아줄 컬럼의 이름'이렇게 구성된다.
이제 객체를 실행시켜줘야하는데 이 객체를 실행시키는 것은 transform이다.
assembler_df = assembler.transform(df)transform은 각 Blcok을 돌아다니면서 독립변수들을 featrues 한 칸에 모으는 것을 실행한다.
transform까지 실행시켜서 독립변수를 모아주었으니 모아준 값(features)을 확인해준다.

칸과 줄이 많거나, 데이터를 처리하는데 시간이 오래걸린다면 Spark DataFrame을 사용한다. Spark DataFrame은 큰데이터들을 빠르게 처리해줄 수 있기 때문이다. 그러한 이유로 0을 [ ]으로 표기해서 데이터를 줄여서 빨리 실행하도록 한다.
2-5-4-3) Decision Tree 데이터 나누기
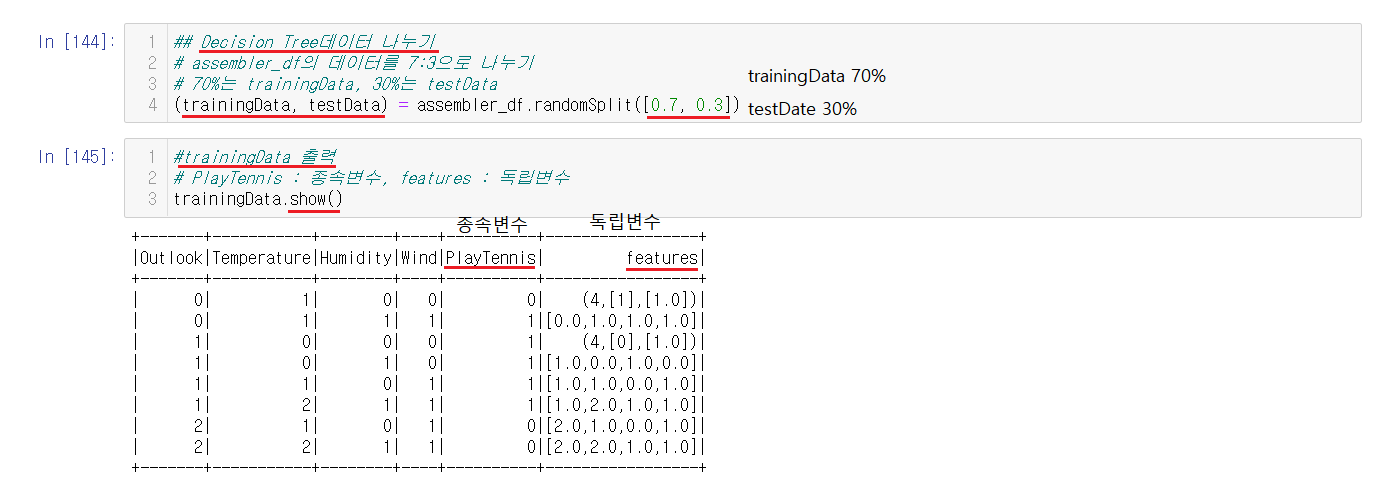
Decision Tree는 Decision Tree를 만들기 위한 train데이터와 성능을 측정하기 위한 test로 나뉜다. 그렇기에 똑같이 train데이터와 test데이터를 나눠준다. [0.7, 0.3]으로 적어주어서 trainingData(train데이터)를 70%, testData(test데이터)30%로 지정해서 랜덤으로 데이터들을 나눠준다.
나눈 데이터를 혹시 모르니 확인해주는 작업도 진행한다. show()를 통해서 확인할 수 있다.

