안녕하세요. 오늘은 저번글에 이어서 Kubernetes에서 Helm을 이용해서 Airflow를 설치한 후, Connection 부분에서 Oracle과 Kafka를 설치해서 추가하고 이를 설정해서 사용하는 방법에 대해서 작성해보려고 합니다. Connection은 Variable은 보안적인 부분에서 우수함으로 보통 DB 접속에 필요한 비밀번호가 들어있는 정보를 저장하기에는 더 나은 방법이라고 합니다. Connection 에는 기본적인 DB에 대한 설정이 있지만, Oracle, Kafka는 없기에, 이제 어떻게 설치할 수 있는지 어떻게 사용할 수 있는지에 대해서 알아보고자 합니다👻
1. Oracle Connection 설치 및 설정하기
1-1. Oracle Instant Client 다운받기
밑의 링크를 통해서 본인의 서버에 맞는 버전을 선택해서 다운받기를 진행합니다. 현재의 저는 Rocky Linux 9.4를 사용하고 있으며, Rocky Linux의 버전은 Linux x86-64 버전입니다.
https://www.oracle.com/database/technologies/instant-client/downloads.html
Oracle Instant Client Downloads
www.oracle.com
1-2. 파일 실행 및 설정
1-2-1. 압축 해제
mkdir -p /usr/lib/oracle
unzip instantclient-basic-linux.x64-21.16.0.0.0dbru.zip -d /usr/lib/oracle
mkdir -p /usr/lib/oracle
unzip instantclient-basic-linux.x64-[Version]dbru.zip -d /usr/lib/oraclels /usr/lib/oracle/instantclient_21_16
ls /usr/lib/oracle/instantclient_[Version]- 압축이 잘 해제되었는지는 ls 명령어를 사용해서 확인할 수 있습니다.
- 각 자 설치한 버전의 맞게 `21_16` 부분을 변경 필요합니다. 저는 21.16 버전을 사용함으로 앞으로 21.16이 적혀있는 부분에는 여러분이 받으신 버전과 동일하게 변경해서 사용하시면 됩니다.
1-2-2. 환경 변수 설정하기
MY_ORACLE_DB =
(DESCRIPTION =
(ADDRESS = (PROTOCOL = TCP)(HOST = [HOST])(PORT = [PORT]))
(CONNECT_DATA =
(SERVICE_NAME = [SERVICE_NAME])
)
)- `/usr/lib/oracle/instantclient_21_16/network/admin` 에 들어가서 `tnsname.org` 파일을 생성합니다. 이 때에도 본인의 버전에 맞는 폴더에 들어가서 파일을 생성해주면 됩니다.
- `MY_ORACLE_DB` 이라는 명칭은 변경이 가능하며, `HOST`, `PORT`, `SERVICE_NAME`에 대한 내용은 각 자의 Oracle DB 환경에 맞게 변경해서 적용해주면 됩니다.
1-2-3. 노드 설정하기
export LD_LIBRARY_PATH=/usr/lib/oracle/instantclient_21_16:$LD_LIBRARY_PATH
export LD_LIBRARY_PATH=/usr/lib/oracle/instantclient_[Version]:$LD_LIBRARY_PATH- Kubernetes에 노드에 접속한 후, `export`를 통해서 Oracle 파일의 위치에 대한 환경 변수를 적용해줍니다.
echo "export LD_LIBRARY_PATH=/usr/lib/oracle/instantclient_21_16:\$LD_LIBRARY_PATH" >> /etc/profile.d/oracle.sh
chmod +x /etc/profile.d/oracle.sh
echo "export LD_LIBRARY_PATH=/usr/lib/oracle/instantclient_[Version]:\$LD_LIBRARY_PATH" >> /etc/profile.d/oracle.sh
chmod +x /etc/profile.d/oracle.sh- `export`만 사용하는 처음의 설정은 일시적임으로 위의 명령어를 통해서 영구적으로 환경 변수를 설정합니다. 맞는 버전의 내용을 넣어야함에 유의해야합니다.
source /etc/profile.d/oracle.sh
echo $LD_LIBRARY_PATH- `source` 명령어를 이용하여서 환경 변수를 적용하면 완료입니다.
- `echo` 명령어를 통해서 환경 변수가 잘 설정되어있는지도 확인할 수 있습니다.
1-2-4. 파드 설정하기
현재는 노드에만 설치되어있지만, 정작 Airflow는 각 파드에 설치되어있음으로 PV, PVC에 설정을 진행해주어야지 파드 안에서 사용이 가능하게 됩니다. 이전의 작성했던 Kubernetes에서 Airflow를 설치하는 글을 참고해서 보시면 좋을 것 같습니다. 현재는 그 글과 이어져서 PV로 사용했던 `python-packages` 라고 연동된 폴더에 Oracle 파일들을 옮겨서 진행하려고 합니다. 각 파드에 설치를 해줘도 되지만 이렇게 하는 이유는 Airflow에서 package를 사용하기 위해서는 `webserver, worker, scheduler, triggerer `의 파드에 모두 설치가 되어있어야만 합니다. 그렇기에 조금 더 편하게 하기 위해서 PV를 사용해서 모든 파드에 공유해서 하는 것이 조금 더 쉬운 방법이 될 수 있습니다.
cp -r /usr/lib/oracle/instantclient_21_16 /mnt/data/airflow/python-packages/oracle
cp -r /usr/lib/oracle/instantclient_[Version] /mnt/data/airflow/python-packages/oracle- PV 연동을 위해서 Oralce 폴더를 PV 위치에 복사를 진행해줍니다. 이 때도, 버전의 주의합니다.
env:
- name: PYTHONPATH
value: "/mnt/data/airflow/python-packages/venv/lib/python3.12/site-packages:$PYTHONPATH"
- name: TNS_ADMIN
value: "/mnt/data/airflow/python-packages/oracle/network/admin"
- name: LD_LIBRARY_PATH
value: "/mnt/data/airflow/python-packages/oracle:$LD_LIBRARY_PATH"- 이전 글에서도 Helm으로 설치 시, Yaml 파일에서 env에 Python 경로를 추가했었는데요. 이와 동일하게 이번에도 Oralce의 경로를 노드에서와 같이 지정해주게 됩니다.
- 현재는 python-packages 라는 PV랑 연결되어 있음으로 해당 PV에 맞는 경로로 설정합니다.
- 각 파드에 설치되어야 함으로, `airflow_values.yaml` 파일에서 webserver, worker, scheduler, triggerer 부분에 env를 추가해주어야합니다.
1-2-5. cx_Oracle 설치하기
cx_Oracle 패키지를 각 노드에 설치를 진행해야합니다. 저희에게는 python 패키지를 모아주는 python-packages의 PV가 있어서 각 파드에 설치가 가능함으로 worker파드에 들어가서 PV에 설치를 진행해줍니다.
kubectl exec -it airflow-worker-0 -n airflow -- /bin/bash
kubectl exec -it [POD 이름] -n airflow -- /bin/bash- 현재는 worker 파드에 들어가서 진행했지만, PV로 연결된 webserver, worker, scheduler, triggerer 중에 어느 파드에 들어가서 진행해도 괜찮습니다.
source /mnt/data/airflow/python-packages/venv/bin/activate
pip install apache-airflow-providers-oracle
pip install cx_Oracle
pip install psycopg2- PV로 연결되어있음으로 python-packages에서 venv를 활성화시킨 후에 Connection에서 필요한 cx_Oracle, apache-airflow-providers-oracle, psycopg2 패키지를 설치합니다.
1-3. 확인하기

helm upgrade --install airflow apache-airflow/airflow -n airflow -f airflow_values.yaml --debug- webserver, worker, scheduler, triggerer파드가 새롭게 시작되어야하는데 파드를 일일이 삭제하는 것이 무리기에, helm upgrade로 진행합니다. Airflow에 다시 들어가서 connection을 확인하면 Oracle이 있는 것을 확인할 수 있습니다.
1-4. 추가적인 이슈 해결 방법
Oracle의 버전과 성능에 따라서 추가적으로 발생하는 이슈들이 있습니다. 제가 경험했던 이슈들을 여러분이 경험하실 수도 있음으로 추가적으로 작성해보려고 합니다.