2-5-4-4) Decision Tree 생성하고 실행하기

Decision Tree를 만들 객체를 먼저 생성한 후에 실행을 시켜주어야한다.
DecisionTreeClassifier(featuresCol = 'features', labelCol = 'PlayTennis')DecisionTreeClassifier라는 객체에 독립변수는 featrues에 종속변수는 PlayTennis로 지정해준다.
아직까지는 객체만 생성한 것이고 Decision Tree를 실행하기위해서는 fit()을 사용해주어야한다.
확인해보면 depth와 nodes가 나오는데 depth는 트리의 단계를 뜻한다.
2-5-4-5) 예측값 생성하기

데이터를 나누고 Decision Tree가 완성되었으니, testData를 가지고 성능을 테스트해보기위해서 예측값을 만든다. 예측값은 transform(testData)를 통해서 만들 수 있다. 생성되는 예측값은 features의 독립변수의 값을 가지고 Decision Tree로 예측된다.
2-5-4-6) 예측값과 진짜값을 비교하기

filter를 통해서 조건과 만족하는 것을 리턴하는데 현재 조건은 PlayTennis와 prediction의 값이 같은 것이므로 진짜값인 PlayTennis와 예측값인 prediction을 비교한 후에 같은 줄을 리턴한다. 같은 줄을 출력해서 확인해보니 같은 값이 들어있어서 맞는 예측이었음을 알 수 있다.
2-5-4-7) 정확도 확인하기

testData중에서서 예측이 맞은 개수를 전체 testData의 개수로 나눠주면 얼만큼 맞았는지 정확도를 알 수 있다. 현재 정확도를 계산해보니 50%로 측정됨을 알 수 있다. 각 자 train과 test가 다르게 측정됨으로 정확도가 다를 수도 있다.
2-5-5) Decision Tree 시각화하기
2-5-5-1) 독립변수, 종속변수 확인하기


Decision Tree를 시각화하기전에 먼저 독립변수와 종속변수들을 확인해본다.
※ dtreevize가 실행되지않을 때

import를 했을 때, 오류가 난다면 dtreevize가 설치되어있지않아서 오류가 난 것 일 수 있으니, pip을 사용하여서 dtreeviz를 설치해준다.
2-5-5-2) Decision Tree 내용 확인하기

dtModel은 Decision Tree를 실행한 객체로 nodes가 들어있다. toDebugString은 내용을 조회하는데 dtModel에 사용해서 Decision Tree의 내용을 확인할 수 있다.
2-5-5-3) Pandas DataFrame으로 변경하기
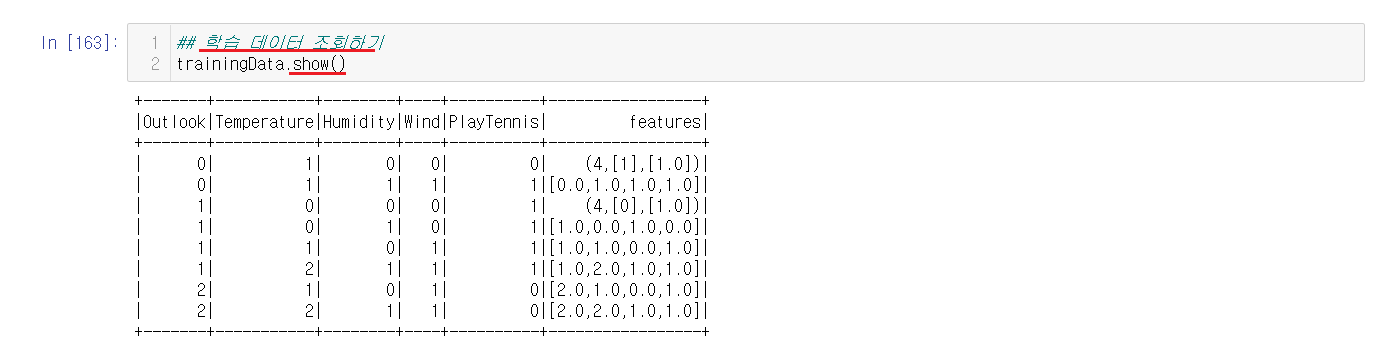
Pandas DataFrame으로 변경할 trainingData가 잘 들어있는지 확인해준다. Decision Tree는 trainingData로 이루어져있으니 trainingData를 사용한다.

Spark로 시각화를 하기에는 Block으로 나누어져서 시각화하기 힘들기때문에 하나로 모아주어야한다. Pandas는 하나의 컴퓨터에 모여있기때문에 Pandas로 변환해서 사용해준다.
toPandas를 사용하여서 Spark DataFrame -> Pandas DataFrame으로 변경해준다.
2-5-5-4) 시각화할 컬럼을 지정하기

Pandas DataFrame으로 바꾼걸 확인해보니 features도 포함되어있는데 시각화에는 필요하지않기때문에 나타낼 컬럼들만 dataset으로 지정해주고 확인해준다.
2-5-5-5) 시각화 출력 정보 설정하기

시각화에서 출력할 정보들을 설정해준다.
ShadowSparkTree( Decision Tree,
독립변수 데이터,
종속변수 데이터,
독립변수 컬럼 이름,
종속변수 컬럼 이름,
종속변수 데이터)식으로 진행해준다.
2-5-5-6) 시각화하기

시각화를 진행해주는데
trees.dtreeviz(시각화 출력 정보, scale = 2.0)로 진행해주는데 scale은 크기를 의미한다. 1.0은 100%, 2.0은 200%로 확대라고 생각하면 된다.

실행해보면 진행된 Decision Tree를 시각화해서 확인할 수 있다. 독립변수에 값에서 평균을 구해서 이하와 초과로 나뉘어지면서 뻗어나간다. 처음에 시작하는 독립변수는 Outlook으로 시작하는데 시작하는 순서는 Gini값이 작은 순서대로 이루어진다.
※ 시각화가 출력이 안될 때
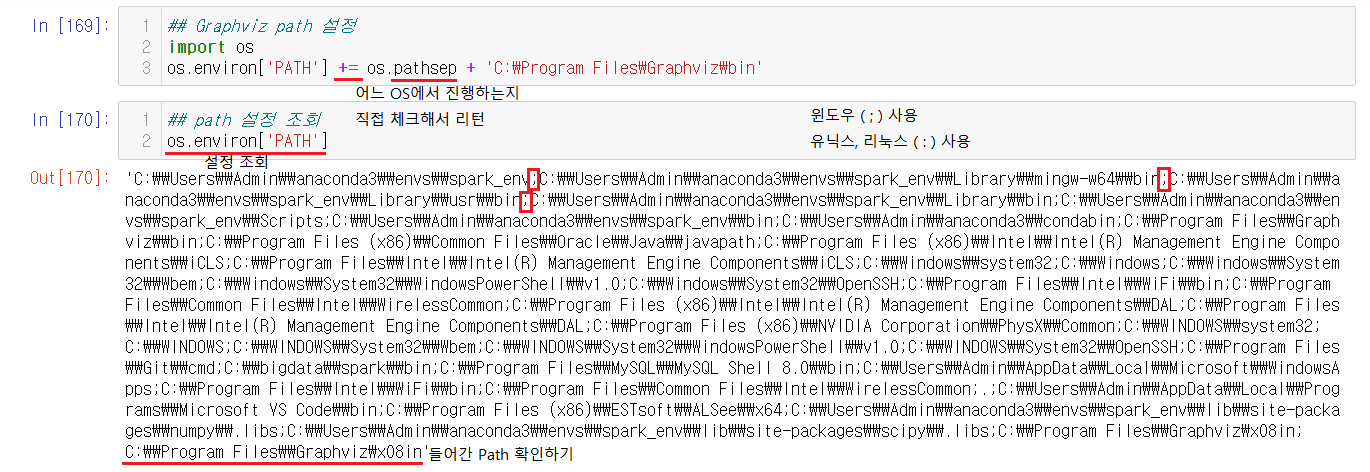
Graphviz가 설치되어있는데도 실행되지않는다면, Path가 지정되지않아서이다. Path를 지정해주면 되는데 이러한 방법 혹은 직접 환경변수 -> Path에서 설정해주는 방법도 있다.
* Gini Index(지니 지수)
- 데이터 집합의 불순도를 측정한다.
- 지니 지수는 0 ~ 1 사이의 값을 가지며, 낮을수록 순수도가 높은것이므로 좋다.