1-4-1. Thin Mode 변경
첫번째 에러는 python-oracledb는 설치가 되면 보통 Thin mode로 진행되는데 현재 디비는 Thick mode로 변경이 필요하다는 에러가 발생하였습니다. 이는 Oracle DB의 버전과 성능에 따라서 다르게 사용될 것 같으며, 제가 사용한 DB에서는 Thick mode로 추가적으로 설정이 필요하였습니다.
import oracledb
oracledb.init_oracle_client(lib_dir="/mnt/data/airflow/python-packages/oracle")- DAG에서 해결할 수 있었는데 이는 oralcedb를 import하고 `oracledb.init_oracle_client`을 사용하여 Airflow env에서 추가했듯이 Oracle의 위치를 지정해서 실행하면 Thick mode로 사용할 수 있게 됩니다.
1-4-2. DPI-1047 에러
DPI-1047에러는 Cannot locate a 64-bit Oracle Client library: "libaio.so.1" 라는 에러로 즉, libaio.so.1 라는 파일이 현재 저희의Oracle 폴더 파일에 들어있지 않음을 의미합니다. libaio.so.1 파일은 `dnf` 명령어를 이용하여 노드에서 설치가 가능함으로 위의 Oracle 설치와 동일하게 노드에서 설치한 후에 PV를 이용해서 넣어주어서 파드에서 사용합니다.
dnf install libaio- 먼저 노드에서 libaio 패키지의 설치를 진행합니다.
cp /usr/lib64/libaio.so.1 /mnt/data/airflow/python-packages/oracle- 필요한 libaio.so.1의 파일을 모든 파드에 공유하기 위해서 python-packages PV에 들어있는 Oracle 폴더에 복사해줍니다.
helm upgrade --install airflow apache-airflow/airflow -n airflow -f airflow_values.yaml --debugwebserver, worker, scheduler, triggerer파드가 새롭게 시작되어야하는데 파드를 일일이 삭제하는 것이 무리기에, helm upgrade로 다시 업데이트를 진행합니다.
1-5. Oracle Hook 사용하기
1-5-1. Connection에 등록하기
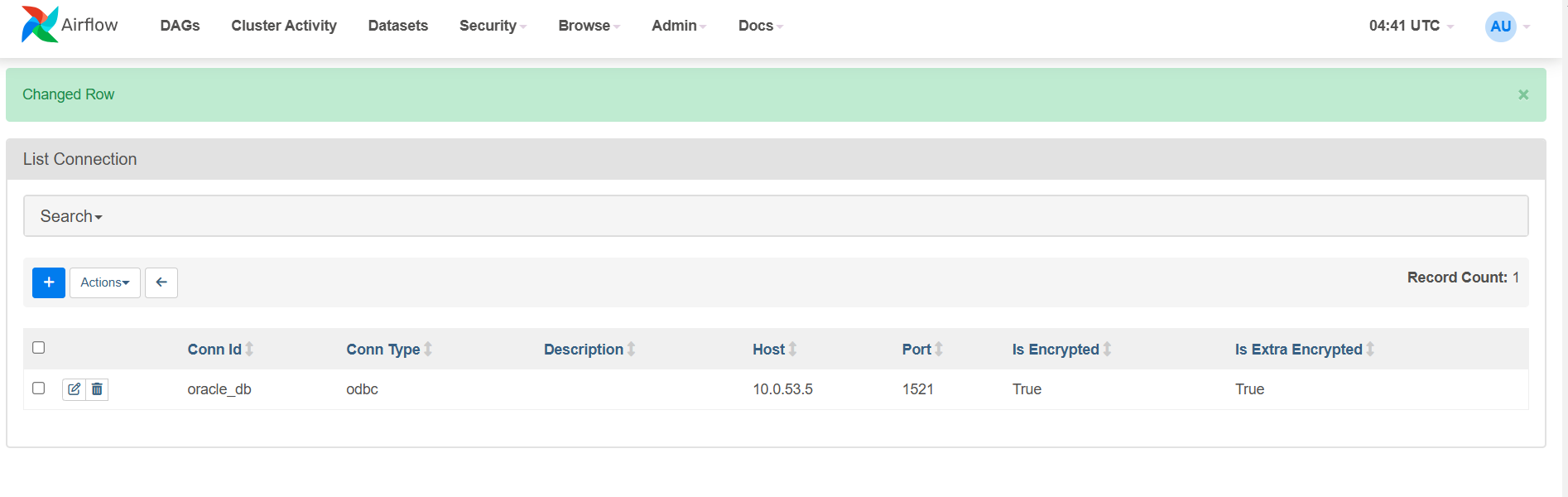
Airflow -> Admin -> Connection에 들어가서 밑의 + 버튼을 클릭해서 Oracle DB에 대한 내용을 추가합니다. Oracle DB에 접속을 위해서는 `dsn` 내용이 필요함으로 Extra 필드에 DB에 해당하는 내용들을 적어주어야합니다.