지니 지수는 위의 계산식으로 계산할 수 있다.
어제 실행한 Spark를 사용하지않은 Decision Tree를 생각해보면

이런식으로 진행된다. y_train('PlayTennis')을 계산하는식을 살펴보면 총 11개의 데이터에 1('No')이 3개, 2('Yes')가 8개 이를 지니 계산식에 넣어서 진행한 것을 확인할 수 있다.

Outlook의 지니 지수를 확인해보면, 전체 개수에서 No, Yes인 경우를 나누어서 계산해서 지니 지수 계산을 진행한다. 현재는 왼쪽이 Sunny, 오른쪽이 Overcast, Rain로 이루어져있다. Overcast와 Rain이 같이 있는 이유는 2개로 나눠야하기에 둘이 묶여서 비교되었다. 왼쪽과 오른쪽을 변경해보며 모든 경우의 수를 생각하면서 계산이 되는데 그 중에서 지니 지수가 더 작은 것이 택해진다.
3) Random Forest를 이용한 데이터 분석
3-1) Random Forest
- Decision Tree의 단점을 개선하기 위한 알고리즘 중 하나이다.
- 서로 다른 Decision Tree가 모여서 Forest를 생성한다는 의미로 Decision Tree의 확장이다.
- 데이터 분류(Classification) : 독립변수, 종속변수
- 데이터 군집(Clustering) : 특별한 종속변수가 없다. 종속변수가 없을 때, 비슷한 것들을 컴퓨터가 Grouping한다. 데이터 분류와 다른점은 종속변수가 없다는 것이다. ex) Kmeans 알고리즘(넷플릭스 시청 정보)
- Feature의 중요성 확인 : 어느 칸이 중요한지에 대한 중요성을 확인한다.
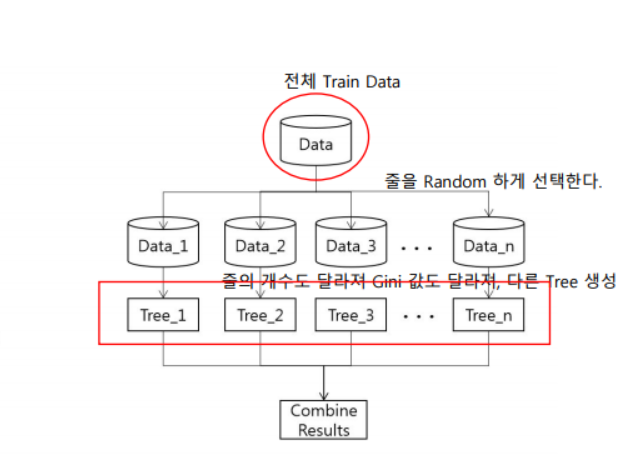
Random Forest는 말그대로 전체 train 데이터에서 줄을 Random하게 선택한다. 랜덤하게 선택된 데이터들은 중복도 가능하다. 이렇게 나눠진 데이터들로 Decision Tree를 만들게 되는데 줄의 개수도 랜덤으로 달라진다. Data가 다 달라서 모든 Decision Tree에 계산된 Gini에 값들도 달라지기에 모두 다른 Decision Tree가 생성된다.
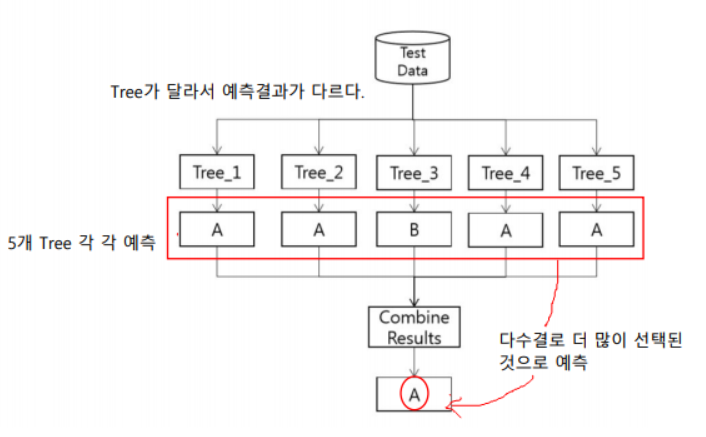
다 다른 Decision Tree로 어떻게 값을 구하게 되는 것인지 살펴보려고 한다. 먼저 각 각 다른 5개의 Decision Tree가 있다고 가정해보자. 성능을 측정하기 위해서 test 데이터를 넣었을 때, 5개의 다른 Decision Tree에서 값이 나오게 된다. 서로 다른 값을 제시할 수도 있는데 이 때에는 다수결의 원칙으로 더 많이 선택된 것으로 예측되게된다.
3-2) Random Forest IRIS 데이터 분류
3-2-1) iris 데이터 불러오기
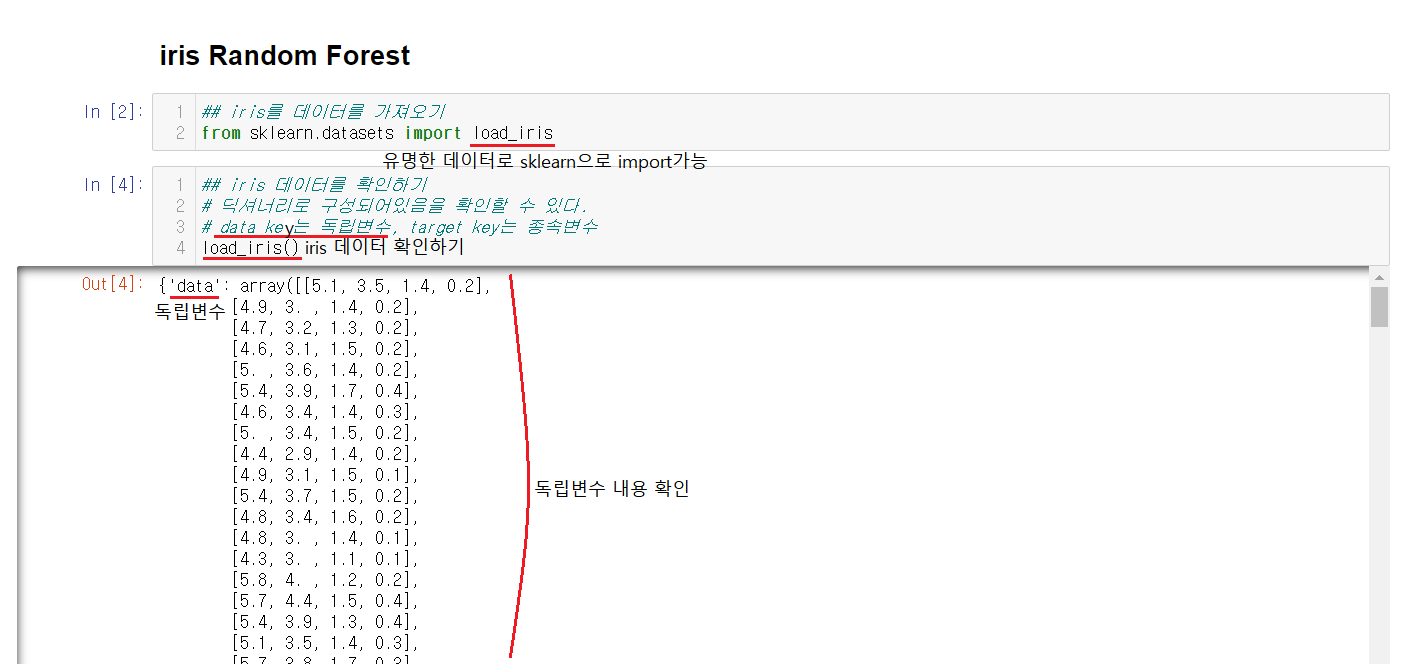