{
"dsn": "(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=[DB HOST])(PORT=1521))(CONNECT_DATA=(SERVICE_NAME=[SERVICE NAME])))"
}- 해당 DB에 맞게 HOST, PORT, SERVICE NAME의 내용들을 채워주고 변경한 후, Save 버튼을 클릭해서 저장하면 됩니다.
{
"dsn": "(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=[DB HOST])(PORT=1521))(CONNECT_DATA=(SERVICE_NAME=[SERVICE NAME])))",
"mode": "sysdba"
}- sys의 계정으로 사용하는 경우에는, mode 부분을 추가해서 명시해주어야 합니다.
1-5-2. DAG에서 불러오기(Oracle Hook)
from airflow.providers.oracle.hooks.oracle import OracleHook
import oracledb
# thick mode
oracledb.init_oracle_client(lib_dir="/mnt/data/airflow/python-packages/oracle")
hook = OracleHook(oracle_conn_id="[ORACLE_CONNECTION_NAME]")
conn = hook.get_conn()
cursor = conn.cursor()- 1-4-2. DPI-1047 에러에서 작성했듯이, 현재 저의 DB는 Thick mode를 사용함으로 DAG에도 Thick mode를 불러오는 것으로 작성되어있으니, 필요하지 않으시다면 빼고 적용하시면 됩니다.
- `oracle_conn_id`에는 Connection 생성 시, 지정했던 이름을 적고 connect을 진행하면 추가적으로 DAG안에서 DB의 대한 정보를 작성하지 않고도 잘 실행되는 것을 확인할 수 있습니다.
1-5-3. DAG에서 불러오기(Base Hook)
Oracle Hook이 한 줄로 정의되어서 쉽지만, BaseHook의 경우에는 전체적인 내용들을 다 가져와서 하나씩 지정해서 사용할 수 있습니다.
from airflow.hooks.base_hook import BaseHook
import oracledb
oracledb.init_oracle_client(lib_dir="/mnt/data/airflow/python-packages/oracle")
db_info = BaseHook.get_connection("[ORACLE_CONNECTION_NAME]")
con = oracledb.connect(
user=db_info.login,
password=db_info.password,
dsn=f"{db_info.host}:{db_info.port}/{db_info.schema}",
)
cursor = con.cursor()- BaseHook으로 DB 정보를 가져와서 user, password 이런식으로 하나씩 지정해서 사용할 수 있다는 점이 있음으로 Oralce Hook과 비교해서 원하시는 방법을 택하셔서 사용하면 됩니다.
2. Kafka Connection 설치 및 설정하기
2-1. Kafka 설치하기
Kafka Connection은 Oracle Connection 보다는 쉽게 진행할 수 있습니다. Oracle Connection에서 한 것과 동일하게 파드안에 들어가서 venv를 활성화한 후에, PV에 패키지를 설치하면 됩니다.
kubectl exec -it airflow-worker-0 -n airflow -- /bin/bash
kubectl exec -it [POD 이름] -n airflow -- /bin/bash- 현재는 worker 파드에 들어가서 진행했지만, PV로 연결된 webserver, worker, scheduler, triggerer 중에 어느 파드에 들어가서 진행해도 괜찮습니다.
pip install apache-airflow-providers-apache-kafka
pip install kafka-pyhton- apache-airflow-providers-apache-kafka, kafka-python 패키지를 설치합니다.
helm upgrade --install airflow apache-airflow/airflow -n airflow -f airflow_values.yaml --debug- 각 파드에 잘 설정될 수 있도록 helm upgrde를 이용해서 업데이트를 진행하면 됩니다.