iris의 분류는 유명한 데이터로 따로 자료를 받는게 아닌 sklearn에서 데이터를 불러올 수 있다. 불러온 iris데이터는
load_iris()를 통해서 확인할 수 있다. 내용을 확인해보면 딕셔너리로 이루어져있는데 key값이 2개임을 확인할 수 있다.
data는 독립변수, target은 종속변수로 이루어져있다.
3-2-2) 독립변수, 종속변수 확인하기


독립변수와 종속변수가 data와 target으로 나누어져있는지 확인해본다.
3-2-3) Pandas DataFrame으로 만들어주기
Spark DataFrame은 시각화하기 어렵기때문에 Pandas DataFrame으로 만들어준다. DataFrame을 만들어줄 때,
columns = ['칸 이름', '칸 이름]식으로 리스트안에 칸 이름을 순서대로 지정이 가능하다. 현재는 data로 독립변수만 넣어진 것으로 종속변수를 추가해주어야한다.

DataFrame안에 독립변수와 종속변수가 잘 들어가있는지 확인한다.
3-2-4) 독립변수, 종속변수 지정하기

iris_df.loc[ : , 'sepal length' : 'petal width']를 이용해서 독립변수를 지정한다. loc에서 첫번째 : 안에는 줄에 대한 조건을 지정해주는 것인데 현재는 전체의 줄을 조회할거기에 아무것도 적어주지않았다. 두번째 : 안에는 칸에 대한 조건을 지정해주면 되는데 주의해야할 점은 보통 쓰던 이상과 미만이아닌 이상과 이하임을 체크해야한다. 독립변수는 X를 사용하는 것이 보편적임으로 X안에 독립변수들을 넣어준다.

종속변수는 target 혼자임으로 target를 하나만 써서 지정할 수 있다. 종속변수는 보편적으로 y를 사용함으로 y에 종속변수를 넣어준다.
3-2-5) train, test 나눠주기

train_test_split을 이용해서 train, test 데이터를 나눠준다. 이 때, test_size = 0.2로 20%로 설정해줌으로 train 데이터는 80%로 지정된다.
X_train : 독립변수 80%, X_test : 독립변수 20%
y_train : 종속변수 80%, y_test : 종속변수 20%
이런식으로 나누어진담. 변수안에 넣어줄 때는 순서대로 리턴되니 순서대로 변수를 지정해서 넣어주어야한다.
변수를 나눠주고 확인도 잊지말아야한다.


데이터가 다 나뉘었는지 확인한다. 총 150줄로 80%에는 120줄, 20%에는 30줄이 나뉘어져있다.
3-2-6) Decision Tree 생성하기
RandomForest는 여러개의 Decision Tree임으로 Decision Tree를 생성해주어야한다. 현재 우리는 분류를 하는 것이기에 RandomForestClassifier 선택해서 import해준다.
RandomForestClassifier(oob_score = True)Decision Tree nodes에서 컬럼 사용 비율 계산을 보는 것을 지정할 수도 있는데 이는 oob_score = True의 역할이다.
RandomForestClassifier(Decision Tree 개수)혹은 다르게 Decision Tree 개수를 지정해줄 수도 있는데, 지정하지않으면 100개가 기본값이다.
Decision Tree의 객체를 생성했으니, 실행하는건 fit을 통해서 실행할 수 있다.

rfc.estimators_ 로 Decision Tree를 확인할 수 있는데 현재는 설정을 해주지않아서 기본값으로 100개가 생성되어서 100개 출력이 된다.
※ 시각화

시각화를 하다가 Path 오류가 날 수 있으니 미리 Path를 설정해줄 수도 있다.
3-2-7) 첫번째 Decision Tree 시각화하기
3-2-7-1) 첫번째 Decision Tree 내용 지정해주기

from sklearn import tree
import pydotplus
from PIL import Image
from io import BytesIO시각화를 위해서 import를 먼저 진행해준다.
tree.export_graphviz( Decision Tree,
독립변수 컬럼 이름,
종속변수 컬럼 이름)으로 첫번째 Decision Tree 내용 지정해준다.

첫번째 Decision Tree 내용을 확인해준다.
3-2-7-2) 첫번째 Decision Tree 내용 저장, 이미지 변경하기

write_pdf('tree01.pdf')를 통해서 pdf로 Decision Tree가 시각화된 내용을 저장할 수도 있다. 저장한 내용은 현재 jupter notebook을 실행한 곳에 저장되어있다. jupter notebook으로도 그리기 위해서 이미지로 변경하고 이미지 내용을 확인해준다.
3-2-7-3) 첫번째 Decision Tree 출력하기
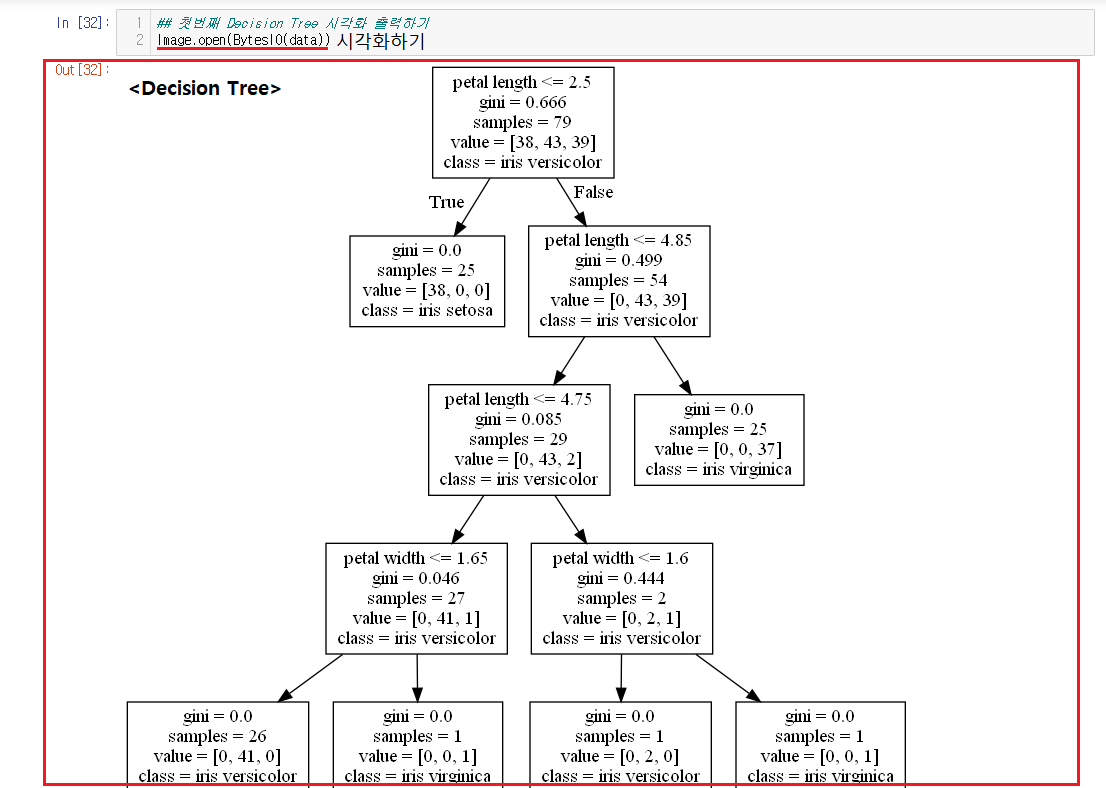
Image.open(BytesIO(data))를 이용해서 이미지 내용이 들어있는 data를 시각화해서 출력한다.
3-2-8) Decision Tree 비교하기
3-2-8-1) 비교하기위해서 Decision Tree 10개 시각화하기

위에서 시각화를 해봤으니 시각화한 코드를 for문에 돌려수 10개의 비교할 Decision을 시각화해서 pdf파일로 저장해준다. 현재 첫번째 Decision Tree는 시각화되었으니 제외해서 range(1, 10)을 넣어서 첫번째 Decision Tree를 제외하고 돌려준다. 역시, 이 파일들도 jupyter notebook을 실행한 곳에 저장된다.
3-2-8-2) Decision Tree nodes 칼럼 사용 비율 확인하기