2-2. Kafka Hook 사용하기
2-2-1. Connection에 등록하기

Airflow -> Admin -> Connection에 들어가서 밑의 + 버튼을 클릭해서 Kafka 에 대한 내용을 추가합니다. Kafka Connection은 Config Dict에 추가적인 내용을 작성해줍니다.
{
"bootstrap.servers": "[BOOTSTRAP SERVER]",
"group.id": "[GROUP ID]",
"client.id": "[CLIENT ID]",
"auto.offset.reset": "[OFFSET MODE]"
}- Kafka에 맞는 boostrap server, group.id, client.id, auto.offset.reset 등의 내용을 적어줍니다.
- auto.offset.reset의 경우에는, earlist, latest로 나누어지면 offset을 어느 시점으로부터 가져올지에 대해서 지정해줍니다. earlist의 경우에는 처음부터 가져오고 latest의 경우에는 연결된 시점부터 가져오게 됩니다.
- group.id와 client.id는 따로 정한 것이 없더라도 현재 지정해서 사용하면 알아서 consumer로 접속하게 되면서 생성되게 됩니다.
2-2-2. DAG에서 불러오기(Base Hook)
Kafka Hook을 사용하려하였으나, consumer를 연결하는 부분에서 설정 등 보다 Base Hook으로 가져와서 설정하는 옵션이 더 많음으로 이를 사용하였습니다.
from airflow.hooks.base_hook import BaseHook
from kafka import KafkaConsumer
import json
kafka_config = json.loads(BaseHook.get_connection([KAFKA_CONNECTION_NAME]).extra)
consumer = KafkaConsumer(
topic_name,
bootstrap_servers=kafka_config["bootstrap.servers"],
group_id=kafka_config["group.id"],
auto_offset_reset=kafka_config["auto.offset.reset"],
enable_auto_commit=True,
value_deserializer=lambda x: json.loads(x.decode("utf-8")),
)- 등록했던 Connction의 이름을 KAFKA_CONNECTION_NAME에 적어서 Base Hook을 이용해서 DB 정보를 가져옵니다.
- 해당 DB 정보를 이용하여서 Consumer에 연결해서 해당 Consumer에 있는 message들을 가져와서 처리할 수 있게 됩니다.
이렇게 Airflow Connection을 이용해서 Oralce과 Kafka를 설치, 적용하고 이를 DAG에서도 사용하는거까지 확인해보았습니다. Airflow를 처음 써보는 단계이다보니 Connection도 설치해야한다는것과 이를 각 파드에 적용해야한다는 부분들이 조금 막막했었지만, 이전에 PV를 설정해놓은 덕분에 조금 수월하게 진행할 수 있었습니다. Connection을 사용하면 암호화되서 DB 정보를 관리할 수 있고, 이를 DAG에서도 불러와서 중요한 정보가 노출되지 않고, Connection에 들어가보면 저장하기 전에 Test 버튼을 통해서 미리 연결이 되는지도 확인할 수 있으니 사용하면 좋은 기능같습니다. Airflow를 사용하게 되신다면 같이 따라하시면서 사용해보시면 좋을 것 같습니다. 다음에도 더 유익한 정보를 가지고 돌아오겠습니다!🥸🥸
'챱챱' 카테고리의 다른 글
| [Kubernetes] RBAC 설정 알아보기 (0) | 2025.03.30 |
|---|---|
| [Ora2Pg] Ora2Pg 설치 및 실행하기 (0) | 2025.02.16 |
| [Airflow] Kubernetes에서 Airflow 설치하기 (0) | 2025.02.02 |
| [서평] 데이터 엔지니어를 위한 97가지 조언 (1) | 2025.01.05 |
| [챱챱] ML엔지니어 -> 데이터 엔지니어로 Change (0) | 2024.11.24 |