Decision Tree를 생성할 때,
RandomForestClassifier(oob_score = True)을 통해 컬럼 사용 비율 계산을 볼 수 있게 지정했었어서 rfc.feature_importances_ 을 통해서 비율을 확인할 수 있다.
array([0.09577878, 0.02363488, 0.45272171, 0.42786464])
# [0번째 컬럼 사용 비율(sepal length), 1번째 컬럼 사용 비율(sepal width), 2번째 컬럼 사용 비율(petal length), 3번째 컬럼 사용 비율(petal width)]식으로 이루어져있다.
보기에는 어려우니 컬럼명과 합쳐서 사용해줄 수 있는데 zip을 사용해서 혹은 zip을 사용하고 for문에 넣어서 더 깔끔하게 출력이 가능하다.
sepal length : 0.09577877720584785
sepal width : 0.023634880537093023
petal length : 0.45272170682692353
petal width : 0.4278646354301357비율이 높을수록 많이 사용된 것이다. 사용 비율이 적은 것들은 지니가 높아서 사용하지 않은 것으로 예측할때의 중요도가 낮다.
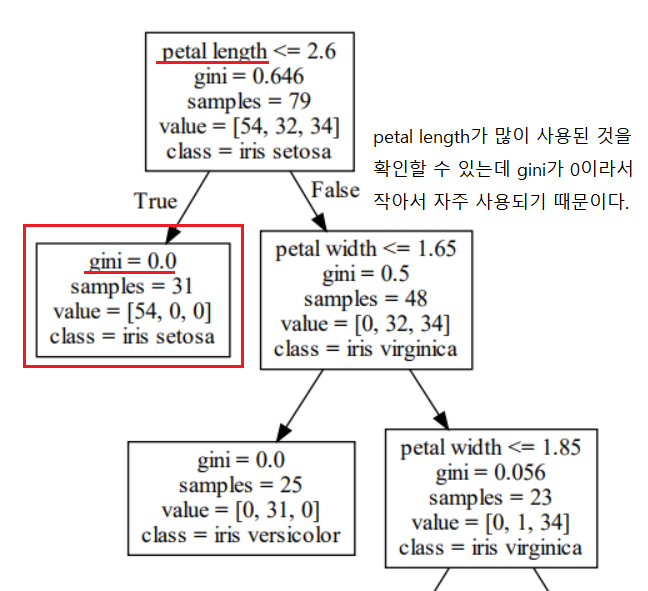
많이 사용한 petal length, petal width가 중요함을 알 수 있다. 그렇기에 시각화해준 Decision Tree를 확인해보면, petal length의 gini가 0으로 작아서 자주 사용됨을 알 수 있다.

petal width의 gini도 0으로 작아서 자주 사용된다. 즉 ,이 둘의 gini가 0으로 자주 사용되어 중요도가 높다.
3-2-9) 예측값과 진짜값 비교하기
3-2-9-1) 예측값과 진짜값 구하기

예측값을 predict를 이용해서 구하고 그와 비교할 진짜값을 확인해준다.
3-2-9-2) 예측값과 진짜값 비교하기
predict == y_test을 통해서 예측값과 진짜값을 비교할 수 있는데 같으면 True, 틀리면 False로 출력된다.
3-2-9-3) 예측값과 진짜값 정확도 구하기

정확도 구하는 방법:
1) 예측이 맞은 개수 / 전체 예측 개수
2) accuracy_score(진짜값, 예측값)
현재 정확도는 약 97%임을 확인할 수 있다.
3-2-9-4) 예측값과 진짜값 확인해보기

| 예측0 | 예측1 | 예측2 | |
| 진짜0 | 8(진짜0, 예측0) | 0(진짜0, 예측1) | 0(진짜0, 예측2) |
| 진짜1 | 0(진짜1, 예측0) | 11(진짜1, 예측1) | 1(진짜1, 예측2) |
| 진짜2 | 0(진짜2, 예측0) | 0(진짜2, 예측1) | 10(진짜2, 예측2) |
confusion_matrix 는 성능을 볼 때, 사용한다. 위의 표로 구성되어있는데 진짜값과 예측값이 어떻게 예측되었고 몇개가 맞았는지를 확인할 수 있다.
'PBL 빅데이터 > 빅데이터 처리' 카테고리의 다른 글
| [수업] 빅데이터 처리3 (3) | 2021.05.10 |
|---|---|
| [수업] 빅데이터 처리1 (0) | 2021.05.06 |

